

好的,終於要來到記憶體規格介紹的尾聲啦,本篇要談的是剩下來比較瑣碎的部分,主要有兩項主題,分別是記憶體的功能分類 (其實要說等級也是可以,主要差異在於是否具備某些特性,有這些特性的記憶體通常貴上不少,啥都沒有最低階的就是你我一般電腦使用的那種了) 與記憶體的組成結構 (Rank、Bank 之類的名詞)。
記憶體的功能分類
一般來說我們比較在意的記憶體附加特性有兩項,第一項是錯誤更正能力的有無 (ECC),第二項則是是否具備暫存緩衝的功能 (Registered)。
Non-ECC Unbuffered DIMM

一般個人電腦使用的就是這種記憶體,價格最為低廉,但是既不具備錯誤更正能力,也沒有暫存緩衝的功能,控制器輸出的控制訊號會直接下達給記憶體模組上面的記憶體顆粒晶片,是最為簡單的一種記憶體,要注意的是在絕大多數情況下,一般個人電腦也只能安裝這種記憶體 (以近幾代的 Intel 系統來說,基本上只有 Core i3 處理器是唯一的特例,可以支援 ECC 記憶體,因為 Core i3 有時候也用於中低價位的 NAS 伺服器上)。
從運作速度的角度上來看,由於少掉錯誤驗證與更正的程序與額外經過暫存器帶來的性能損失,因此這類記憶體是性能最高的,但也是出錯機率最高、最不穩定的一種。
ECC Unbuffered DIMM

這類記憶體通常從外觀上可以很明顯的發現,比起 Non-ECC Unbuffered DIMM 來說,多了一顆記憶體顆粒晶片,所以每面的記憶體顆粒晶片數量是基數個而不是一般常見的偶數 (大多是 8 個),而多出來的這顆記憶體顆粒晶片就是用於錯誤更正的用途。
而 ECC 功能的特性也會反映在記憶體通道寬度上,當資料通道本身寬度為 2n bit 時,ECC 功能會需要額外 N+2 個 bits 的錯誤更正用通道寬度,因此常見的 ECC 記憶體的寬度是 72 bit 而非一般 Non-ECC 記憶體的 64 bit 就是這麼來的,一般來說 ECC Unbuffered DIMM 主要用於中低階的伺服器或工作站上。
ECC Registered DIMM

此類記憶體是廣泛用於中高階伺服器中的產品,除了具備與 ECC Unbuffered DIMM 相同的錯誤更正能力之外,還額外加入了暫存器緩衝區的設計,以目前來說在 Intel 的部分只有 Xeon E5 以上的處理器搭配伺服器主機版才能使用這類記憶體。
之所以加入暫存緩衝的設計 (所以中間多了一顆長得不太一樣的晶片),主要目的是因為伺服器系統所使用的記憶體容量通常遠遠超過一般電腦許多 (其實這也是為什麼你目前能看到的 DDR3 UDIMM 只出到單條 8 GB,ECC Registered 版本的 DDR3 RDIMM 卻可以做到單條 16 GB 的原因之一),為了在容量與記憶體插槽數大幅增加的情況下仍然可以維持系統的穩定性,因此才加入了暫存器的設計,當記憶體控制器發出控制訊號與存取位置資訊的時候,記憶體可以先將這些資訊保存在暫存器中,等待資料訊號來到時再一起送至記憶體顆粒晶片內,除此之外在記憶體顆粒之間還設計有 PLL (鎖相環,Phase-Locked Loop),利用回饋控制原理來實現各個記憶體顆粒之間的頻率與相位同步。
Non-ECC Registered DIMM
看完前三種之後,或許你會想問:有暫存緩衝設計的記憶體就一定支援 ECC 錯誤更正嗎?其實答案是否定的,確實在規格上有 Non-ECC Registered DIMM 這種東西存在,但基本上近十年內是沒有主機板設計成支援暫存緩衝卻不支援 ECC 的,而且既然要加價購買,大部分人應該會選擇優先要 ECC 功能,而不是主要用處在於提升總容量的 Registered 功能吧?畢竟有錢買一堆記憶體來插的人應該不差那一點 ECC 的導入成本,所以這種記憶體在市場上幾乎是看不到的。
比較特殊的記憶體功能分類
實際上除了前面介紹的四種以外,還有 Fully Buffered DIMM (FB-DIMM) 與 Load Reduced (LR-DIMM) 兩種比較特別的記憶體,這兩類記憶體基本上「功能類似 ECC Registered DIMM」,都是具有 ECC 錯誤更正能力與暫存緩衝設計的記憶體模組,某種程度上也可以將這兩種記憶體視為「更極端」的 Registered 記憶體,目的在於更進一步的提高記憶體容量的上限與系統穩定性。
Fully Buffered DIMM (FB-DIMM)

這種記憶體在 DDR2、DDR3 之後幾乎是已經絕跡了,從名字中可以很容易得知,FB-DIMM 的特色就是會被放入暫存緩衝當中的東西比 Registered DIMM 還要來得更多 (相對成本也高得多),最明顯的特徵是記憶體模組上加入了一塊稱為 Advanced Memory Buffer 的緩衝晶片,就設計的角度來看,可以發現 FB-DIMM 的設計方針其實跟 PCI Express 有點類似,同樣採用序列、點對點傳輸的實作方式來取代傳統記憶體的並列傳輸。
由於這樣的作法會導致耗電量、延遲、成本、設計複雜度與發熱量的增加,加上改採序列傳輸對運作時脈的要求也變得更高 (否則頻寬達不到以前的標準),因此並沒有如當年預期的成為伺服器市場的主流,而是逐漸消聲匿跡,值得注意的是 DDR2 世代的 FB-DIMM 在腳位定義上實際上比標準的 DDR2 還要多了一些 (在防呆設計的兩側)。
Load Reduced DIMM (LR-DIMM)

基本上與 FB-DIMM 同樣是為了把伺服器的記憶體安裝上限拉得更高而設計,顧名思義設計目標上是為了降低記憶體匯流排的負載,從而讓系統可以挑戰更高的記憶體安裝上限與記憶體運作時脈 (而且還更加省電),以我個人用於網站與虛擬主機服務營運用伺服器上的 Intel S2600CWTSR 主機板來說,搭配 Registered DIMM 時記憶體安裝量上限僅有 512 GB,而採用 Load Reduced DIMM 之後可以一舉翻倍到 1TB。
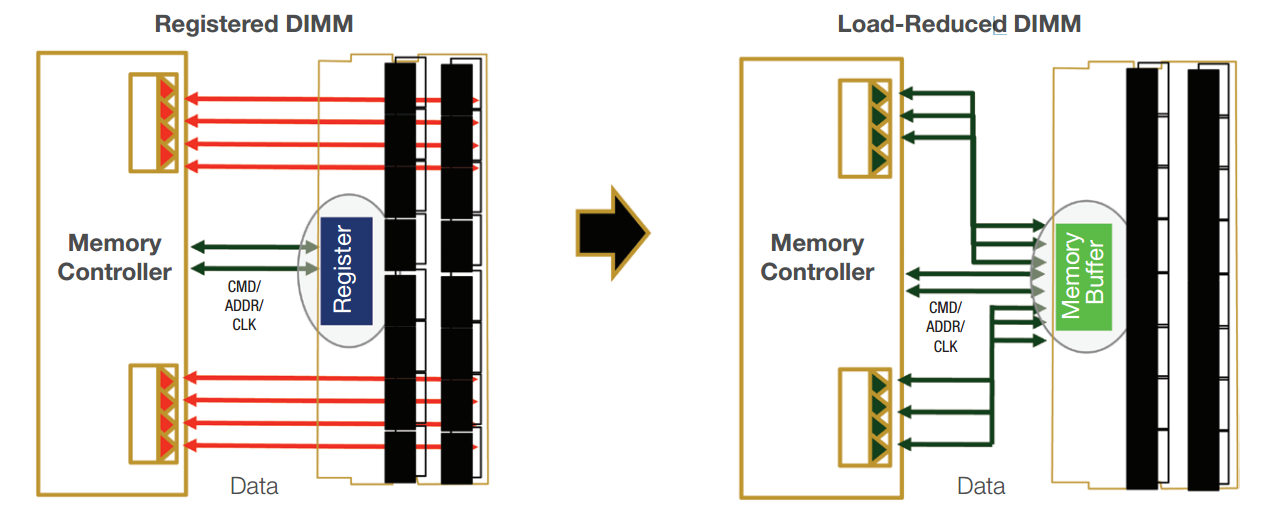
整體而言 LR-DIMM 架構上跟 Registered DIMM 比較類似,主要的差異在於使用 Inphi 發展的 Isolated Memory Buffer (IMB) 晶片取代原有的暫存器 (所以外觀上跟 FB-DIMM 蠻像的),並且與 FB-DIMM 相同,會對資料訊號也進行暫存緩衝,當記憶體控制器發出存取要求、指令與存取位置時,由緩衝晶片先行接收並一次供給給數個 Rank 的記憶體,取代原先 DDR4 記憶體設計將資料傳輸通道直接與各 Rank 連結的設計 (如上圖),從而降低記憶體傳輸通道的電子訊號負載,目前已經取代 FB-DIMM 成為 Xeon E5 系列處理器支援的記憶體類型之一。
Table of Contents
記憶體的組成結構
接下來這個主題可能對絕大多數人來說都比較陌生一些,因為如果不是在裝載大量記憶體 (逼近支援上限的時候) 的伺服器上,近年來其實我們很少在意這件事情,畢竟通常而言,只要制式跟速度挑對「插上去就會動了」,不過為了讓這章節的內容更加充實,所以我還是把這段納進來了。
記憶體組成的階層觀點
是的沒錯,又是階層,在電腦當中真的有很多東西是一層一層堆疊起來的,而記憶體也不例外,大致上可以從大到小分成 NUMA 節點 (Node)、記憶體通道 (Memory Channel)、記憶體模組 (DIMM)、Rank、記憶體顆粒晶片 (Memory Chip)、Bank、欄位這些階層。
NUMA 節點 (Non-Uniform Memory Access)
NUMA 節點這東西基本上要複數個討論起來才有意義 (只有單一一組的時候就是 UMA 嘛),然而直到目前為止,Intel Core 家族全系列都只由 1 個 NUMA 節點組成 (核心數不夠多而且只能裝一顆所以也沒特別 NUMA 分群,消費性作業系統也不支援對 NUMA 架構的優化),所以如果你對伺服器沒甚麼興趣的話,跳過這段也可以。
以電腦發展史來說其實 NUMA 架構算是蠻新穎的概念,要解釋非統一記憶體存取 (NUMA) 架構是甚麼東西之前我們得從「還沒有 NUMA 支援時的電腦」開始看起,以往電腦使用的統一記憶體存取 (UMA) 架構其實還蠻直覺的,由一條中央匯流排負責處理器與記憶體之間的所有資料交流 (有點像高速公路),架構圖大致上是長這樣 (這樣的設計又稱為對稱多處理器架構 Symmetric Multi-Processor, SMP):
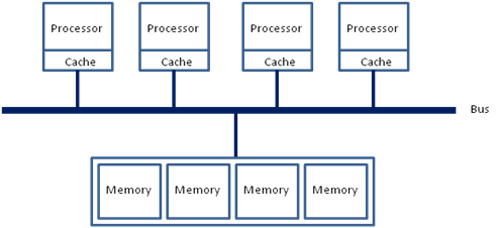
當然這樣做的缺點也很顯而易見,那就是中央匯流排的負擔會很重,因此隨著處理器的數量增加 (核心或實體方面都是) 與處理器、記憶體的速度越來越快,要建造一條足以承擔起所有處理器與記憶體之間資料交換的匯流排就變得很困難,而且會產生不必要的延遲 (因為每個處理器存取資料所要耗費的時間都一樣,儘管資料可能是放在距離要求資料的處理器距離很近的地方也是如此,延遲時間將「統一」為最長的延遲)。

為了解決這樣的問題,所以就產生了這樣的想法:那我們就把記憶體分塊,每個處理器各持有一些就好啦?(有點類似每個處理器的專屬快取記憶體) 如此一來設計匯流排就簡單了 (要連接的東西變少,速度也可以更快),主幹匯流排也就不需要承受那麼大的負擔了,但這世界往往並不如人們想像得那麼容易,這樣的設計雖然在「資料正好就在與需求處理器緊連的記憶體上」時性能很好,但如果資料在其他處理器附近的記憶體呢?那就得繞一大圈才有辦法拿到資料了,所以最後在現今的電腦設計上,是採用將兩種辦法混在一起用的折衷方案,也就是 AMD 早在 2003 年的 Opteron 中就開始使用,而 Intel 從 Nehalem 架構才開始採用的 NUMA 架構。
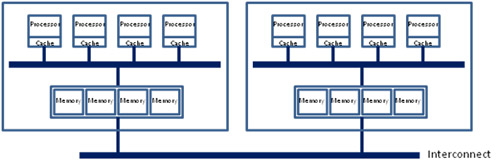
折衷方案的思維很簡單,我們就將幾個處理器劃為一組,而且讓每組都長得像 UMA 架構,然後使用可以彈性增減的高速互聯匯流排 (以 Intel 來說是 QPI,AMD 則是 HyperTransport) 將各組連接起來,就可以同時具備兩種做法各自一部分的特色了,上圖中的一個大藍色框就是一個 NUMA 節點,其中可能包含多個記憶體控制器,並管理多個記憶體通道。
不過呢還有一個問題,當作業系統不支援 NUMA 架構的時候,受制於存取策略不是為了 NUMA 架構而設計,性能表現很有可能比 UMA 架構設計的狀況下還要更糟,而且 NUMA 架構的群組要怎麼分配才能達到最好的性能也是一門很大的學問。
記憶體通道
由於討論 NUMA 架構的時候有時還會牽涉到單一 NUMA 節點內記憶體控制器不只一個,而是組成類似叢集的結構的問題,太過複雜所以在這裡我不打算討論,就直接進入記憶體控制器的下一階層-記憶體通道吧。
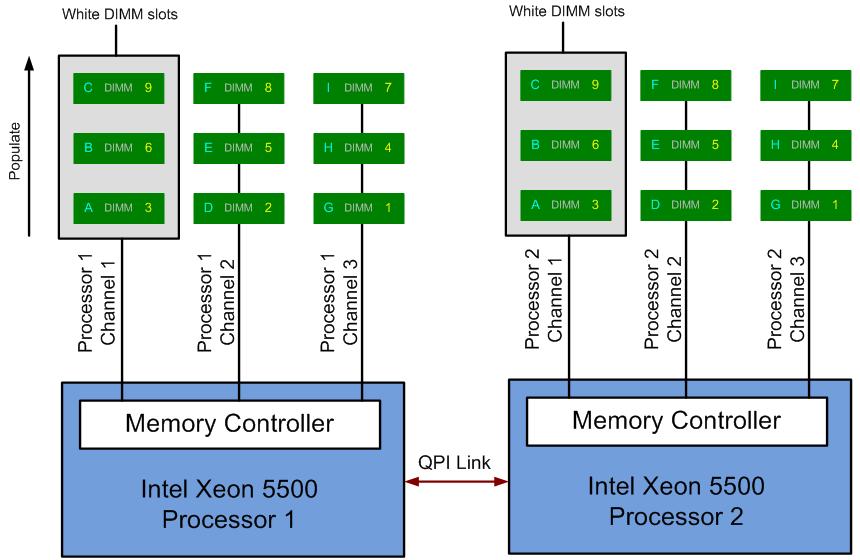
最早廣泛於消費性市場使用的多重記憶體通道設計其實是來自於後來在電腦市場商業上並不成功的 RDRAM,大約在 DDR SDRAM 發展到中晚期的時候開始盛行,原理上是透過將記憶體與記憶體控制器之間的傳輸通道採並列的方式增加為複數條 (有點類似高速公路增開線道的感覺),並將記憶體模組根據通道進行分組,來達成讓記憶體通道頻寬加倍的效果從而提升性能 (單通道為 64-bit,雙通道為 128-bit 以此類推)。
多通道記憶體技術比較需要注意的大概有兩點,是單一通道內的記憶體同質性不能太低 (一般來說建議使用同廠牌同容量同速度同時序的產品,如果可以使用完全相同的模組就盡量使用一樣的模組),至於原因呢就是前面提過的,記憶體控制器根據記憶體通道來將記憶體模組分組做使用,如果同組別內的記憶體不同步或是容量不一就會出現錯誤。
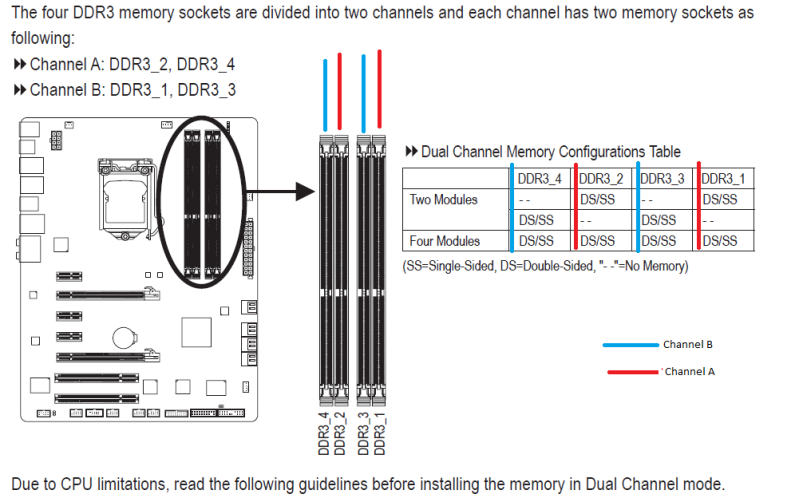
其二則是記憶體安裝需要留意主機板廠商走線的設計 (請注意主機板隨附的說明書中類似上圖的內容,有些廠商拉線拉成緊鄰的是同通道,也有一些則是把每一通道的第一支記憶體排在一起),依照正確的順序進行安裝才能確保獲得最高的性能 (開啟最多的記憶體通道),在多通道的主機板上安裝記憶體時,應該先盡可能讓每個通道都至少有一條記憶體,如果有分配不完的情況的話再讓其中一個通道多安裝一條同規格記憶體也是可以的,若不分青紅皂白直接照順序插的話有可能最後才會發現有一個通道沒被啟用,那就造成系統性能的白白浪費了。
記憶體模組
其實這項沒甚麼好解釋的,在仿間可以買到的記憶體 (長條狀的那個),一條就稱為一個記憶體模組,由一片電路板上面鑲嵌許多記憶體顆粒晶片等電子元件所組成,如下同所示:
趁這個機會順便說明一下 DIMM 這名稱是什麼意思好了,DIMM 的英文全稱是 Dual In-line Memory Module,中文則是雙列記憶體模組,名稱上是針對 DIMM 出現之前使用的 SIMM 記憶體模組而來,SIMM 記憶體長得跟 DIMM 類似,記憶體模組的通道寬度是 32 bit,兩面的金屬接觸點是彼此連通的,而相較之下 DIMM 則具有兩面不互通的金屬處點,且頻寬也翻倍成 64 bit,這就是 DIMM 名稱的由來。
Rank 與記憶體顆粒
相對於沒甚麼好說的記憶體模組而言,接下來這個就不太好懂了,據我所知在很多場合中記憶體的 Rank 與 Bank 這兩個名詞經常被混合使用,但這裡我選擇依照 JEDEC 規格書的定義來說明,在 JEDEC 的解釋上,Rank 這個階層是在記憶體模組與記憶體顆粒晶片之間的。

在討論 Rank 之前我們得先來看記憶體顆粒的規格,以 SK Hynix 發售的 DDR3 記憶體 HMT325S6CFR8C 為例吧,這款 2 GB 的模組是由 8 顆 H5TQ2G83CFR 顆粒所組成,根據 SK Hynix 官方公佈的規格我們可以知道 H5TQ2G83CFR 是一種容量為 2Gb (注意這個 b 是小寫,指的是 bit,跟我們平常用的 MB 單位正好差八倍,換算之後就是上圖中的 256 MB),通道寬度為 8 bit (上圖中寫的 x 8 就是了) 的記憶體顆粒晶片。
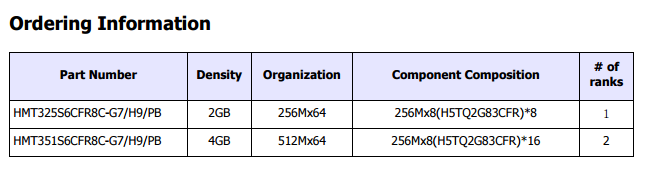

至於使用同款晶片的 4 GB 記憶體模組 HMT351S6CFR8C 則是由 16 顆 H5TQ2G83CFR 顆粒所組成,還記得我們前面說過個人電腦用記憶體 DIMM 的通道寬度是 64 bit 嗎?所以在上一段提到的 2 GB 模組中八顆記憶體顆粒晶片正好拼成 64 bit 寬沒甚麼問題,但你大概會想問,那 4 GB 模組呢?16 顆晶片不是應該拼成 128 bit 的雙倍寬度嗎?
但實際上並不是這樣,由於記憶體控制器一次就是只能處理單一通道 64 bit 寬度的資料,所以我們會在記憶體模組上加入一個稱為 Chip Select 的訊號,透過 MUX 多工器的方式「一次只選擇一組拼起來寬度是 64 bit 的記憶體顆粒」來進行讀寫操作,而這個分組就是我們所說的 Rank (反過來說 Rank 的定義也可以說成是一個 Chip Select 訊號所能選中的一群晶片)。
有一點要特別注意,那就是 Rank 的數量跟記憶體是否正反面都有記憶體顆粒晶片沒有關係,單面記憶體也可以做成雙 Rank,雙面記憶體也有可能實際上只是單 Rank,這取決於顆粒晶片本身的寬度需要多少顆才拚得成 64-bit 組合 (如果是 ECC 記憶體的話則以 72-bit 為一組)。
記憶體晶片顆粒與 Bank
接下來最後一個要討論的階層則是 Bank,根據 JEDEC 的定義,Bank 其實比記憶體晶片顆粒還要小,是構成記憶體晶片顆粒的一部分,相較於 Rank 可能影響主機板能夠安裝的記憶體容量上限或是能不能辨識某些高容量但採用低密度記憶體顆粒晶片的 DIMM,Bank 通常不會帶來甚麼影響,所以一般而言我們比較不在意 Bank 的部分。

還記得上一節曾經出現的這張圖嗎?當時我們用大型矩陣來比喻記憶體空間,其實一張圖上的這種大型矩陣就被稱為是一個 Bank,而一塊記憶體顆粒晶片上可能就有八個左右的 Bank 組合而成。