在介紹完 Ivy Bridge 之後,接下來這個世代也是目前許多人正在使用的 (畢竟因為中間的一些插曲,這跟目前最新款的處理器對大多數人來說其實只差一代而已,原因後述),本篇要看的就是在 2013 年以「第四代 Intel Core 處理器家族」名義推出的 Intel Haswell 架構處理器。

Intel Haswell 架構
2013 年在 Intel 奉行的 Tick-tock 時程上又輪到「Tock」的一年,也就是架構更新的一代,一般而言我們可以預期在「Tock 的一年」會出現比較大的變革,而「Tick 的一年」通常只會在製程上做文章,不過或許是製程提升越來越困難了吧?所以這樣的規律其實從 Ivy Bridge 開始就亂了 (Ivy Bridge 對架構的改動程度其實跟 Haswell 差不了多少),同時 Haswell 也是最後一代還稱得上遵循 Tick-tock 時程規劃的產品,之後基本上兩年一輪已經變成不可能的理想。
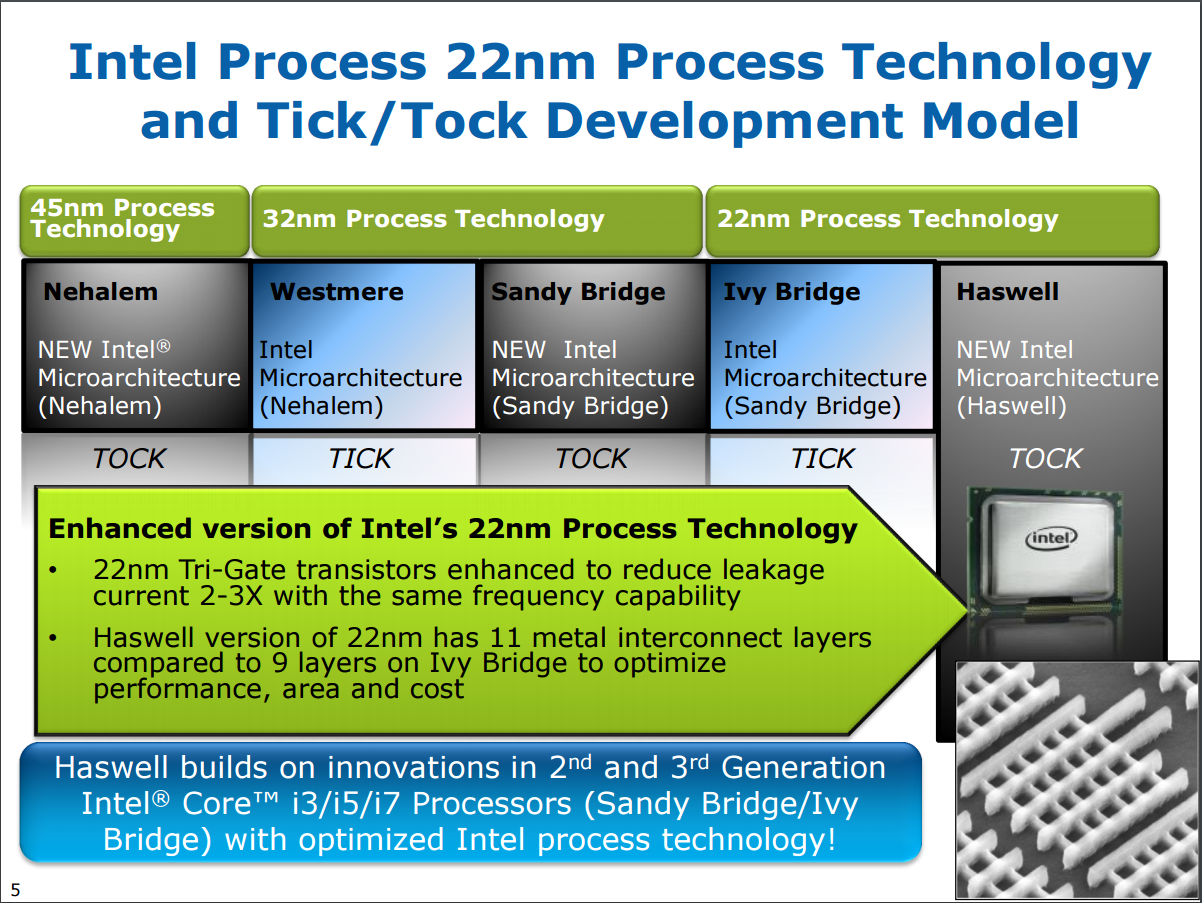
雖然說時序輪到 Tock 的主題會是架構更新,但其實 Intel 往往在 Tock 也會對製程做一些改進,雖然不會改變奈米尺度,但會作一些可以提升良率或效率的改進,例如這次 Intel 就強調 Haswell 內部的金屬連接層有 11 層 (IVB 只有九層),可以提高性能,降低晶片的面積 (當然也就降低成本)、3D 立體三閘極電晶體也在此代更臻於成熟,此外,Haswell 世代的研發領導又再次從以色列海法團隊轉回奧瑞岡州團隊。
性能改進困難,轉往節能發展

從 Haswell 開始就可以很明顯發現 Intel 對處理器運算核心本身的改進越來越少了 (或者說花了很多力氣做的改進但實際上性能提升可能只有個位數個百分點),由於性能提升越來越困難,接下來幾代的 Intel 處理器架構有轉往強化節能發展的趨勢 (其實就是 Core 架構當年揭示的「由一味追求性能提升,轉為追求效能比的提升」,雖然某種程度上只是性能已經很難拉上去的藉口啦,不過確實結果論而言是這樣),因此節能是 Haswell 架構的一大重點 (其實從下面這張圖放在架構介紹中很前面的地方就可以略知一二了)。
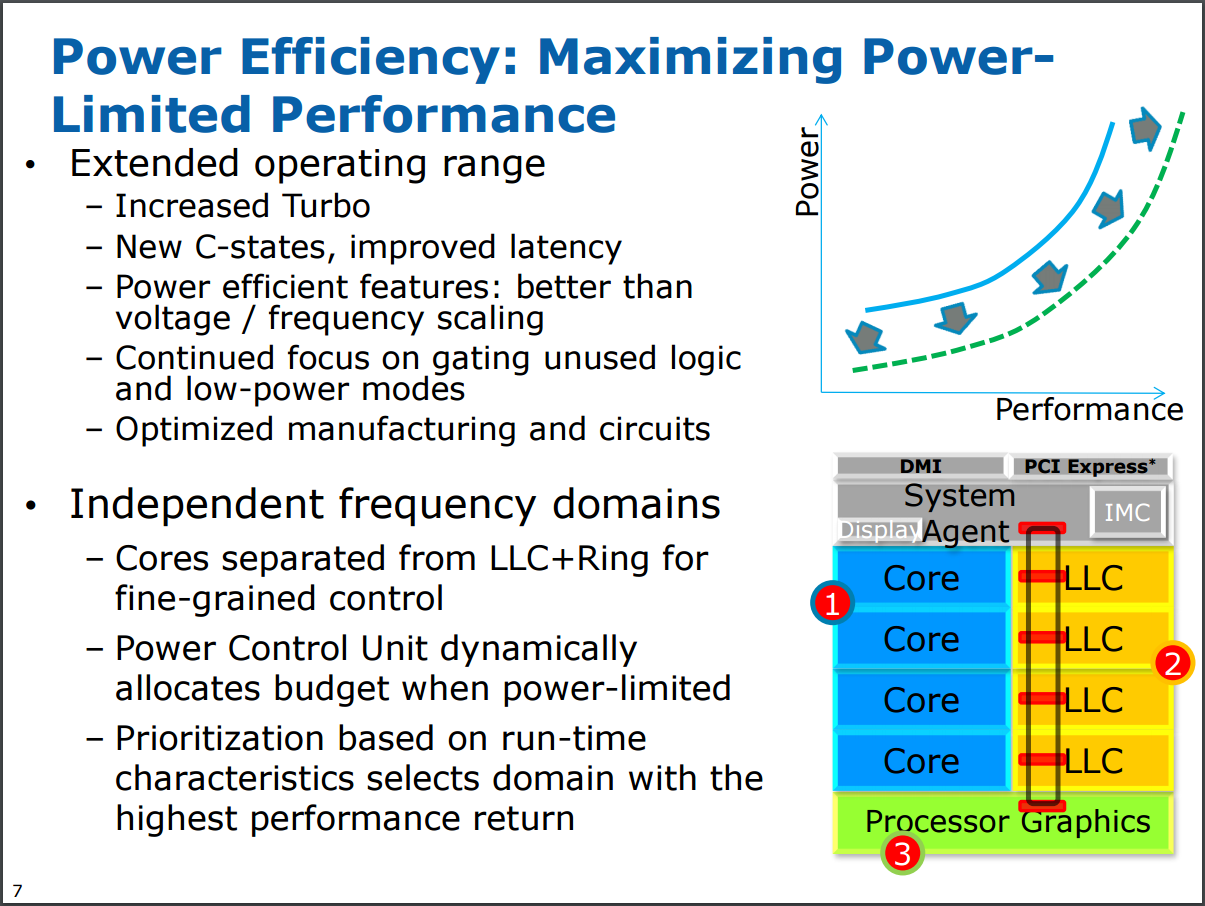
Haswell 在節能方面的設計思維是「盡可能擴大作業模式的範圍」,也就是閒置時的耗電量要被壓得更低 (連帶的,在不需要的時候性能輸出也更低)、滿載時的性能要拉得更高 (連帶的在滿載運作時允許比以前耗用更多電力),並且各模式之間切換的速度要更快,沒有用到的電路應該盡可能被關閉或是提供低耗電模式。
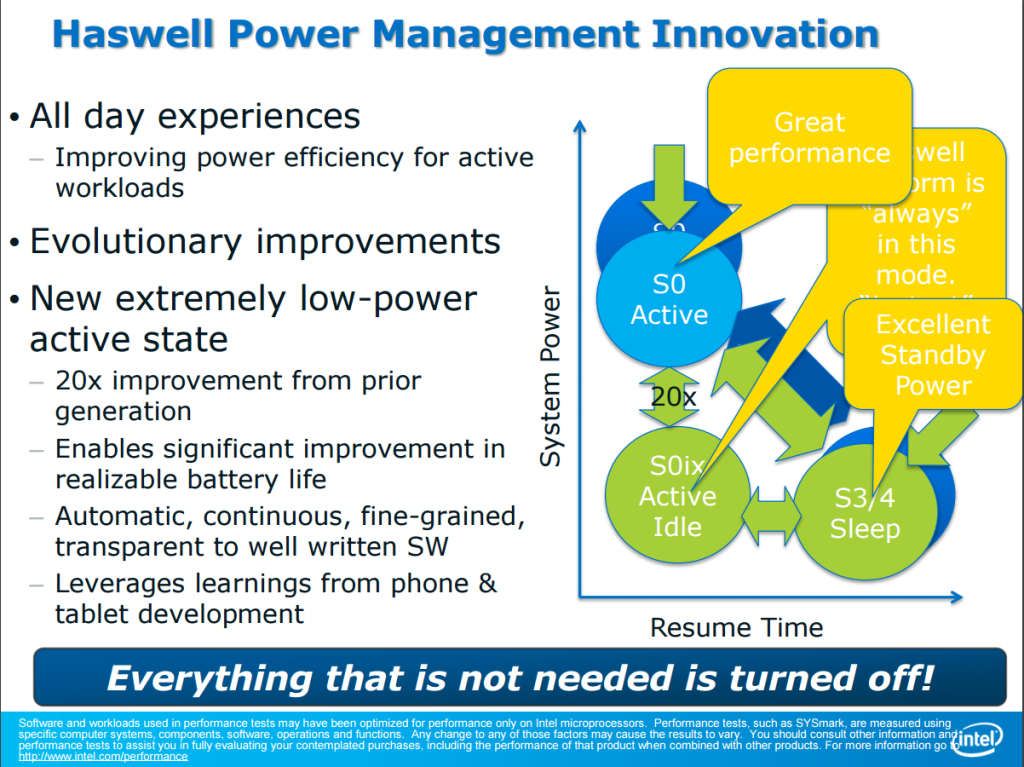

除此之外還有一項特性是與 IVB、SNB 不同的,Haswell 處理器的環狀匯流排、L3 快取的運作時脈是與處理器核心脫鉤的 (為了避免內建顯示要存取快取記憶體時得順便把處理器核心的時脈拉上來,造成額外的耗電,所以 Haswell 處理器片上一共分成三個區域,各自擁有自己的運作時脈,分別是快取與內部連線、運算核心與內建顯示),並且在電源受限的時候,電源管理單元會進行動態分配。
核心架構上的改進 (真的不多)
Intel 在談及 Haswell 核心架構改進時,顯得比過去 IVB、SNB 都還要籠統許多,架構的部分與 Ivy Bridge 基本上是相同的,但再次針對分支預測進行提升,並優化了前端的性能 (更大的亂序執行結構、指令讀取頻寬,除此之外指令發射埠也從六個增加到八個),L2 快取的 TLB 也有增大,但是運算管線的「結構」就幾乎沒有任何改變了 (當然強化也是有啦,畢竟加了一個「很大組」的新指令集呢)。
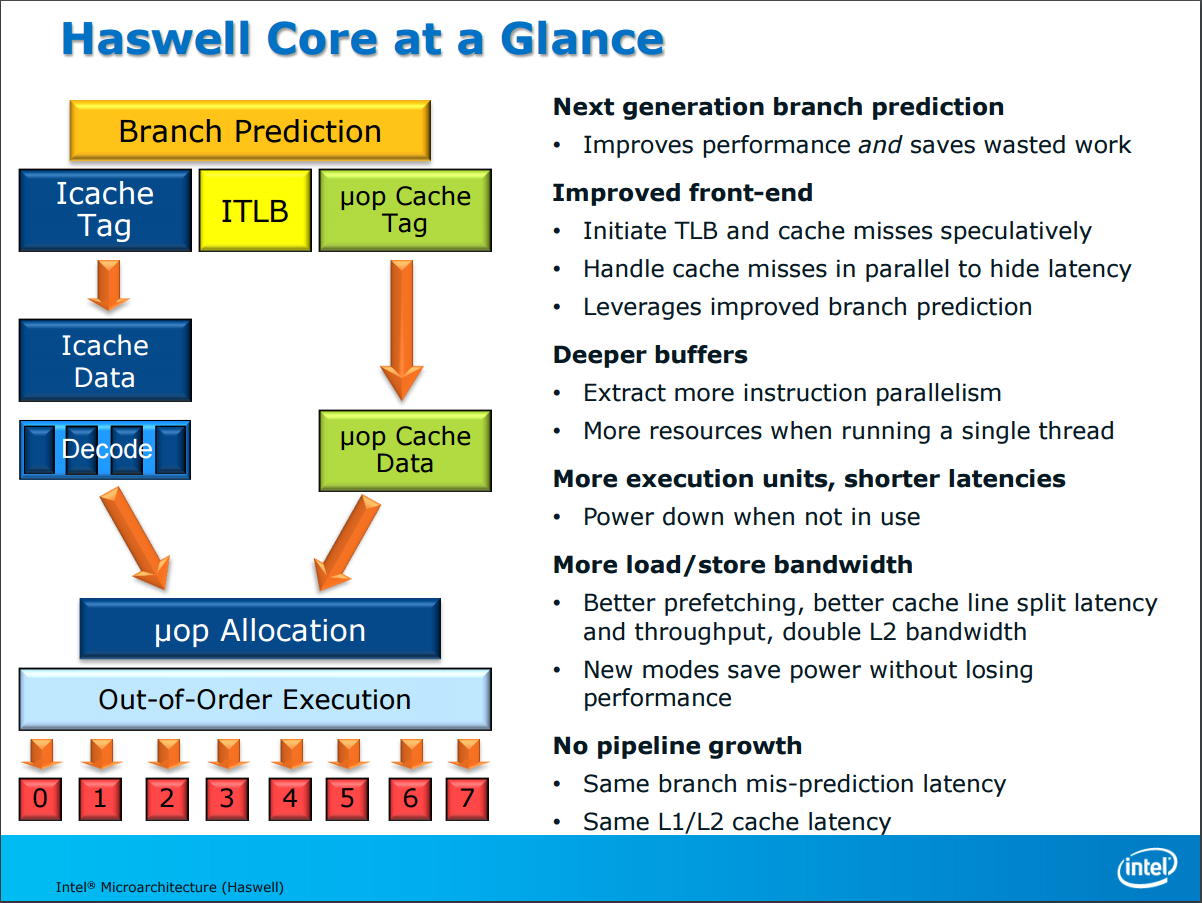
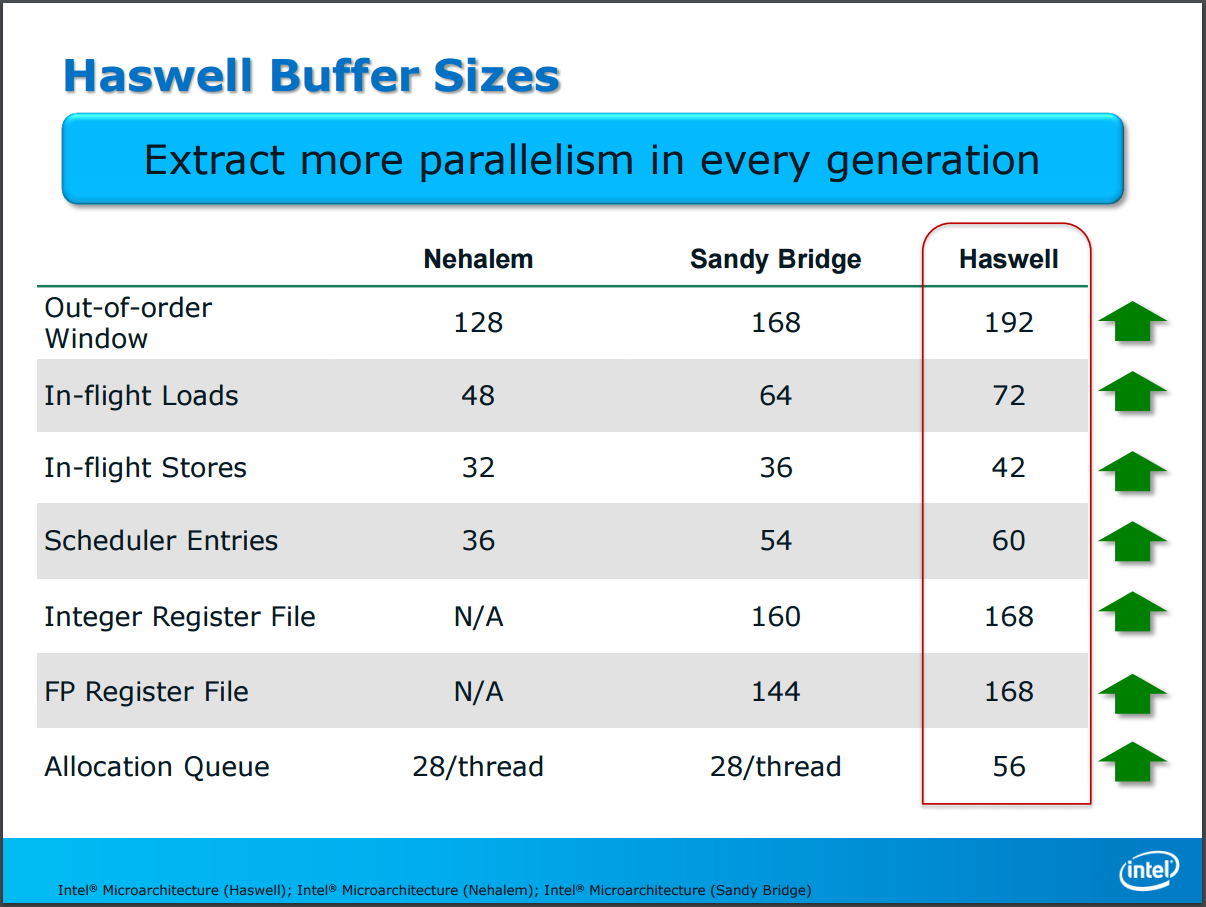
除此之外 Haswell 的各類緩衝區基本上大小都有成長 (說起來在 SNB 時代 Intel 是沒有特別提這個的,或許是 HSW 真的沒有太多新特色吧?)
AVX2 指令集
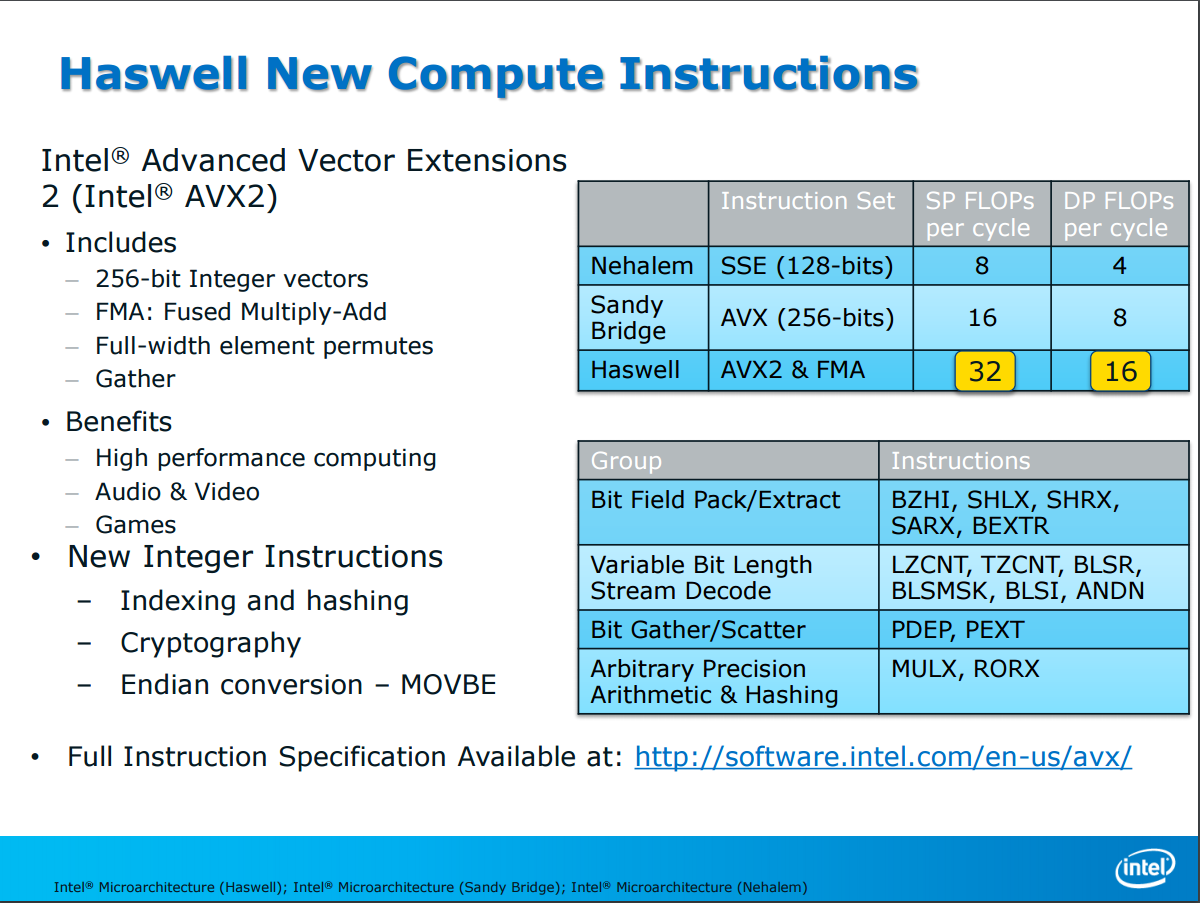
AVX2 指令集算是 Haswell 架構最主要的新特色之一,發佈之前也曾經被稱為 HSW-NI (Haswell New Instruction Set),透過新增 60 條 256-bit 浮點 SIMD 指令與增加兩組 FMA3 融合乘加單元 (Fused Multiply-Add,負責狀似 ±(a×b)±c 的計算操作,值得注意的是不同於 AMD 主推的 FMA4 採用四運算子,Intel 陣營的 FMA3 是三運算子的) 來讓每時脈週期處理器核心可以處理的 FLOPs (浮點數操作) 提高到兩倍 (SNB 時期是 16 個單精度、8 個雙精度,HSW 直接拉高到 32 個單精度、16 個雙精度),並且將 AVX 拓展到整數向量上,能夠支援 256-bit 的整數 SIMD (以往只支援到 128-bit),適用範圍變得更廣。
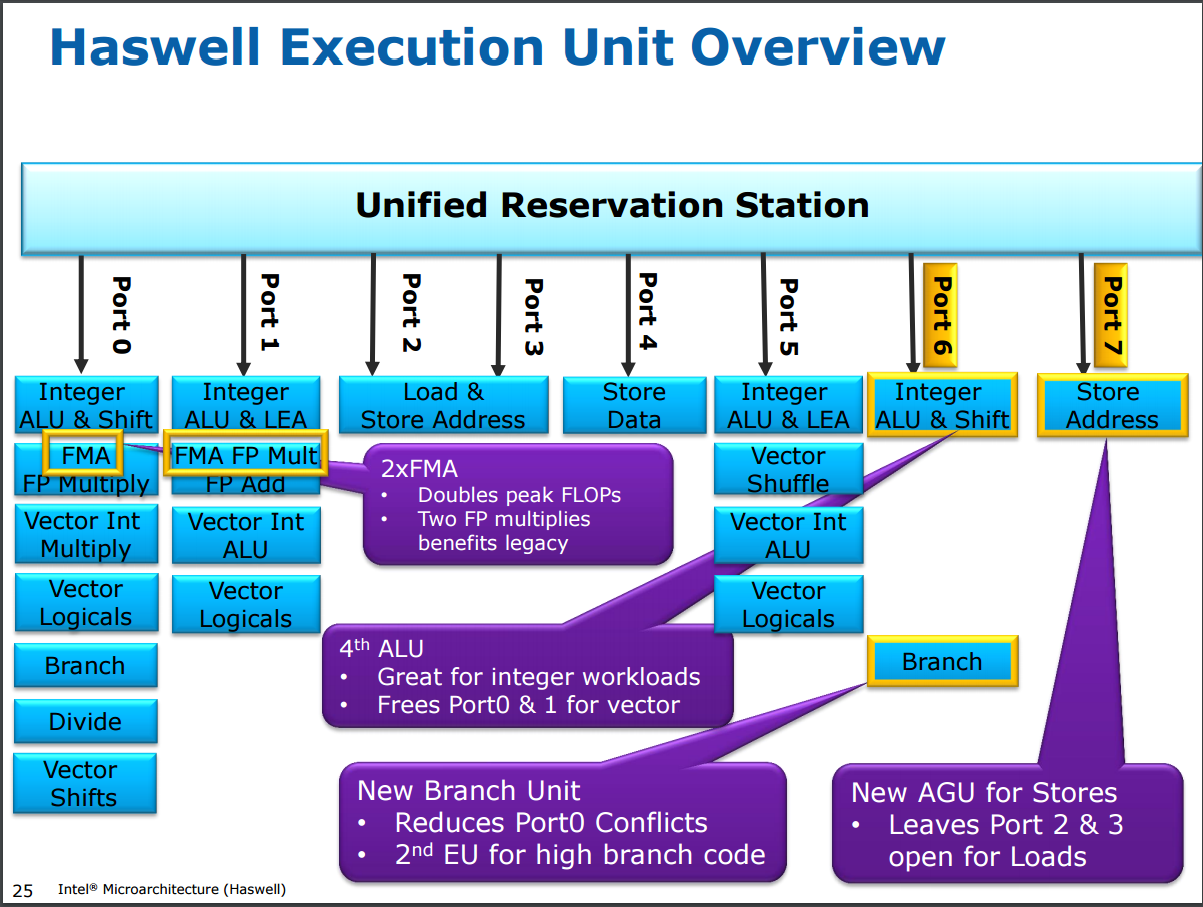
下圖顯示的就是 Haswell 的運算單元架構圖,可以看到新增的兩個指令發射埠 (Port 6 用於分攤原本 Port 1 與 Port 2 的工作、Port 7 用於分攤原本 Port 2 與 Port 3 儲存位置的任務) 以及新增的兩組融合乘加單元。
悲劇的 TSX-NI 指令集
TSX-NI 指令集幾乎可以說從頭到尾就是個悲劇,首先因為名字太難翻譯所以很少人記得 (事務性同步擴展指令集)、做的事情很難解釋 (只能說他跟解決多執行緒、多核心之間的鎖定、同步問題有關,透過硬體層面對這個問題進行改善,讓軟體工程師能夠更容易解決或是降低這個問題帶來的影響)、一般人沒有感覺 (因為主要是跟軟體工程師比較有關) 所以根本沒多少人認識它。

沒人認識與記得已經很悲劇了,但更悲劇的是這個指令集在 Haswell 架構處理器當中是有缺陷的,甚至 Broadwell 也無法倖免,Intel 官方透過更新微碼禁用 TSX-NI 指令集來解決,結果最後有一部分人記得這東西的原因居然反而是因為 Intel 在 Haswell 中做壞了,夠悲劇吧。 XD

其實我個人的感覺是 Intel 官方並不是真心想推這個指令集,因為這指令集需要依賴軟體支援的成分很大,但在 Haswell 的 K 版不鎖頻處理器與高端 HEDT 市場的 Haswell-E 都是全線不支援的,面向伺服器的 Haswell-EP 也有一堆型號不支援,後來 Intel 也很少再提起這個指令集,當能使用的人數少,它成為軟體工程師採用方案的機率就很低,因為通常而言開發軟體當然是希望越多人能夠使用越好。
快取架構不變,但性能改良
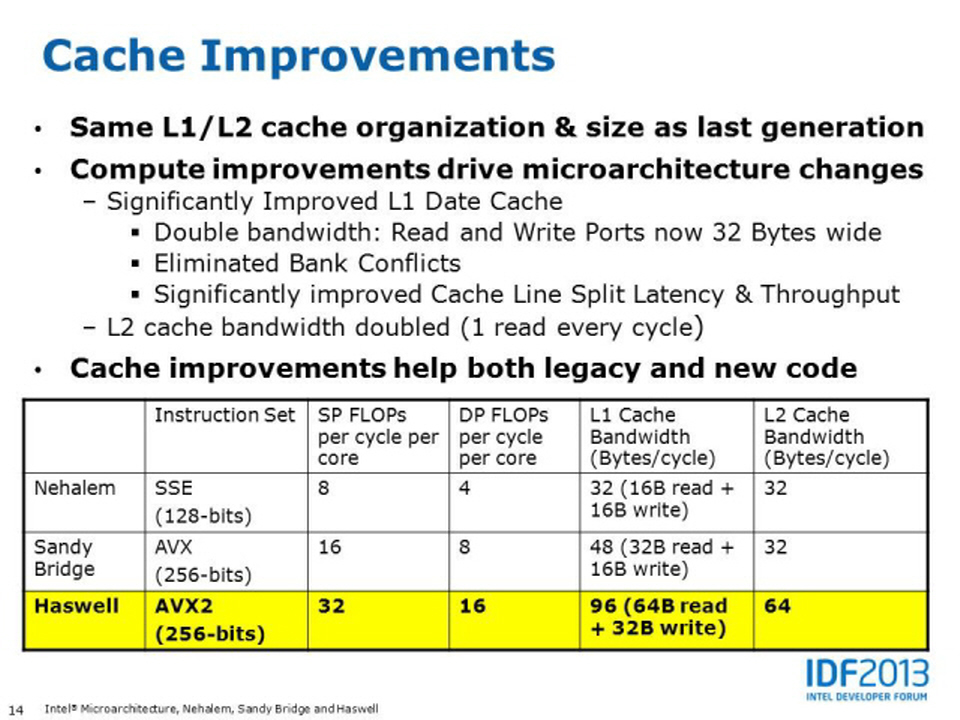

Haswell 的快取階層設計依然延續 SNB、IVB 那一套,但 Haswell 的快取性能有很明顯的增長,L1 資料快取與 L2 快取頻寬紛紛加倍,使用 AIDA64 的快取記憶體測試就可以很明顯感受到數字上的增長,快取速度提高當然對降低延遲與提高性能有很大的幫助,特別是在 AVX2 指令集納入之後,為了處理變寬兩倍的向量單元,對快取頻寬的需求也就更高了。
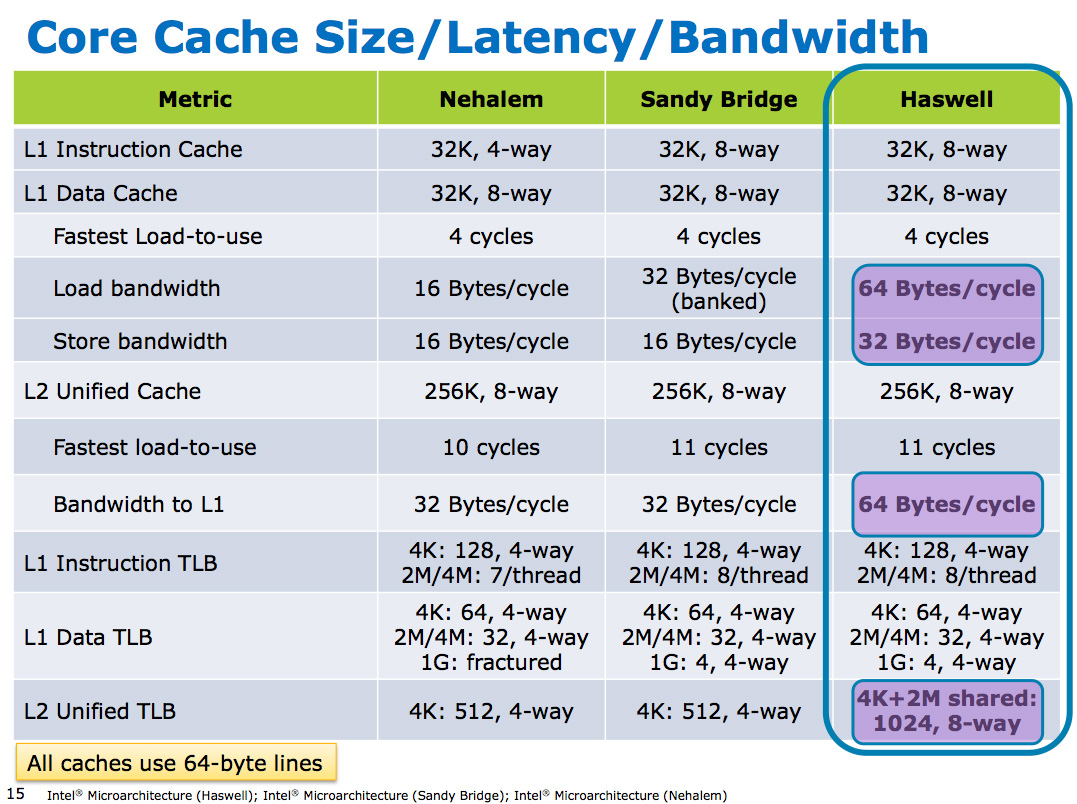
供電設計大改變,FIVR 設計
FIVR 的全名是 Fully Integrated Voltage Regulator,中文是整合式調壓模組,顧名思義是用來調整電壓用的,以往調壓是主機板上的電路負責的 (電源供應器輸出的電壓只有 5V、3.3V、12V 幾種而已,到主機板上會需要降壓處理才能用於供給處理器上的不同部分),傳統設計的 IMVP (Intel Mobile Voltage Positioning) 架構 (下圖左) 需要從主機板上拉出 Core VR、圖形 VR、PLL VR、I/O VR、System Agent VR、記憶體 VR 等六組不同的電壓供給給處理器,也因為這樣所以當時主機板有段時間打過所謂的「相位大戰」,各家高階主機板瘋狂堆相位,有 16 相甚至 32 相者出現。
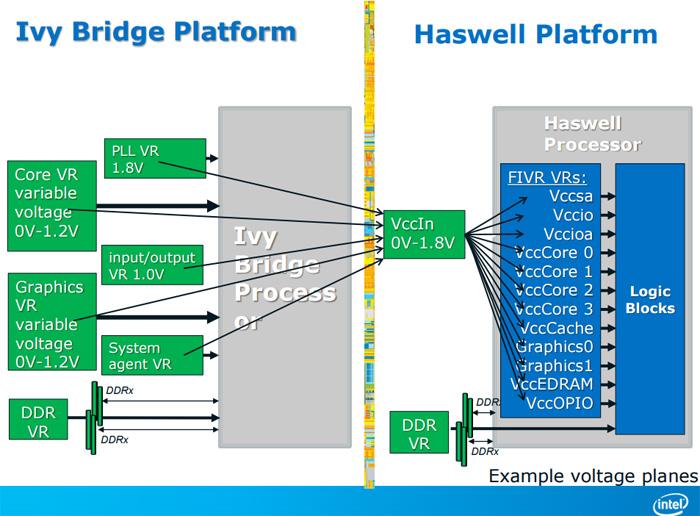
而 Haswell 的 FIVR 設計顧名思義就是把「調壓」這件事情納入處理器本身了,所以主機板只需要供給處理器單一一種電壓 (VccIn) 就可以,這樣的做法有利有弊,而且各自都很鮮明,有利的地方是處理器直接控管電壓調整,可以很大程度避免劣質主機板或調壓電路發生損壞的情形,而且由於距離與中間經過的關卡變少的緣故,效率「理論上」也得以提升,主機板的電路也可以更加簡化,處理器本身也可以「更全面的」主控供電狀況,這對提高能耗效率是有幫助的,
但缺點也很顯而易見,因為調壓模組本來就是很會發熱的東西,把這東西整合到本來散熱問題就已經很大的處理器中帶來的直接影響當然就是發熱量的增加與散熱上的困難,這樣一來一往抵銷後帶來的節能效果還在不在其實很難講,甚至有可能效率會比傳統設計還要更糟,除此之外由於相位是主機板廠商用來區分高低階產品的重要項目之一,但採用 FIVR 設計之後主機板設計太多相數的供電就變成完全只是浪費而已 (相數其實不是越高越好,太少會造成不穩定,但太多則會造成額外的耗能與零件的浪費並佔去大量面積)。
電路布局沒有甚麼改變
從 Sandy Bridge 開始使用的電路排列方式到 Haswell 世代也依舊延續,但雖然排列沒有變化,還是可以從中看到內建顯示佔據處理器晶片的比例越來越大這個趨勢,也確實 Haswell 上面性能突破最多的地方並不是處理器本身,而是強化的內建顯示,然後較大的內建顯示單元正好把 IVB/SNB 上太大的 dead area 給用掉了一半。
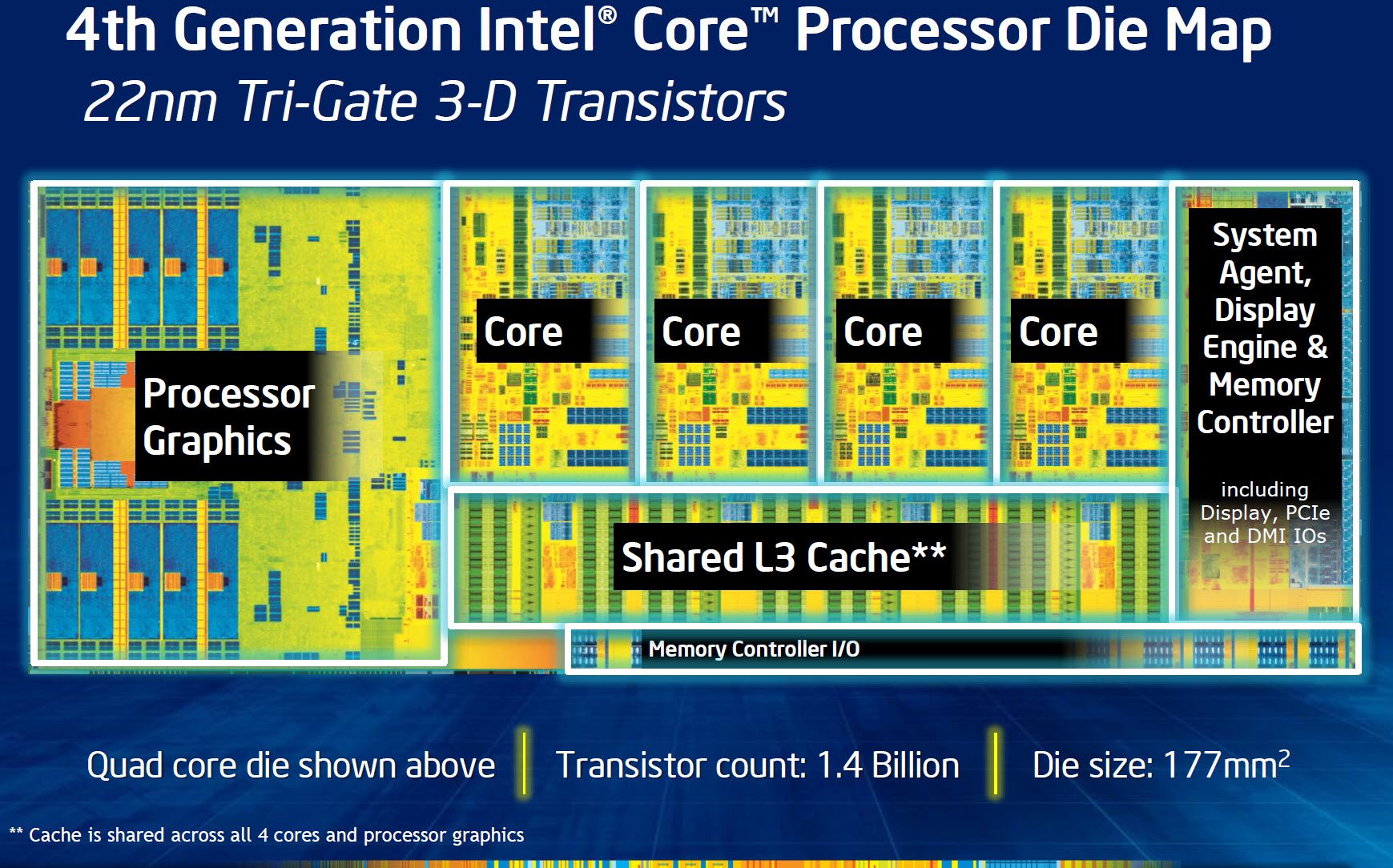
腳位又換了、依然使用 TIM
既然 Haswell 是 Tick-tock 中的 Tock,腳位當然照例是與前代 IVB/SNB 不相容的,Haswell 使用的是 LGA1150 (Socket H3) 插槽,並且需要搭配新的晶片組使用。
除此之外 Ivy Bridge 受到大家詬病的 TIM 散熱介質 (樹脂) 在 Haswell 中依然得到沿用,並沒有因為被罵而改回使用無助焊劑焊接,因此 Haswell 時代開蓋風潮依舊,但高階的 Haswell-E/EP 則仍然使用無助焊劑焊接技術,因此 Intel 選用 TIM 是為了節省成本的意圖很明顯了。
權宜之計:Haswell Refresh
由於 Haswell 架構的下一世代,Broadwell 在製程改進時遇到很大的困難因此不斷延遲,所以 Intel 就在 2014 年五月推出了代號為 Haswell Refresh 的更新版本。

Haswell Refresh 的型號命名方式與 Haswell 很接近,Core 家族的話是型號末碼 +20,Xeon E3 系列的話則是型號數字部分末碼 +1,從型號改變如此之小想必不難猜測其實沒甚麼改變吧?其實唯一的改變就是時脈微幅上升而已。
基本上 Haswell Refresh 的出現與其意義完全就是市場策略而已,為了延續已經上市超過一年的 Haswell 的熱度與動能,所以特別「重走一次發佈流程」想帶起話題,除此之外還特別把 K 版不鎖頻的 Haswell Refresh 處理器起了個 Devil’s Canyon 的代號跟搞了一個 Pentium 20 周年限定版 (G3258)。

Intel 官方是宣稱 Devil’s Canyon 的兩顆處理器的背面電容器有重新安排過,供電上效率與穩定度都會比較好,而且 IHS 裡面的 TIM 導熱材料也與其他型號不同 (但 TIM 仍然是 TIM 啊 XD)。
Haswell-EP 與 Haswell-E 架構
一如過去幾代的作法,Haswell 架構家族依然有後續的完整版 Haswell-EN/EP/E,同時也如同 Ivy Bridge 家族般推出了最高級的老大哥 Haswell-EX,但由於一般人是不太有機會碰到 Haswell-EX 與 Haswell-EN 的,所以本篇也就不打算談了。
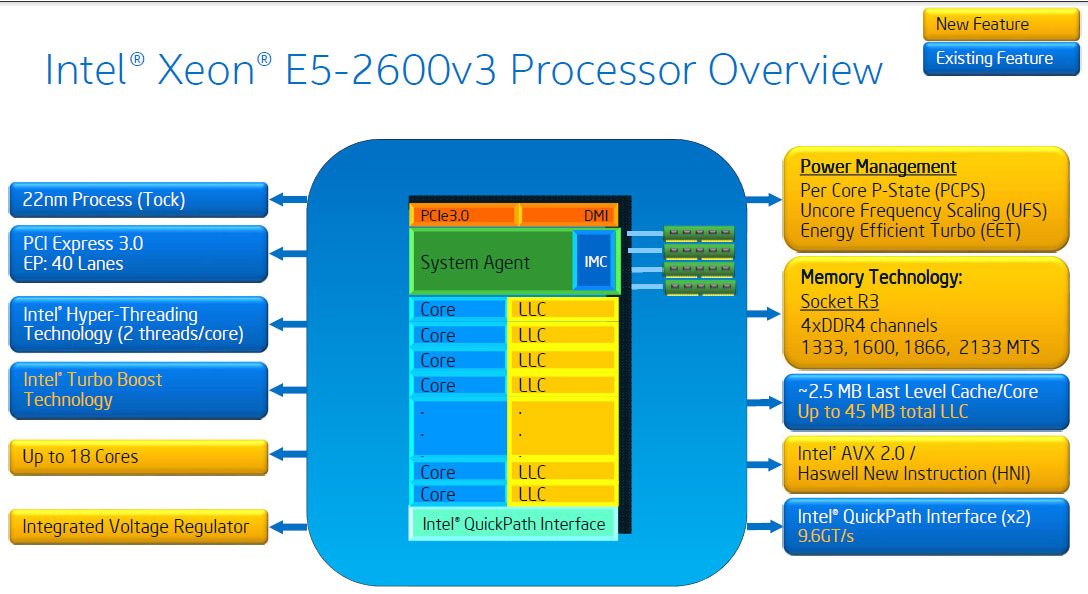
Haswell-EP:面向中高階伺服器市場
Haswell-EP 在 Haswell 推出後的隔年,也就是 2014 年才以 Intel Xeon E5 v3 家族的名義推出,最鮮明的特色主要有四個,依序是大增的核心數 (最多可以高達 18 核心)、大增的 L3 快取 (最大可以來到 45 MB,與前代一樣是跟處理器核心切齊的結果,所以核心數大漲快取也就跟著大增了)、採用四通道 DDR4 記憶體 (根據型號不同支援的速度也不同,最高到 2133 MT/s)、更快的 QPI 連線 (根據型號不同,最高從前代的 8.0 GT/s 提高到 9.6 GT/s)。
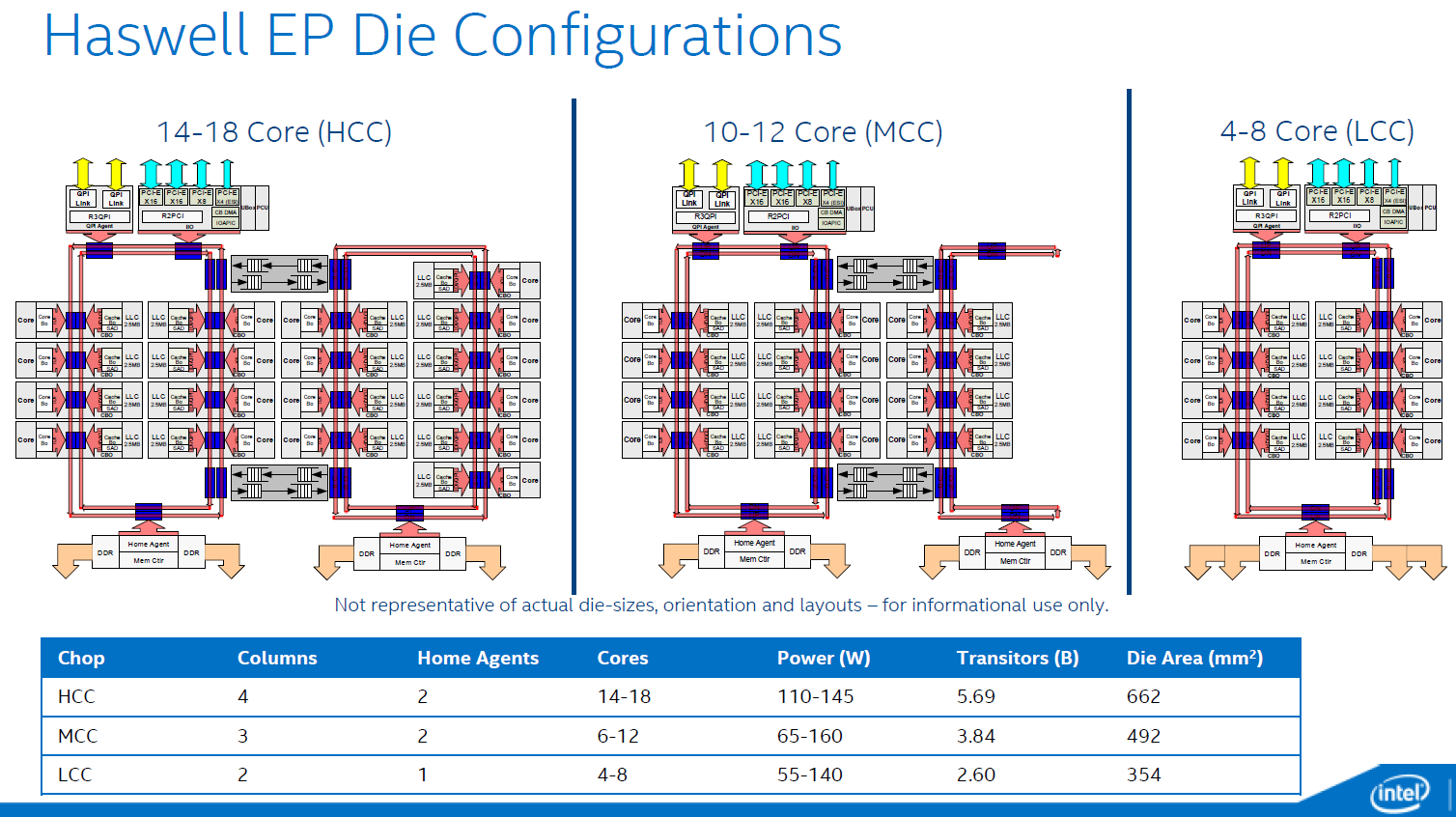
而 Haswell-EP 也跟前代一樣分成三種 Layout,但核心數量都大幅增加了,高配置 (HCC) 是 14 ~ 18 核心 (有兩套四組環型匯流排與兩組記憶體控制器),中配置 (MCC) 是 10 ~ 12 核心 (有兩套三組環型匯流排與兩組記憶體控制器),低配置 (LCC) 則是 4~8 核心 (僅有一套兩組環型匯流排跟一組記憶體控制器)。
不過呢 Haswell-EP 最主要的升級同樣不是出現在處理器本身,而其實是在於晶片組的部分,因為 C600 / X79 晶片組前後已經撐了將近三年了,在 Ivy Bridge E/EP 推出時,Haswell 也正好同步推出,當時就發生了高階 HEDT 平台與中高階伺服器的擴充性竟然不如主流與入門平台的尷尬情況 (當時 C600/X79 原生只有兩組 SATA 6Gbps,也不支援 USB 3.0),而到了 Haswell-EP 搭配的 C610 / X99 晶片組才終於補上相關的擴充能力。

此外,Haswell-E/EP 跟 Haswell 一樣,腳位也跟前代的 Ivy Bridge-E/EP 不同了,雖然仍然是 LGA2011,但底下的觸點分布跟定義都完全不同了,新的腳位稱為 LGA2011-3 (Socket R3)。

(上圖取自 Tom’s Hardware)
Table of Contents
Haswell-E:面向高階電腦玩家 HEDT 平台
依循前面訂下的慣例,所以 Haswell-E 是以第五代 Core i7 處理器的名義推出,推出時間在 2014 年的九月初,但由於 Broadwell 難產,所以搞到最後第五代 Core 處理器家族反而是 HEDT 平台先出了 (第四代的 HEDT Ivy Bridge-E 推出於 2013 年九月,Haswell 則推出於 2013 年六月,至於 Broadwell 呢?2015 年的事情了)。

不知道是不是因為 Haswell 架構的性能提升不是很明顯的關係,在介紹 Haswell 家族架構的時候 Intel 常常把自家的老產品拿出來鞭屍 XD,這張是把 Intel 旗下第一個掛 Extreme Edition (極致版) 的產品 P4EE 開始一路到現在的 Core i7 Extreme 做對比,號稱這十年內性能足足提升了 40 倍之多。

Haswell-E 的標誌意義其實在於這是 Intel 第一次將八核心處理器帶入個人電腦市場,同時 HEDT 平台也不再有四核心的型號了,讓 HEDT 平台與主流平台的性能差距拉開許多,不過呢,最低階的 5820K 只有 28 條 PCI Express 3.0 通道,似乎是為了跟 5930K 拉開所以故意讓 5820K 的性價比降低而做的設定 (不過結果好像反而造成 5930K 不好賣的反效果?因為如果不玩多顯示卡的話其實 PCI Express 通道 28 條也夠用了,為了 0.1 GHz 花 1.75 倍價錢怎麼想也不值得)。
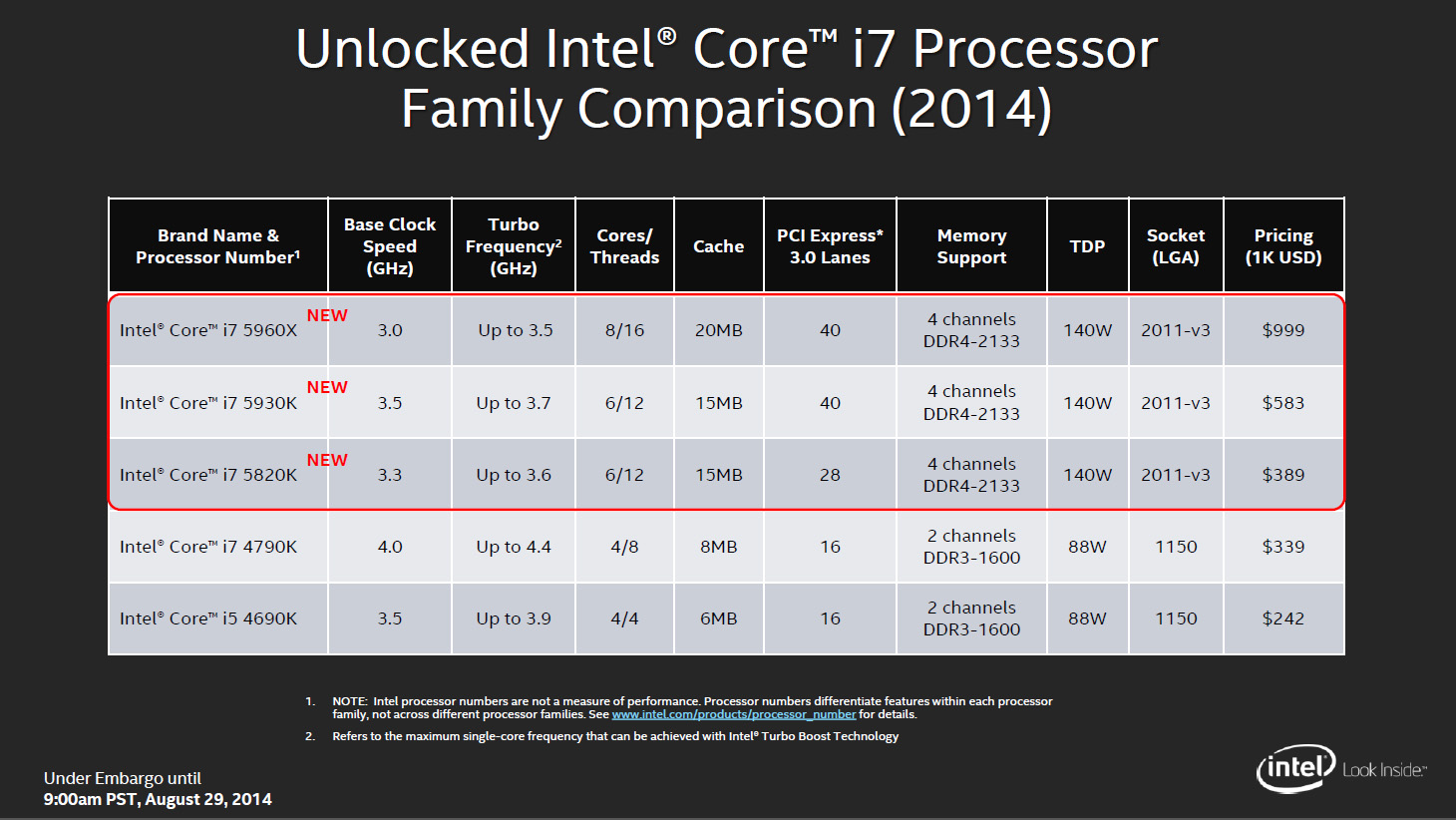
從 Die Map 上也可以很明顯看出 Haswell-E 其實就是 LCC 配置的 Haswell-EP。

製程改進版:Intel Broadwell 架構

Broadwell 架構基本上就是 Haswell 架構移植到 14 奈米工藝的版本,如同介紹 Ivy Bridge 時提過的,製程改進隨著尺度越縮越小,難度也越來越提高,雖然 Ivy Bridge 的時候有很多新的製程技術,看似好像突破了許多困難,但實際上在 Broadwell 架構的時候 Intel 還是踢到鐵板了。
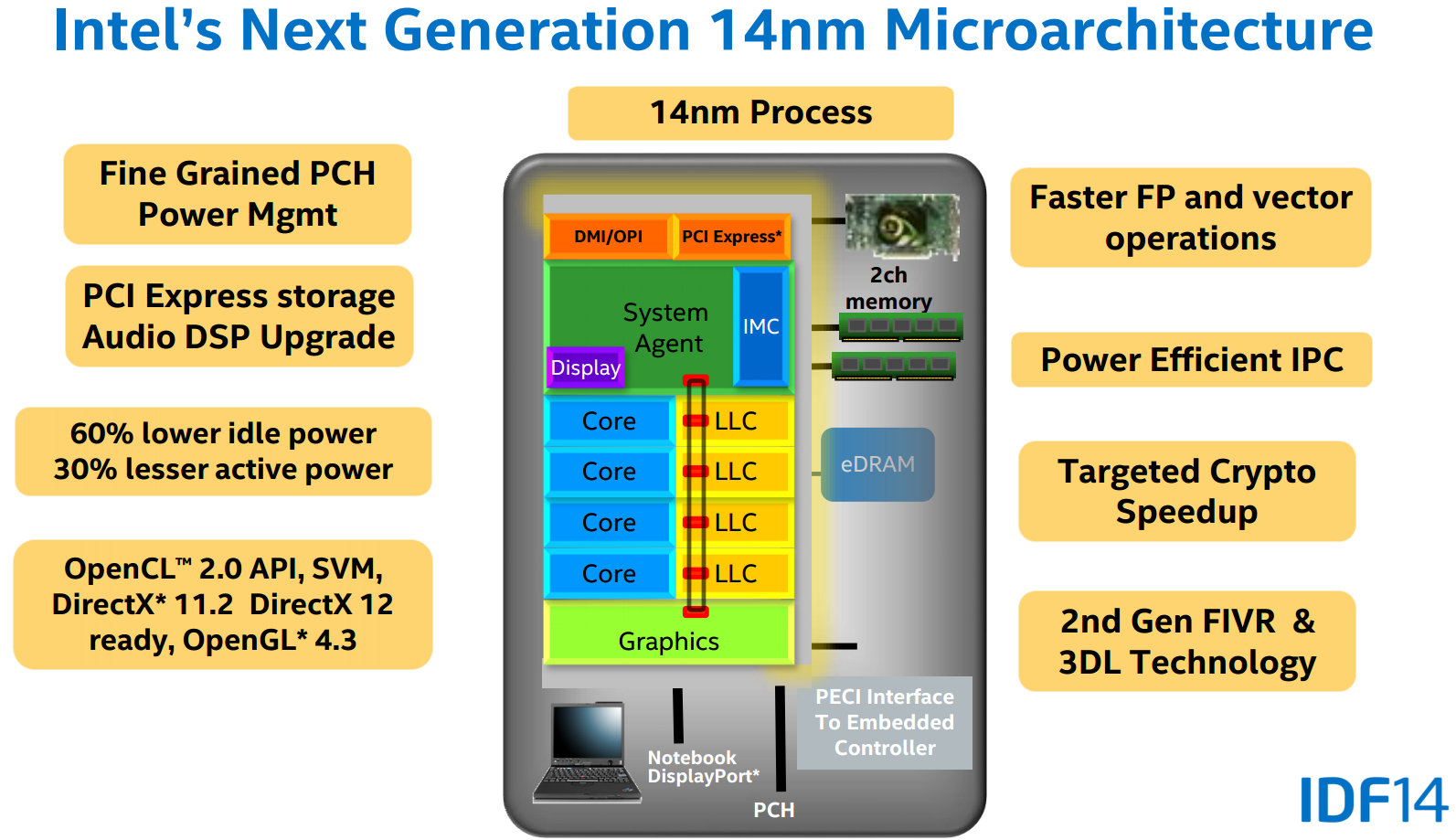
由於推出的時候 (2015 年六月) 距離 Skylake 的發佈只差一、兩個月,因此 Broadwell 上市的型號很少 (且在台灣只有少數店家有進,官方規畫只有五種),以台灣而言能買到的 LGA1150 封裝盒裝版本只有 i7-5775C 跟 i5-5765C 兩款而已,值得注意的是這兩款居然配了 Iris Pro 內建顯示,可說是前無古人,目前也未有來者。
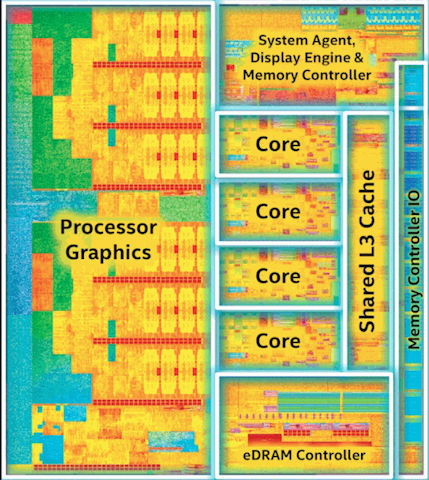
從 Die map 上可以發現 Broadwell-C 的內建顯示單元的大小實在太誇張了,比處理器本體還大了 XD。
第二代 3D 立體三閘極電晶體
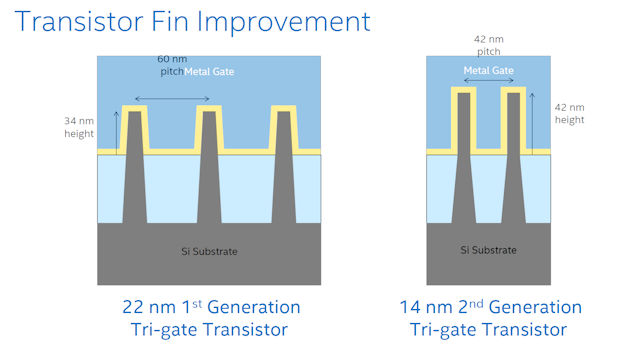
14 奈米製程中所使用的電晶體也獲得了升級,直觀上的差異是「魚鰭」的高度變高、密度也變得更密了,這樣的改變能夠提升性能與降低漏電流。
各類性能都有「微幅」提升
實際上 Broadwell 以 Haswell 作為基礎,在蠻多方面都有性能上的提升 (像是分支預測也又升級了一番),不過因為 Skylake 在不到兩個月後就推出了,自然也就沒甚麼人關注,甚至在官方的 IDF 大會上其實也直接跳過 Broadwell 就介紹 Skylake 了,怎麼說呢,畢竟有更快的東西,第二名就不會有人在意了吧?
至於 Broadwell-E 則還沒上市,等上市之後再補吧 (其實是因為篇幅又爆炸了 XD)