

由於篇幅過長因此站長後來決定將本文拆分為上、下二篇,本篇為「上篇」,主要介紹 DirectX 11 引入的新特性與 AMD 方面推出的世界第一款 DirectX 11 GPU 與對應的 Terascale 2 架構 (Evergreen 家族)。
接下來時序來到了 2009 年,在這一年當中對於 GPU 界來說最為重要的事情就是 Windows 7 的誕生帶來了 DirectX 11.0,距離上次大改版 (DirectX 10.0) 已經經過將近三個年頭之久。

DirectX 10 「補完計畫」
儘管 DirectX 11.0 跳入了下一個大版號,但實際上 DirectX 11.0 並沒有帶來甚麼非常大的變革,充其量就是 DirectX 10.x 的性能改進與功能補完罷了 (其實微軟如果將其命名為 DirectX 10.5 也不會太奇怪),DirectX 11 主要帶來了五個面向的改進,接下來我會逐項說明。

Shader Model 5.0
首先看到的是每次 DirectX 改版或多或少都會調整到的 Shader Model,由於統一渲染器架構已經在 DirectX 10.0 時代成形,因此這次 SM 5.0 的更新內容其實很少,主要出現在五個面向:
- 各類 Shader 指令整合得更加緊密。
- 新增對 Compute Shader 的支援 (實際上後來也被追認回 DirectX 10.x 規格中了)。
- 新增對 Hull Shader、Domain Shader 的支援 (之後在談 Tessellation 的時候會提到)。
- 新增數個額外指令支援。
- 將雙精度支援納入標準規範。
至於在規格參數本身的部分,SM 5.0 則沒有帶來甚麼明顯的變化。
DirectCompute 11
在前面的 5-17 當中我們曾經談過 GPGPU 通用圖形運算的崛起與發展,當時我就有特別提到 DirectCompute 這東西了,因此關於 DirectCompute 的緣起與發展我就不再重述,在這裡只提一些 DirectCompute 11 與 DirectCompute 10 之間的差異比較。
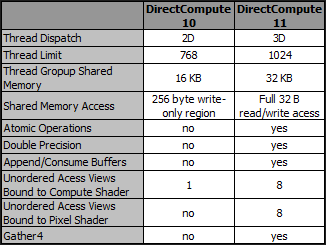
DirectCompute 在 DirectX 11.0 當中最重要的改進應該就是執行緒方面的限制獲得了很大幅度的放寬,支援的指令派遣方式從 2D 提升為 3D (可以提高效率),執行緒共用記憶體的大小也翻了一倍,並且在共享記憶體存取的部分有了飛躍性的成長 (本來只有 256 bytes 而且僅供寫入,DirectCompute 11 則一舉提高為 32 KB 且可寫入與讀取),並且加入對 Atomic Operations 的支援 (因此實際上 DirectCompute 只有在 DirectX 11 後的版本中才比較有實用價值,如同在 5-17 中我提過的 DirectCompute 10 基本上是微軟後來為了不甘願落後於 CUDA 與 OpenCL 發展才「追認」的版本,在最初的 DirectX 10 規格當中是沒這東西的)。
多執行緒優化
以往的 DirectX 基本上主要應對的是單 CPU 的系統配置,並且只提供相當有限的多執行緒支援 (舉例來說,以往 DirectX 內所謂的多執行緒指的是渲染一個執行緒、物理特效一個執行緒、材質貼圖一個執行緒,而不是我們認知中一件事情可以開一堆執行緒的做法)。
不過隨著雙核心處理器出現的機率越來越高,這樣的方式顯然無法充分利用現代處理器的性能,而且隨著 GPU 性能的提升 CPU 已經開始漸漸出現「餵不飽 GPU」的狀況了,因此勢必得針對這個問題進行依些修正才行,而這一切的關鍵在於非同步 DirectX API 呼叫的支援能力。
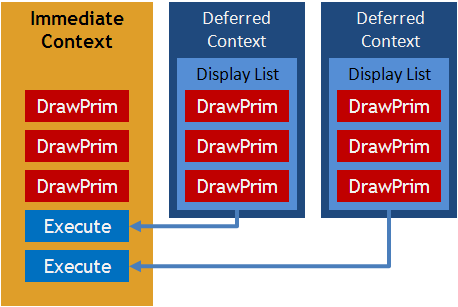
DirectX 11.0 使用的做法是從驅動程式與 API 方面的調整來允許開發者進行非同步 API 呼叫與非同步資源分配,並且如同上圖一般加入對多重 Context (情境內文) 的支援,分為一個主要 (Primary) Context 與數個次要 (Secondary) Context (由程式開發者定義),其中 Primary Context 又被稱為 Immediate Context,顧名思義這個 Context 才是 GPU 當下即時在處理的 Context,但在 DirectX 11.0 架構當中允許將 Secondary Context (又叫做 Deferred Context) 的工作對應到 Immediate Context 中執行,從而達成多重執行緒的效果。
材質壓縮
第四個 DirectX 11 改進重點則是在材質壓縮 (Texture Compression) 技術的部分,一直以來材質貼圖都是占用顯示記憶體空間最大宗的一類,因此材質壓縮技術的好壞對於 GPU 能處理的資料量與速度至關重要 (遊戲解析度也逐步增長到 1080P,甚至是未來的 4K,每次解析度上漲需要處裡的貼圖大小就變得更加驚人)。

在 DirectX 11 當中材質壓縮技術的改進主要可分為兩個方面,首先是首次對 HDR 影像材質引入了材質壓縮技術 (稱之為 BC6 壓縮),可以將 HDR 影像資料以 6:1 的比例進行壓縮,並且支援硬體加速解壓縮功能。

至於在一般的 LDR 影像材質的部分也引入了新的壓縮機制,稱之為 BC7 的新壓縮模式可以將 8-bit LDR 影像材質資料以 3:1 的比例進行壓縮,而壓縮前後的失真情形比起以往使用的 BC3 壓縮模式要來得好上許多。
(BCx 實際上是 Block Compression,區塊壓縮的意思,從以往的 DXTC 改名而來,到 DirectX 11.0 為止一共有 BC1~BC7 七種不同的壓縮模式,由於這部分內容太細節所以我就不特別提這七種壓縮模式的差異了。)
Table of Contents
曲面細分 Tessellation
接下來終於要講到 DirectX 11.0 最重要的改進了,曲面細分是一般人在進行遊戲或圖形應用時最容易感受到的新功能,也是對 DirectX 11.0 繪圖管線架構影響最大的一項,不過這項功能到底是幹嘛用的可能不是那麼好理解。
如果從字面的意義上來看,曲面細分指的就是將原先模型中的多邊形切割成數個細小的多邊形再進行個別處理,概念上畫起來跟微積分中的積分有一點相似,透過大量細分組成圖形的多邊形就可以逐漸逼近出圓滑的曲線 (進而得到外觀看起來更接近真實物體的模型)。
不過講到這裡相信你應該會有這個疑問:「那這樣 Tessellation 跟 Geometry Shader 有甚麼不同呢?」,沒錯,在功能上曲面細分確實跟幾何渲染器很像,都是可以基於現有模型下去「無中生有」出新的多邊形來讓畫質提高、使畫面更加逼真的技術,但它們本質上的差異造成了這樣的結果。
其實為什麼不使用 GS 的答案其實很簡單,因為 Geometry Shader 只是原本渲染管線的一部分,因此必須遵循原有的像素渲染流水線機制走過一輪之後才能讓 Geometry Shader 達成我們的目的,但顯而易見地這樣的作法會造成很多無謂的時間與性能浪費 (明明已經走過那些工序了卻為了生成新多邊形而得重頭走過),因此使用 Geometry Shader 來做曲面細分太慢也太過不切實際,於是才有了 Tessellation 技術的構想出現。
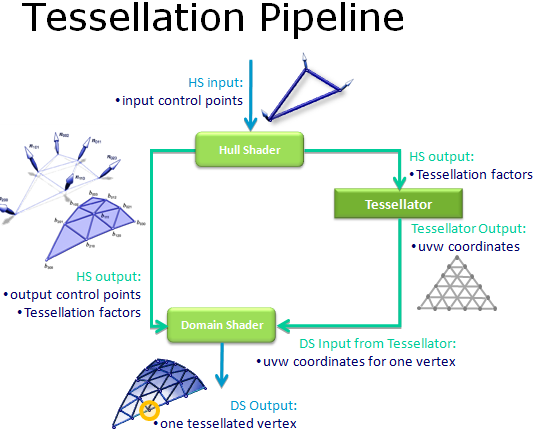
DirectX 11 當中的 Tessellation 技術主要是透過在 GPU 當中引入兩種新的 Shader 與專門用於處理曲面細分的電路單元來實做的,新增的兩類 Shader 分別是 Hull Shader (外殼渲染器,HS) 與 Domain Shader (域渲染器,DS)。
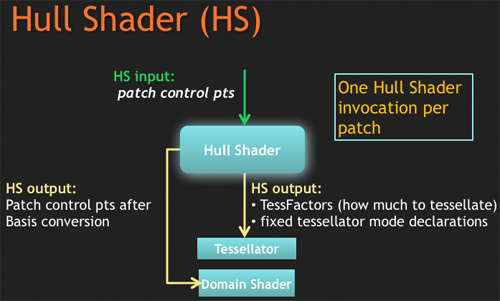
首先看到外殼渲染器 (HS) 的部分,在資料經過像素渲染器之後就會進入 HS,此時 HS 可以根據程式內的定義來決定是否將資料送到曲線細分電路 (Tessellator) 進行曲面細分處理,此外 HS 也負責決定後續的曲面細分處理要生成多少頂點與使用甚麼樣的演算法。
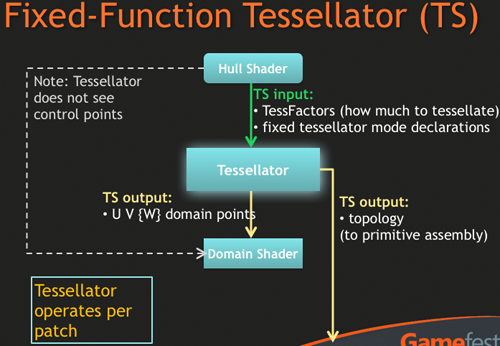
接下來進入曲面細分電路 (TS) 之後就會依據外殼渲染器 (HS) 的指示來進行曲面細分處理 (額外頂點與多邊形的生成) 等,完成處理之後就會將資料送交回域渲染器 (DS) 進行法線平移運算與置換貼圖等操作,並接續原有的繪圖管線繼續進行處理。
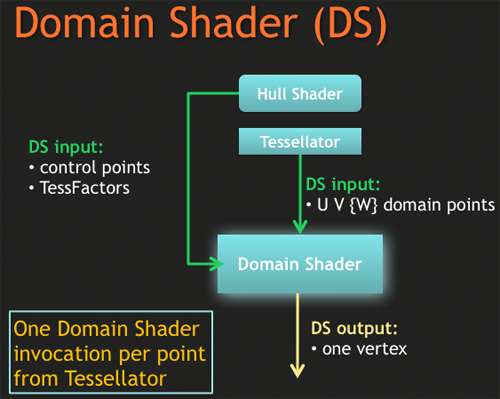
有趣的是,最早在電腦用 GPU 中加入曲面細分電路的是 AMD 的 Radeon R600,不過當時僅是 ATI 從設計 Xenos 時獲得的經驗「順便」加入到 R600 架構當中而已 (更早的前身其實是早在 DirectX 8.x 時代 ATI 就已經開始發展的 TruForm 技術),要說 ATI 是這項技術的主要發明者其實也不為過 (微軟也出了不少力),在當時這項技術還不是 DirectX 的正式規範,因此僅是 AMD 所獨有的設計,而且也還不成熟,有很多缺陷尚待補上因此並沒有被普遍應用,儘管後來曲面細分技術被微軟納入 DirectX 11 規範當中,但由於設計與 ATI 當年的做法不盡相同,因此並不能向下相容。

而更諷刺的是,由於 AMD 架構的先天缺陷,使得 AMD 產品在曲面細分上的性能高度受制於 GPU 內的曲面細分電路而無法像 NVIDIA 的架構那樣輕易拓展,因此在後來 NVIDIA 顯示卡在曲面細分方面的性能反而得以遠遠超過 AMD 的產品,甚至變成 NVIDIA 在 GeForce 400 系列當中大力宣傳的技術特性之一。

AMD Terascale 2
- 推出日期:2009 年 09 月 (Cypress)
- 所屬系列編成:Radeon HD 5000 系列、HD 6000 系列、HD 7000 系列、HD 8000 系列、Rx 200 系列
- API 支援:DirectX 11.0、OpenGL 4、OpenCL 1.2
- Shader Model 支援:SM 5.0
介紹完 DirectX 11 之後由於篇幅還剩下不少,因此我打算就在本篇順便接續介紹 AMD 的首款 DirectX 11 架構了 (之所以連續三篇接著介紹 AMD 架構是因為在 DirectX 11 這一世代是由 AMD 拔得頭籌),Terascale 2 架構是目前為止 AMD 沿用最久的一代 GPU 架構,最早可以從 HD 5000 系列開始出現,後來又屢次被用於低階入門款顯示卡上,直到 2014、2015 年都還可以在市面上買到基於 Terascale 2 架構的入門級顯示卡。
開發代號的由來
在開始介紹 Terascale 2 之前我想先聊聊這代產品的開發代號,之所以特別把它抓出來談的原因有二:這是 ATI/AMD 第一次用英文單字取名自家的 GPU 架構與核心,而且從此不再使用數字命名 (基本上是出於混淆對手的考量,因為 RV870 可以很明顯猜到這是 RV770 的後繼)、這個名稱跟台灣很有淵源。

Terascale 2 架構最初用於 Radeon HD 5000 系列,這個系列的開發代號被命名為「Evergreen」,沒錯,就是台灣的長榮集團,聽說由來是當年 AMD 圖形部門的主管來台灣參加台北國際電腦展 Computex 2007,在展會結束之後他們下榻的酒店就是長榮集團旗下的長榮桂冠酒店,而這群工程師正好又在想下一代產品要叫甚麼名字想不太出來,於是就有人提議乾脆用飯店的名字命名,因此這代架構就叫做 Evergreen 了 (除此之外這個名字還有象徵 AMD 主題色-綠色與象徵長青的意義)。
談完整個架構的名稱之後,由於從這次開始 AMD 就給每款核心取了不一樣的名字,因此我想先在這裡附上對照表,以便之後提到的時候看起來不會那麼讓人感到陌生:
| 上市名稱 | 開發代號 |
| HD 5900 系列 | Hemlock |
| HD 5800 系列 | Cypress |
| HD 5700 系列 | Juniper |
| HD 5600 系列 | Redwood |
| HD 5500 系列 | Redwood |
| HD 5400 系列 | Cedar |
路線之爭的延續
如果你還記得的話,上一篇我們花了很長的篇幅在討論 AMD 的發展策略轉變,實際上在 RV770 的接班人進入提案階段時,AMD 內部對於這樣路線轉變的爭論仍然是一直如火如荼地在進行的,要知道設計一款如此複雜的晶片並不是幾個月甚至幾天就能完成的事情,你得提前兩三年,甚至四年就開始準備。

眼看各種內線消息與跡象都指向 NVIDIA 將製作更大、更快的晶片來徹底擊垮 AMD,但 AMD 卻選擇撤守並且端出相對不那麼大、不那麼快的 RV770,而 Radeon 團隊的主管還得說服大家後續的 RV870 (後來叫做 Cypress) 也應該這麼做,這顯然不會是一件容易的事情。
要知道,當時距離 RV770 上市還有一年多,沒有人能夠預知 RV770 最後會是成功的,甚至公司內部大多數人已經在做 RV770 毀滅 AMD 圖形部門的心理準備了,而市場部門也希望開發團隊可以設計大核心的 R800 作為 RV770 失敗時可以盡快接檔的備用方案,因此也不支持 RV870 計畫。
折衷的結果
早先負責 RV770 規劃且力主持續推動小核心戰略的主管-Carrell Killebrew 在這樣的狀況之下其實已經幾乎要起心動念離職,他知道 AMD 沒有本錢像 NVIDIA 那樣去追逐巨大的核心設計,並且深信讓 AMD 成功的最短捷徑其實是在中高階產品的部分出奇制勝讓 NVIDIA 被殺個措手不及,但在市場部門與工程部門內不少工程師不支持的狀況下也只能選擇妥協。
在計畫成形的最後階段這位主管選擇不事先設定晶片的面積大小,並且將目標設定為將性能提升到 RV770 的兩倍,事後來看其實這樣的做法還蠻聰明的,首先 Killebrew 基本上知道在設計大型晶片時很快會遇到實務上的困難與高昂的成本難以控制的問題,進而迫使團隊內的人重新討論並接受現實,而最後如果真做出來基本上也不會對 AMD 造成太大的損害 (畢竟大核心相對而言還是有著價格滑落較慢,可以維持作為高端產品的時間較長的優勢),而團隊裡的工程師與行銷部門也會因為 Killebrew「好像」同意回歸建造大核心的基本策略而暫時停止爭論,並且回頭專注於他們手上的工作。
在 2008 年的時候來自台積電的消息就讓 AMD 的圖形晶片團隊不得不回頭重新考慮了,當時台積電的 40 奈米製造工藝並不理想,而且生產成本相當高昂,如果晶片面積不壓下來的話,AMD 的產品幾乎沒有成功的可能,於是他們如同 Killebrew 預想的一般,重新討論並且決定將 Cypress 的面積縮小,不過那時已經是 2008 年的 3 月了,AMD 並沒有剩下多少時間,這時候才回頭修改勢必會使得 Evergreen 無法如期上市,而且這意味著勢必得移除一些本來 Cypress 計畫中應該包含的功能。
犧牲打-RV740
如果你對上一篇的內容還有印象的話,應該會知道 RV740 是 R700 系當中唯一使用 40 奈米製程的核心,實際上這款晶片幫了 Cypress 非常多,要說 RV740 是 AMD 為了確保 Cypress 成功而做出的犧牲打一點也不為過。

通常來說,半導體廠商導入新製程不外乎為了讓溫度更低、成本下降 (單一晶圓可以切出更多晶片)、性能提升 (電晶體變小意味著你可以塞更多到單一晶片上),但 RV740 的目的並不在這裡,實際上 RV740 採用 40 奈米製程的原因是 AMD 預期在進入 40 奈米製程這關時可能會遇到較大的障礙,並且可能會有許多問題需要解決,因此在「公司可以承擔的失敗大小」範圍內選擇了最接近上限的 RV740 作為實驗對象。

這樣的做法其實並不少見,在過去幾代 NVIDIA 與 ATI 的 GPU 當中其實也蠻常看到中階產品領先頂級產品一代導入新製程的例子,不過這次應該是當中效果最顯著的一次,一方面是 AMD 迫切需要 Cypress 的成功,另一方面則是台積電在 40 奈米節點的表現確實不理想 (其實 45/40nm 這關似乎真的不太好過,Intel 也是在 45nm 的時候開始導入 High-K 金屬閘極技術的)。

後來 RV740 還真的遇到了很多問題,像是溫度表現甚至比同代的 RV770 還要慘烈、初期良率也很糟糕、功耗也因為漏電率高而不理想,不過 AMD 耗費心力逐一解決這些問題之後,才讓 Cypress 得以少掉許多困難甚至潛在的失敗因素,因此可以說是以 RV740 的失敗來換取 Cypress 堅實的基礎也不為過。
Evergreen 架構
講了這麼多 Evergreen 發展過程中的插曲,接下來讓我們回到 Evergreen 架構本身吧,首先要說的是,Evergreen 架構實際上就是第二代 Terascale,因此基本上不必期待在架構上見到太多變化,以下就是 Evergreen 系列核心當中規模最大、最完整的 Cypress 內部的架構圖:
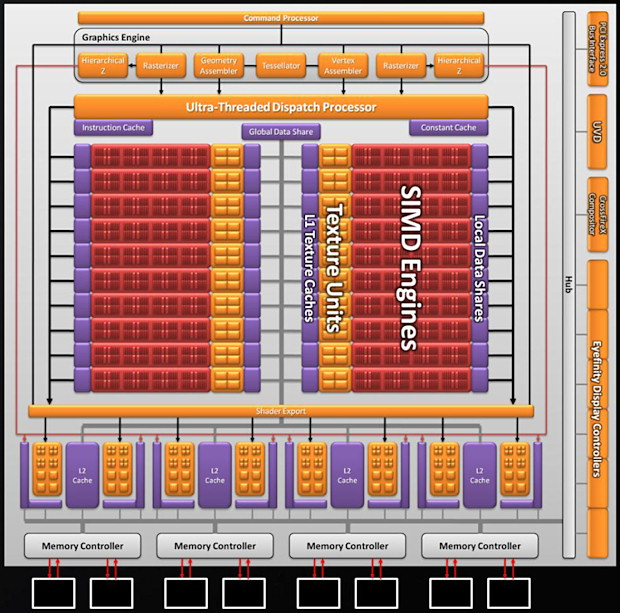
還記得我剛剛提到過 Cypress 的目標是達到 RV770 的兩倍性能嗎?從上面的架構圖當中相信最明顯的就是中間那堆方塊了吧,看起來是不是很像兩顆 RV770 去頭去尾之後的樣子呢?這就是 Cypress 當中對於性能加倍要求最直接的體現,但實際上 Evergreen 的改進並不僅止於把舊架構延伸兩倍,若深入去看每個部份就會發現其實幾乎各個地方都有大大小小的調整,首先讓我們從最上面的部分開始看起 (AMD 幫這部份起了個新名字叫做 Graphics Engine)。
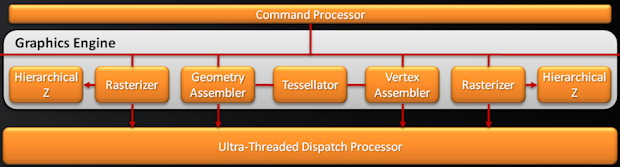
這部分跟過去相比的差異並不是那麼明顯,從圖上可以見到的主要改進內容是增加了第二組的 Rasterizer 與對應的階層式 Z-buffer,除此之外就是 Terascale 架構最重要的特徵-Ultra-threaded Dispatch Processor 了,之所以特別增加了第二組 Rasterizer,主要的考量是希望確保在後續的運算資源倍增之後,將多邊形分拆為像素運算的動作可以快到至少能夠餵飽後面的運算單元,而避免閒置的狀況發生。
不過如同前面談 DirectX 11.0 時特別強調的,Tessellation (曲面細分) 是這一世代最重要的新功能之一,因此理所當然 AMD 在這裡針對 Tessellator 做了很多強化,讓其能夠從前幾代基於自家特殊規格且始終未獲得廣泛應用的功能脫胎換骨成為符合 DirectX 11 規範的曲面細分電路,不過不幸的是 AMD 僅針對曲面細分電路本身進行強化,因此後來在 NVIDIA 推出次世代產品之後,AMD 的曲面細分性能就無法與 NVIDIA 的產品匹敵了,這造成最後曲面細分反而變成 NVIDIA 主打特色之一,讓 AMD 的處境可說是十分的尷尬。
接下來要看到的就是運算引擎的部分了,AMD 同樣是採延續前代架構的方式進行,但是一舉將 SIMD Array (現在改稱 SIMD Engine) 的數量提高為 20 組,並且給每組 SIMD Engine 都設計了專屬的 32 KB 本地資料記憶體 (主要是為了運算用途),可供單一 SIMD Engine 裡的 160 個 SPU (現在改稱 Stream Cores) 存取,而上一代所加入的全域資料分享記憶體也被保留了下來 (而且大小從 16 KB 一口氣翻了四倍變成 64 KB)。
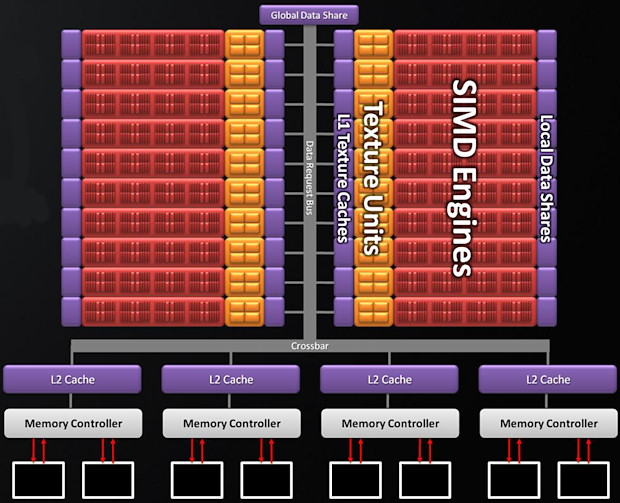
在新架構之下意味著 Evergreen 至多可以擁有高達 1,600 個 SPU (SC),除此之外 AMD 也在 Evergreen 的 SIMD Engine 當中納入許多配合 DirectX 11.0 與 DirectCompute 11 的小改善,因此說 Evergreen 是世界上第一款完整支援 DirectX 11.0 的 GPU 是沒有任何問題的。
除此之外為了能夠妥善處理數量規模加倍之後 SIMD Engine 大增的資料產出量,Cypress 中的四組 L2 Cache 也相較於前代來說增加了一倍 (64 KB → 128 KB),並且大幅提升了資料傳輸率,ROP 的數量也增加了一倍 (高達 32 組)。
Cypress 核心
簡單看過第二代 Terascale 架構之後,接下來循往例要開始看實際產品了,首先登場的是最完整的 Cypress 核心,由高達 21 億個電晶體組成 (如同架構一般,這超過了 RV770 的兩倍,足足是 GT200 14 億的 1.5 倍之多),但得益於新的 40 奈米製程,Cypress 的面積相較於 RV770 來說其實並沒有出現太誇張的成長 (282 平方公分 → 334 平方公分),

基於 Cypress 的型號主要有三款,全部都屬於 HD 5800 系列,分別是最高階的 HD 5870 (850/1200 MHz)、HD 5850 (725/1000 MHz) 與隔年二月才追加的 HD 5830 (800/1000 MHz),值得注意的是其中只有 HD 5870 具備完整的 20 組 SIMD Engine (1600 個 SC),HD 5850 則是少掉 2 組 (因此只有 1440 個 SC),HD 5830 更是只剩下 14 組 (只具備 1120 個 SC),隨著 SIMD Engine 的閹割,TMU 的數量也跟著減少,分別為 80、72、56 組,從這裡可以看出 Cypress 的良率其實仍然不算高,因此產生了大量需要部份屏蔽 SIMD Engine 的產品。

Hemlock
然而在 HD 5000 系列這一代,AMD 還是繼續沿襲了前兩個世代的作法,也就是在自家最高階的產品使用兩顆中高階 GPU 組成單卡雙晶片結構的方式,因此代號為 Hemlock 的 HD 5970 實際上就是由兩顆 Cypress (與 HD 5870 同為完整版核心) 所組成,不過時脈略降為 725/1000 MHz (下圖最右邊最長的那張就是 HD 5970 了)。

整體來說 Hemlock 的做法與前兩代並沒有甚麼不同,同樣是由 PLX 橋接晶片負責連接兩顆晶片,並且各自保有各自的記憶體系統的方式組成。

不過談到 Hemlock 就不得不提到當年 Cypress 開發到後期時因為要砍功能降面積而發生的故事,其實本來一開始 AMD 在設計 Cypress 的時候其實跟前作 (HD 4870 X2) 一樣設計了一個叫做「Sideport」的介面,顧名思義這東西就是「出現在 GPU 側邊的連接埠」,實際上本來是要用來連通兩顆 Cypress 之間作為高速內部傳輸通道的設計。
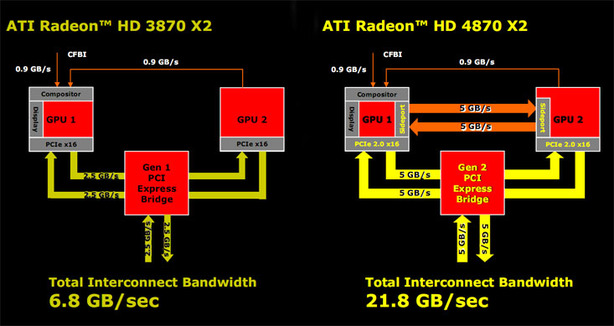
Sideport 是兩條雙向各自獨立,且各具備 5 GB/s 頻寬的高速內部傳輸通道 (頻寬跟 PCI Express Gen 2 一樣),這兩條通道主要是為了解決單卡多晶片內部 CrossFire 時兩顆 GPU 之間同步問題而設計 (要知道 CrossFire 只有在交互畫面渲染 AFR 模式下兩顆 GPU 之間才不需要互動,否則為了同步會導致很明顯的性能損失)。
不過這個設計最後在 AMD 工程團隊不得不削減 Cypress 的晶片面積時被移除了,因此 HD 4870 X2 成為歷史上唯一一款有使用這項技術的 GPU。
Juniper 核心
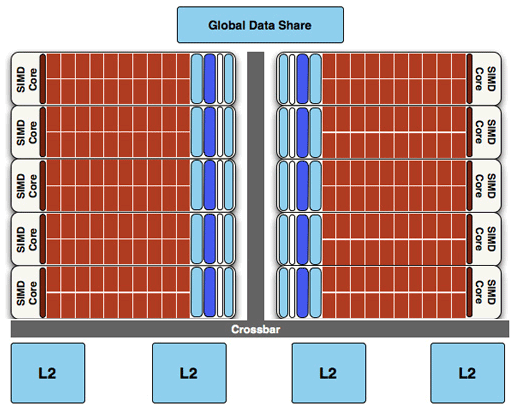
接下來要看到的則是主要面向中階市場的 Juniper 核心,實際上 Juniper 與 Cypress 是同步開發的,而且最後 Juniper 流片的時間還略早於 Cypress。

相較於完整版的 Cypress 來說,Juniper 主要被刪減的部分出現在繪圖引擎的地方,從架構圖直觀上來看可以很容易得知 Juniper 的 SIMD Engine 只有 Cypress 的一半,因此 Juniper 的 SC 數量最多也就只剩下 800 個了,理所當然對應的材質單元也從 80 個砍半為 40 個,不過實際上除此之外 AMD 還砍掉了雙精度浮點運算單元與一半的渲染輸出單元 (ROP)。
基於 Juniper 核心的產品一開始有兩款,分別是 HD 5770 (850/1200 MHz) 與 HD 5750 (700/1150 MHz),其中後者有一組 SIMD Engine 被砍,因此只有 720 個 SC、36 組 TMU,下圖當中最短的就是 HD 5770 了,可以看到 AMD 在這一代給自家顯示卡產品使用了非常相似的公版外觀設計。

不過 HD 5750 就沒有用上同等級的散熱設備了,相對來說看起來陽春許多。

最後關於 Juniper 核心要特別談到的是後來 HD 5770 與 HD 5750 這兩款產品,在下一世代當中被直接改名為 HD 6770 與 HD 6750,規格參數方面則沒有甚麼調整 (除了 HD 5770 有推出 1 GB 記憶體但記憶體時脈調降為 1050 MHz 的版本之外)。

Redwood 核心
除了 Juniper 之外,AMD 還準備了兩款更入門定位的核心,首先要談的是定位從主流級到入門級橫跨了數個價格帶的 Redwood。

Redwoood 的規格設定基本上就是從 Juniper 在削減一半而來,因此只剩下五組 SIMD Engine,合計共有 400 個 SC,TMU 再次減半為 20 個、ROP 也跟著減半為 8 組,除此之外記憶體頻寬也跟著折半回到 128-bit 了。

由於橫跨的價格帶廣,因此 Redwood 也是 Evergreen 家族當中衍伸型號最多種的一款核心,可分為 HD 5670 (775/1000 MHz + GDDR5 或 775/800 MHz + GDDR3)、HD 5610 (650/500 MHz + GDDR3)、HD 5570 (650/900 MHz + GDDR3 或 650/400 MHz+ DDR2) 與 HD 5550 (550/800 MHz + GDDR3 或 550/400 MHz + DDR2) 四款,其中除了 HD 5550 特別又砍了一組 SIMD Engine 因此只剩下 320 個 SC 與 16 組 TMU 之外均為完整核心。
Cedar 核心
Evergreen 家族的最後一款核心就是面向入門市場的 Cedar 了,依循 AMD 的往例在最低階核心當中只配置基本元件的慣例,Cedar 只有一組 SIMD Engine,因此只有 80 個 SC,記憶體頻寬也只有 64-bit,TMU 更是只有可憐的 8 組,ROP 也又被拆掉了一半因此只剩四組。

不過由於其性能非常適合用於入門級電腦,而且甚至可以不需要散熱器,因此基於 Cedar 核心的產品很長時間扮演了 AMD Radeon 系列入門級產品的角色,從最早的 HD 5450 (650/800 MHz + DDR3 或 650/400 MHz + DDR2),後來的 HD 6350 (650/800 MHz + DDR3) 與 HD 7350 (650/900 MHz + DDR3 或 400/400 MHz + DDR2)、HD 8350 (400-650/400 MHz + DDR2 或 400-650/800 MHz + DDR3) 與 R5 210 (400/900 MHz + DDR3) 都是基於這款核心設計的。
