

用了一連三篇的篇幅介紹近幾代 NVIDIA GPU 的架構之後,接下來我打算把目光放回 AMD 陣營的對應產品 (我知道我還沒寫 NVIDIA 目前主推的 Pascal 架構,不過由於這系列連載規劃的時候 Pascal 架構連個影子都還沒有所以也就沒列入計畫中了,之後有機會的話再寫 XD)。
由於本篇距離上篇發佈的時間已經隔了相當久,因此在正式開始介紹本篇的主角之前,我打算先簡短回顧一下先前曾經提過的內容,在 5-23 節的時候我曾經提到 AMD/ATI 在過去這一二十年的歷史當中其實幾乎是不斷在重複同樣的發展循環,在 2004 ~ 2006 年時 ATI 本來因為 R400 的了無新意、R500 的難產與 R600 的失敗一度被 NVIDIA 打個半死並導致後來 AMD 的收購,但在 2007 年時甫被收購不久的 ATI 就在 R700 系列當中突然轉換策略使用小核心戰略的奇襲戰術來反將 NVIDIA 一軍,並在後來的 Evergreen 系列當中創造了又一次的輝煌時期。
不過緊跟在 Evergreen 系列之後的北方群島系列就如同當年 R400 系列一般陷入了無新意的困境了,但這次 AMD 總算好不容易沒有像當年那樣再次陷入循環,而是跳過自由落體的階段,在隔年就進行了如同當年 R600 一般進大規模的策略轉換,在北方群島系列之後推出了基於全新 Graphics Core Next (GCN) 架構設計的南方群島系列。
Graphics Core Next (GCN) 架構
如同在「電腦達人養成計畫 5-20:後 ATI 時代的挫敗與策略轉向-Terascale 架構 (上)」當中曾經提過的,從 2012 年以降的所有 AMD 圖形晶片架構大抵都從本篇要介紹的 Graphics Core Next (GCN) 架構演化而來,截至目前為止 (2018 年) 已經有四個世代 (其中分別有數次代內更新),因此與先前介紹 Tesla 與 Terascale 的做法相似,我打算將 GCN 架構分為四期介紹 (由於本篇連載規劃的時候 Vega 還沒有誕生,因此目前預計只會先撰寫前四個世代的介紹),目前暫定分為上、下兩篇。
GCN 架構概觀
相信大家讀到這裡應該對於 AMD 與 NVIDIA 兩大陣營之間的架構設計思維差異已經有蠻多認識了吧?NVIDIA 的架構是採用 MIMD (Multiple Instruction Stream Multiple Data Stream) 架構,也就是實際負責運算的部分是由大量一模一樣且較為簡單的運算單元 (NVIDIA 將其稱為 CUDA Core) 所堆起來的 (如下圖中的綠色方塊)。
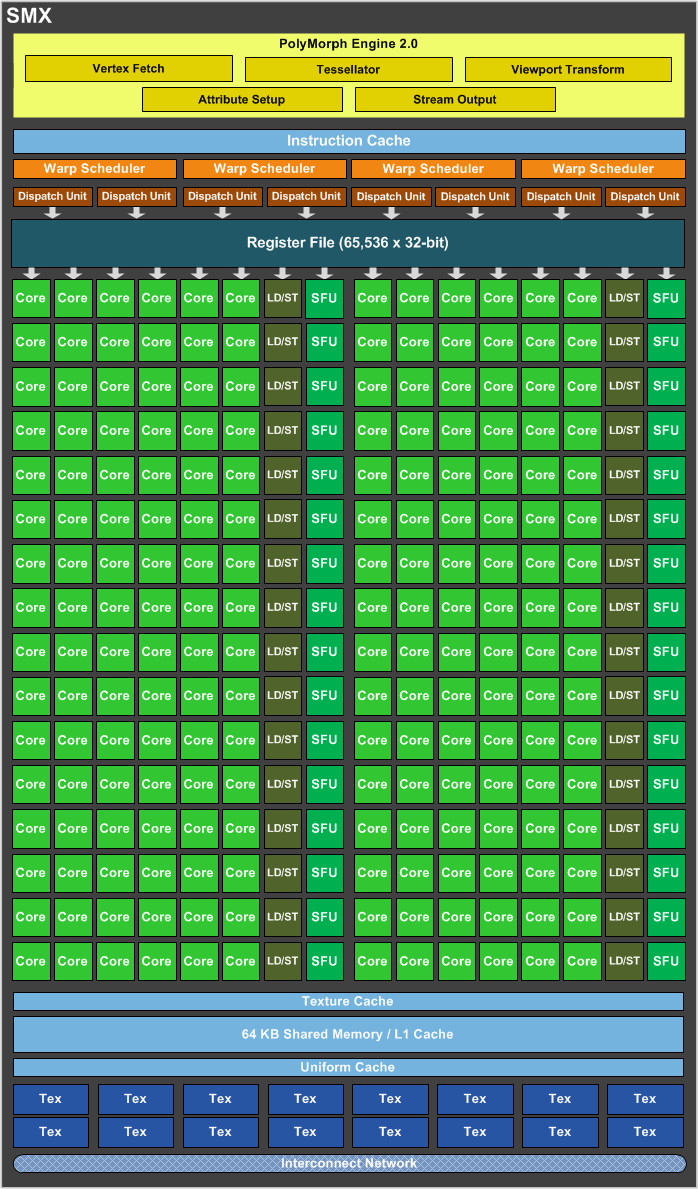
而 AMD 的做法則是採用 SIMD 架構設計,也就受主要運算單元由數組 SIMD Engine 所組成,每一組 SIMD 引擎又由一群運算單元組成,而每個運算單元同時間只能接受「一個」長指令 (也就是 Very Long Instruction Word, VLIW 指令) 輸入但是可以處理多種資料流。

雖然理論上這兩種架構都能達成相似的目標,但是 AMD 的架構對於驅動程式與指令排程器會有較高的要求 (若因為指令相依或是驅動程式未臻完善等情況導致 VLIW 指令合併沒有完全成功,指令無法正確對其硬體單元的配置的話,就會使得運算單元有一部分處於閒置狀態的情況發生)。
基本上這兩種架構之間各有優缺點,並沒有絕對的好壞之分,而是要看當下處理器所執行指令的「適性」如何而定,AMD 採用的架構在設計電路上複雜度相對較低因此單位面積內可以塞入更多的運算單元,使得創造出比 NVIDIA 更高的「理論峰值性能」數值成為可能,但在指令適性不佳無法充分利用硬體資源的時候就顯得難以發揮,因此有著高度依賴驅動程式與編譯器優化的問題。
而 NVIDIA 的架構則比較能夠適應各式各樣的運算而不需要特別仰賴驅動程式或編譯器的優化,但相對來說在設計電路上複雜度會飆升許多使得晶片上所能設置的運算核心數目受到較大的限制。
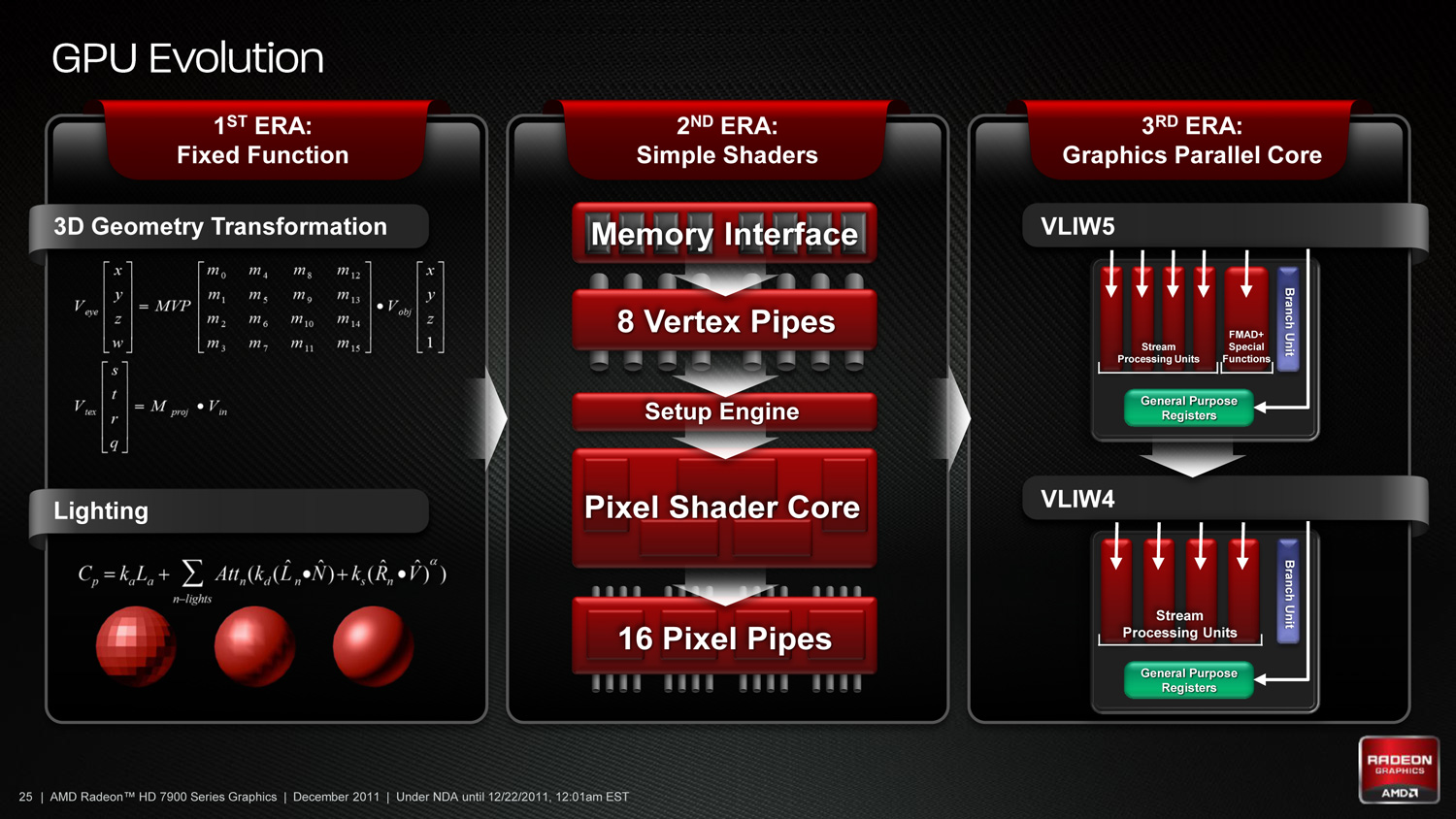
一般來說在處理相對而言比較單純的圖形運算時,這兩種架構的表現基本上難分軒輊,但是隨著後來遊戲中可以充分完整利用 VLIW 指令組的頻率越來越低 (以 AMD 自己做的研究來說,平均而言 VLIW5 架構中的 VLIW 利用率不到 68%,平均每組當中大約只使用到 3.4 個運算單元) 又加上 GPGPU 通用運算的流行,由於 VLIW 本身很難提前進行指令排程,對於驅動程式與編譯器的依賴度甚高,也無法在執行過程中進行動態排程,因此在處理通用運算工作時 VLIW 指令合併失敗的情況也隨之大幅增加到足以明顯影響運算性能表現的程度,而 GCN 架構主要就是為了解決這個問題而誕生的 (如果再不改整個通用運算市場會被 NVIDIA 整碗端走)。
捨棄 VLIW 設計,轉為 MIMD 架構但仍保留著濃厚的 SIMD 色彩
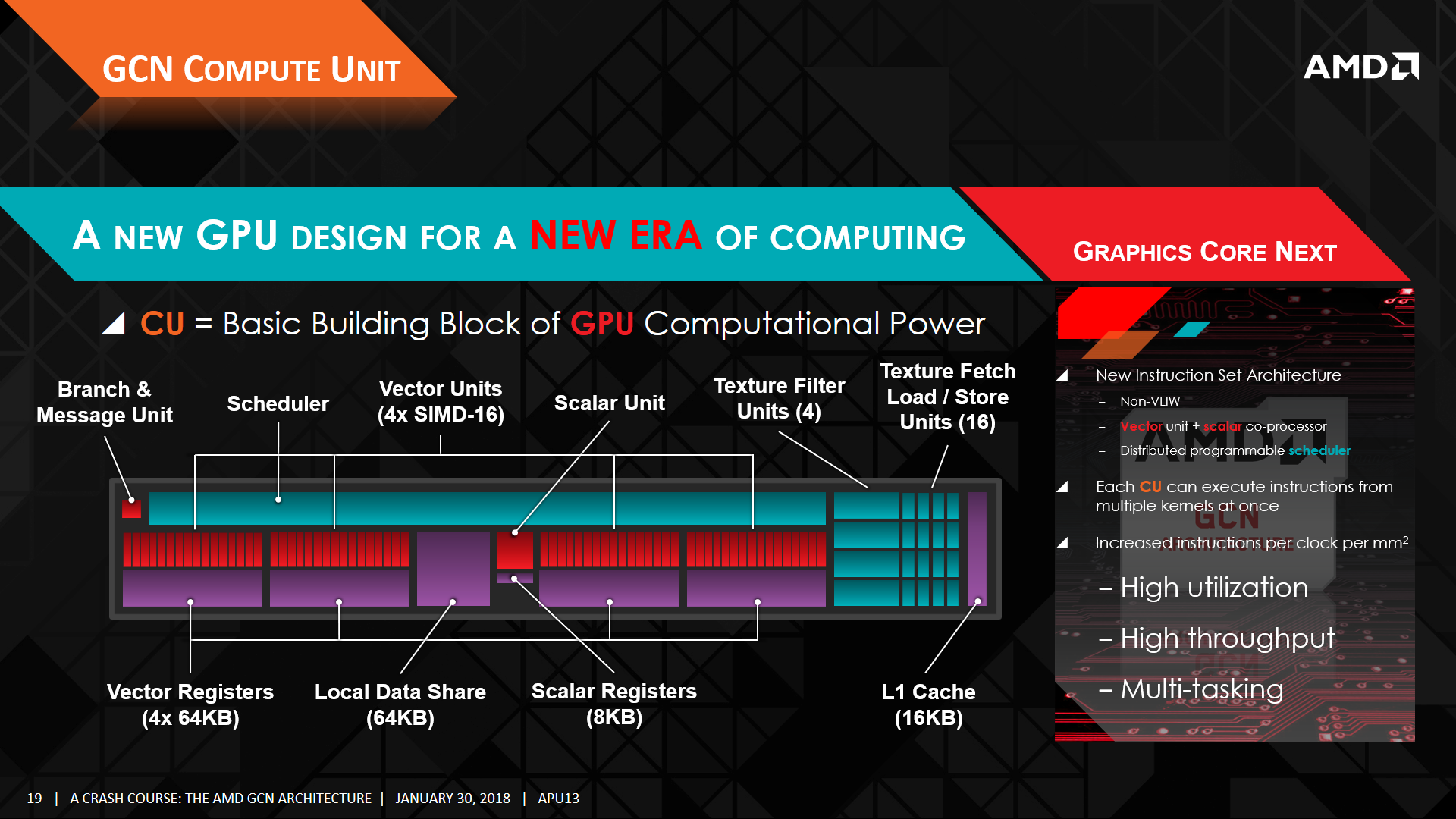
Graphics Core Next 架構相較於 Terascale 家族來說,最鮮明的特色就是 AMD 決定捨棄在自家產品上已經沿用多年的 VLIW 設計 (是一種指令級的平行化設計 Instruction-level Parallelism) 與 SIMD 架構,但儘管 AMD 捨棄 VLIW 架構進而改採基於執行緒級的平行化設計 (Thread-level Parallelism) 也轉為使用 MIMD 架構,但其實 Graphics Core Next 架構當中仍然有著濃厚的 SIMD 色彩,因此說 AMD 從 GCN 開始效法 NVIDIA 使用相同的架構設計這說法是大有問題的 (AMD 官方說法是認為 GCN 是一種基於 SIMD 陣列的 MIMD 架構,實際上也可以將其理解為 SIMD 與 MIMD 的混和運用)。

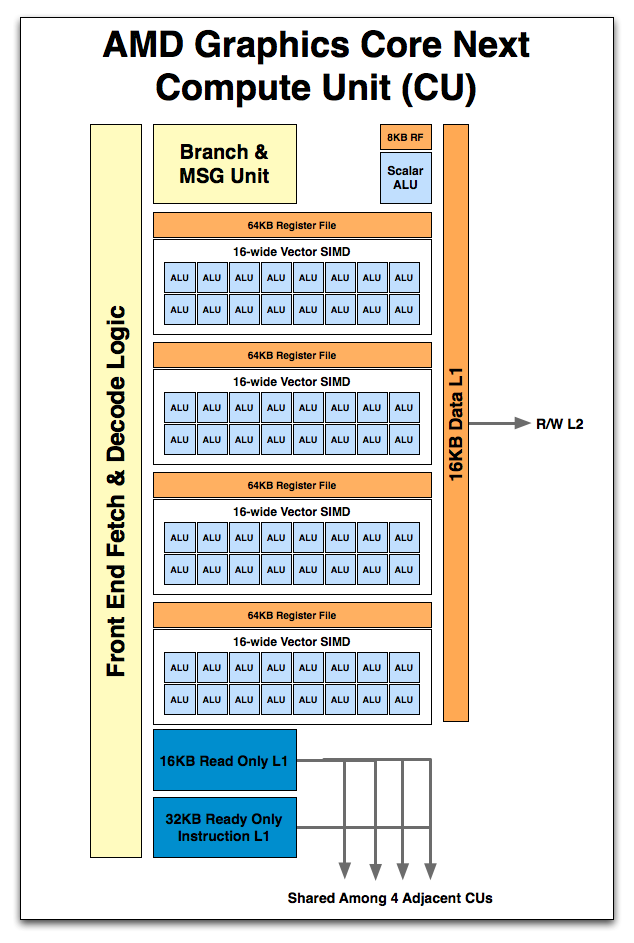
上圖顯示的是 GCN 架構下的向量運算元件中實際負責運算的部分 (AMD 官方稱之為 Vector SIMD),與之前的 VLIW 架構相比應該不難看出兩者之間有相當大的差異,同時這大概也是某些人會誤以為 AMD 直接學 NVIDIA 改成 MIMD 架構的主要原因,畢竟在繪製簡圖的時候負責組成運算基本單元 Compute Unit (CU) 的這票 ALU 看起來確實跟 NVIDIA 陣營的 CUDA Core 可說是十分相似可不是嗎?但實際上 AMD 的設計與 NVIDIA 的架構在本質上仍然有相當明顯的差異。
Compute Unit (CU)
在 Terascale 架構當中實際負責運算工作的單元是串流處理器 (Streaming Processor),而到了 GCN 世代之後負責實際運算作業的基本單元則被 AMD 命名為 Compute Unit,CU 實際上是比起過去 Terascale 架構當中的 SP 更高一階的運算單元組合單位。
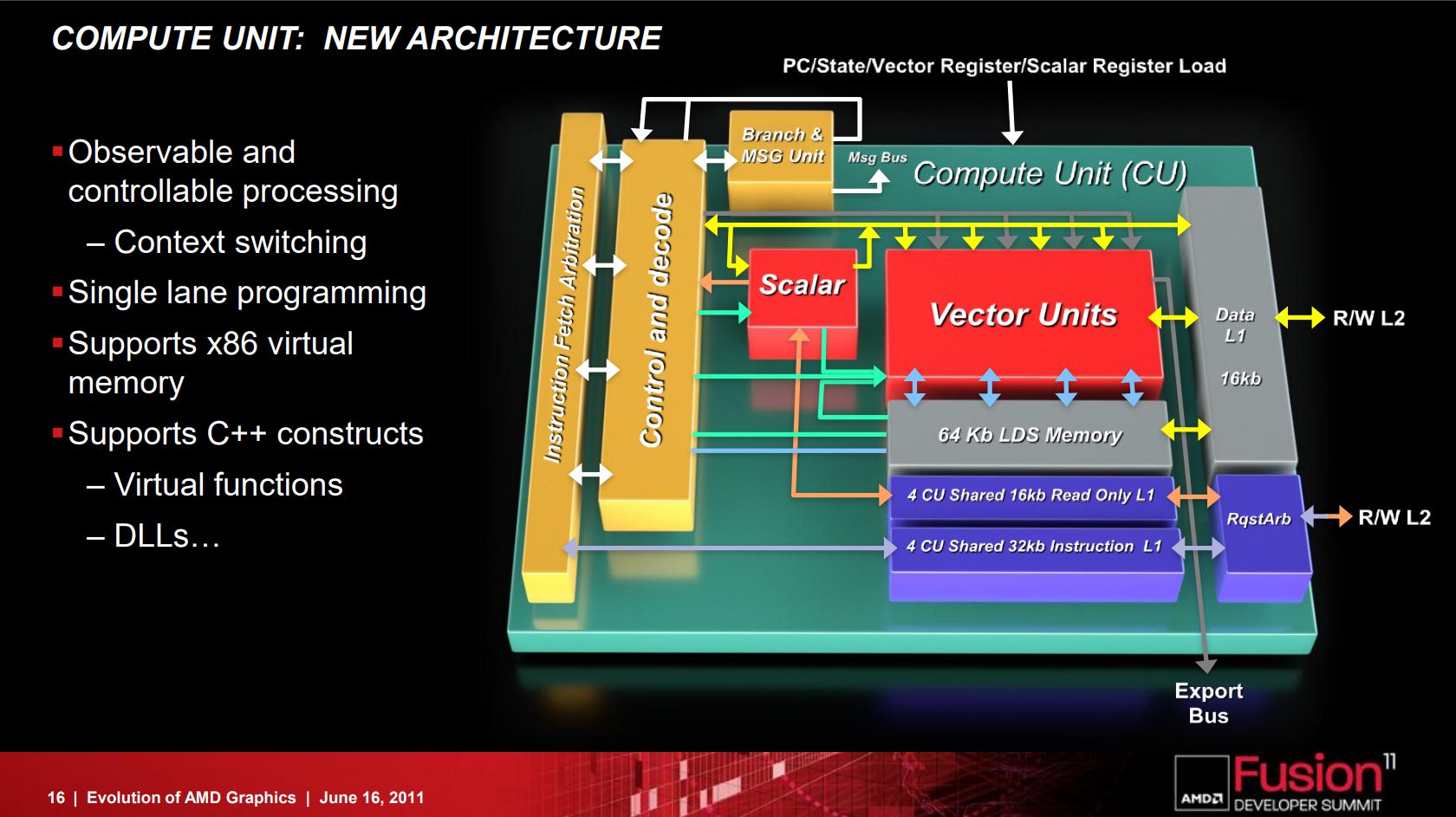
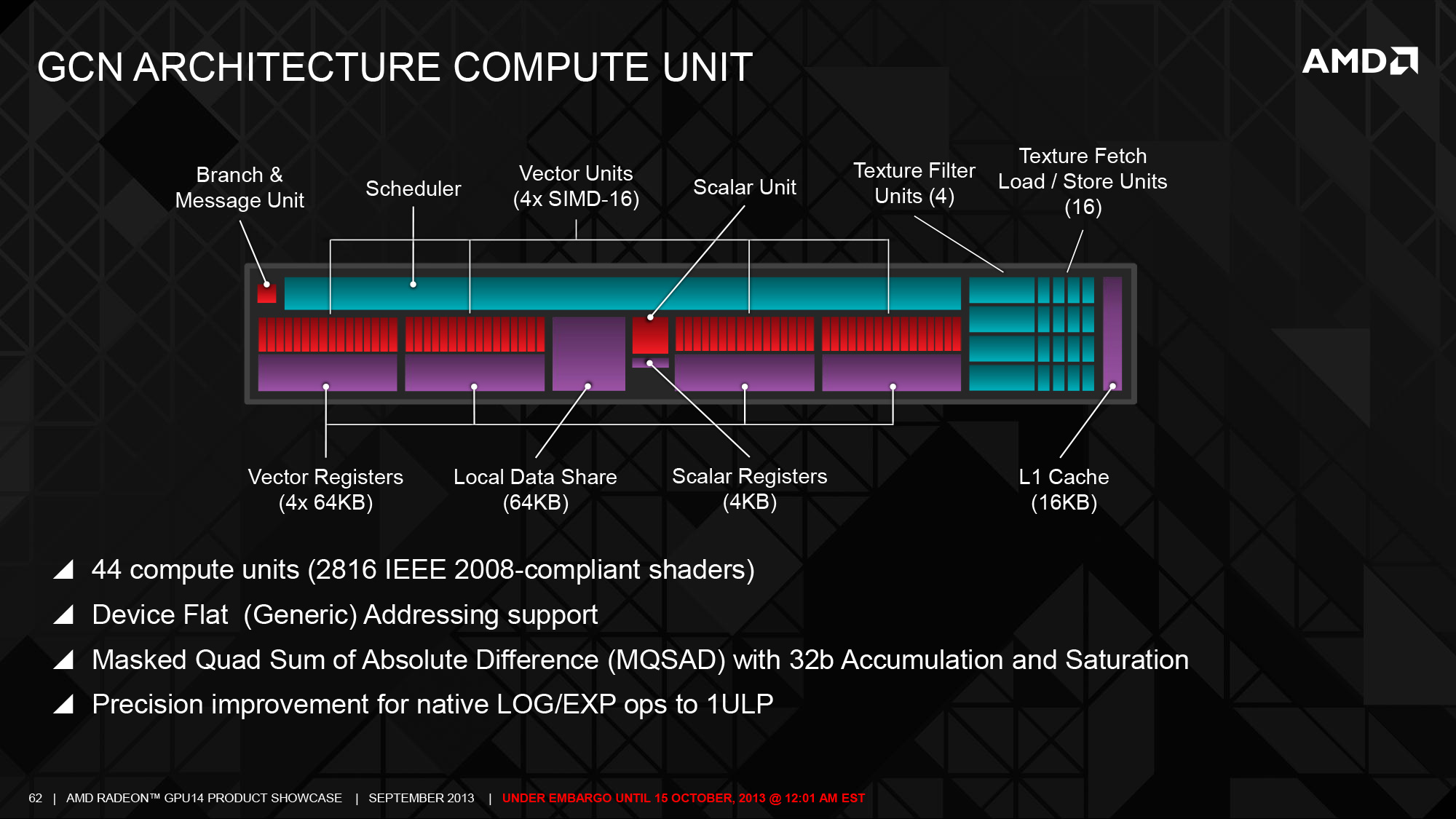
AMD 在設計 GCN 架構的時候將純量運算與向量部分分開,前者作為獨立的純量運算單元而後者實際上是以「多個 SIMD 組」來達成「MIMD 架構」的配置 (每一組 Vector SIMD 基本上仍然是走 SIMD 架構設計的風格,每個時脈可以處理 4 波 64 FMAD 向量運算),因每組 CU 包含了四組 Vector SIMD,使得每個時脈可以處理四個 (可能來自不同應用程式) 指令而達到 MIMD 架構的效果。
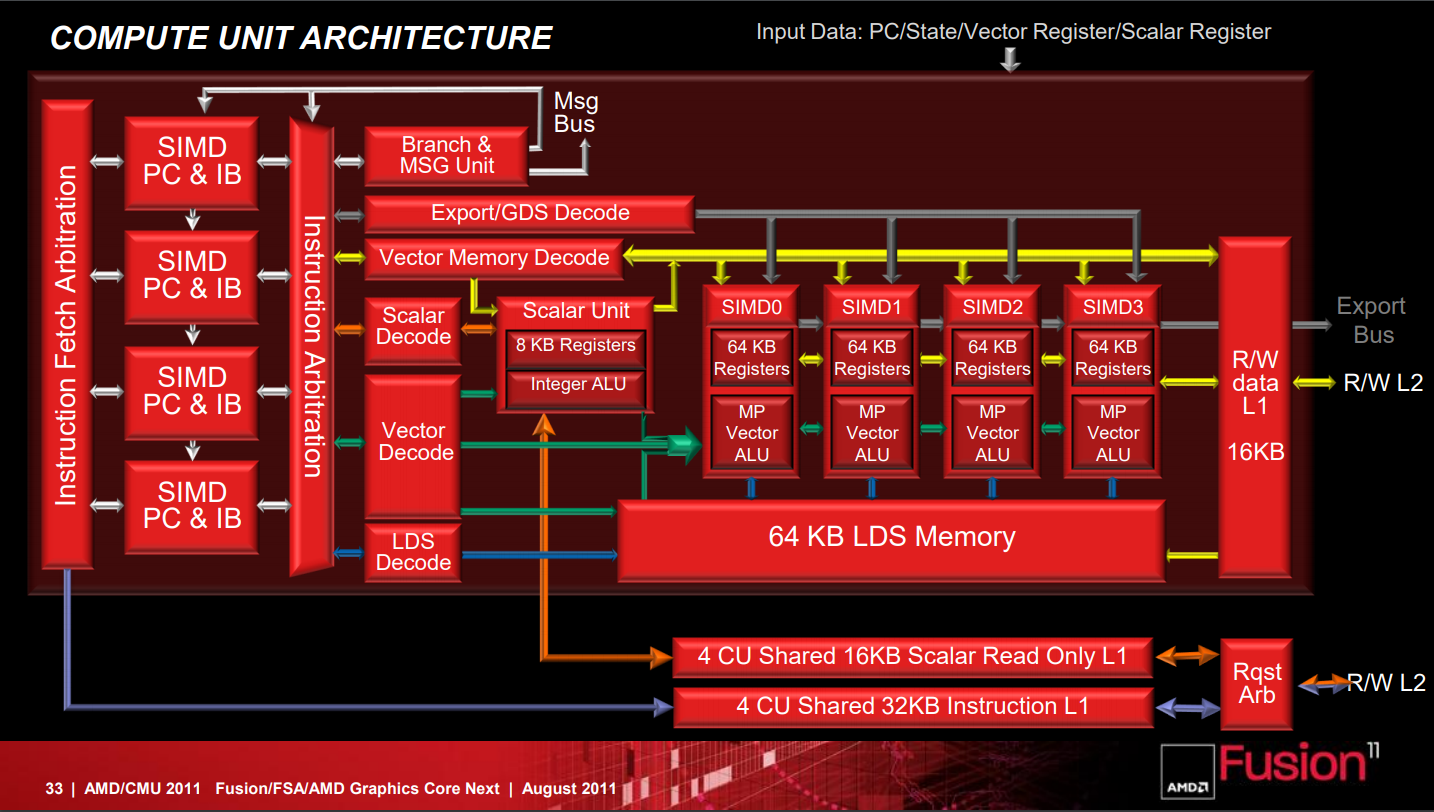
這與 NVIDIA 的架構當中每組 CUDA Core 之間各自作為獨立的個體存在與獨力執行運算工作的作法顯然並不相同,但仍然可以解決 VLIW 架構中如此吃重指令排序、編譯器優化與 VLIW 利用率的問題 (儘管以往在相對單純的圖形運用中這不算是太嚴重的問題,但隨著通用運算等蓬勃發展的新應用所包含的工作內容越來越複雜,要充分利用 VLIW 架構硬體的困難度也隨之快速飆升,這樣的問題漸漸變得不可忍受,再加上高度吃重編譯器優化也使得針對 VLIW 架構開發的軟體難免會受制於特定的程式語言與編譯器)。

以第一代 GCN 架構產品來說,每組 CU 當中至多包含了四組 SIMD Array 向量運算單元 (每組 SIMD Array 中有 16 個 ALU,因此每組 CU 包含了 64 個 ALU)、四組純量運算單元、排程器、分支單元、快取、材質單元、共用資料暫存區 (64 KB) 向量暫存器 (4 組,各 64 KB) 與純量暫存器 (8 KB)。
記憶體階層架構調整 (全域資料共享 GDU)
與 NVIDIA 的 Fermi 架構相似,AMD 在設計 Graphics Core Next 架構的時候為了因應通用運算需求的提升因此針對記憶體階層架構進行了一系列的調整,可以說是 AMD 歷來對其 GPU 記憶體階層架構進行最大變革的一次 (實際上很大程度也是為了 AMD 當時的 FUSION 戰略-即後來的 APU 而如此為之)。
除了在 CU 當中配有 8 KB 的純量暫存器、64 KB 的本地資料共享記憶體、16 KB 的 L1 可讀寫快取 (以往 Terascale 當中對 L1 快取只能進行讀取而不能寫入) 之外,每組 SIMD Vector 都提供了 64 KB 的向量暫存器。
至於 L2 快取的部分則是與記憶體控制器成對配置,每組記憶體控制器都對應了 64 位元頻寬的匯流排與 64 KB 或 128 KB 的 L2 快取記憶體,而全部的 L2 快取記憶體 (均為 write-back) 為共享關聯因此所有 CU 都能夠在 L2 快取當中取得相同的資料,可以有效降低 CU 與顯示記憶體索取資料的過程中所需付出的時間代價。
然而在 GCN 架構的記憶體階層體系當中最大的特性或許是透過 IOMMU 虛擬化技術得以將顯示記憶體轉化為 x86 架構虛擬記憶體,讓處理器得以與 GPU 更快速的交換資料,有效提供在通用運算方面的資訊吞吐量。

通用運算功能加強
除此之外 GCN 架構當中還針對通用運算用途加入了一系列改進,例如從以往僅能提供錯誤偵測的 EDC 支援提升到提供對 ECC 錯誤更正的完整支援 (顯示記憶體與各階快取均支援 ECC)、納入雙精度福點運算運算的支援能力等。
第一代 GCN (Southern Islands 南方群島)
- 推出日期:2012 年 01 月
- 所屬系列編成:Radeon HD 7000 系列、HD 8000 系列、RX 200 系列、RX 300 系列、RX 400 系列、RX 500 系列
- API 支援:DirectX 11.1、OpenGL 4.5、OpenCL、Mantle
- Shader Model 支援:SM 5.0
第一款支援 DirectX 11.1 的 GPU
在 Southern Islands 這一世代,AMD 再次超前 NVIDIA 推出了世界上第一款支援 Direct3D 11.1 的 GPU (NVIDIA 直到 Kepler 推出才提供 Direct3D 11.1 的支援,而且被 AMD 踢爆 Kepler 並無法完整支援 Direct3D 11.1 的所有特色),然而 AMD 這次並沒有再次如同 DirectX 11 當時般取得太大的優勢,主要的原因有三:
- DirectX 11.1 相較於 DirectX 11 而言改進有限
相較於 DirectX 11 來說 DirectX 11.1 只引入了十多項非常細微的改進,除了納入原生的 3D 立體影像 API (以往絕大多數廠商會用其他方式實作)、延遲渲染貼圖 (TBDR,主要用於行動裝置與低功率裝置)、目標獨立光柵化 (TIR,是 DirectX 11.1 唯一需要硬體支援的功能)、納入對雙精度浮點運算的完整支援之外並沒有太多顯著的特色。 - 搭配 DirectX 11.1 的 Windows 8 並不成功
眾所皆知當年 Windows 8 並不是一款成功的作業系統,因此軟體層面上支援 DirectX 11.1 的電腦數量根本不多。 - 基於 DirectX 11.1 的遊戲甚少
考慮到 NVIDIA 的 GPU 並不支援 DirectX 11.1,搭配 DirectX 11.1 的 Windows 8 也不成功,能夠享受 DirectX 11.1 改進的用戶相當有限的情況下,許多遊戲廠商根本也不願意在遊戲當中導入 DirectX 11.1 提供的新技術。
第一款支援 PCI Express 3.0 的 GPU
同時 Southern Islands 系列也是世界上第一款支援 PCI Express 3.0 介面的 GPU,相較於 PCI Express 2.0 來說 PCI Express 3.0 的頻寬由 5 GT/s 提升為 8 GT/s,由於 Southern Islands 推出的時間點正好與 Intel 發佈支援 PCI Express 3.0 的 Sandy Bridge-E 平台之時間相近,因此在市場上成為唯一支援 PCI Express 3.0 的選擇。
在當時由於遊戲用途的頻寬需求並不吃緊,基本上 PCI Express 2.0 介面提供的傳輸速率就已經足敷使用,加上初期只在 HEDT 高階平台上出現,因此 PCI Express 3.0 在個人市場的推動速度並不快,但在通用運算領域由於 GPU 會經常需要與 CPU 交換資料,因此 PCI Express 3.0 所帶來的額外頻寬就能發揮效用了。
第一款採用 28 奈米製造工藝的 GPU
同時 Southern Islands 也是世界上第一款使用台積電 28 奈米製造工藝的 GPU (NVIDIA Kepler 也採用了相同的製程),台積電在進入 28 奈米製程時代時首次使用了 High-K Metal Gate 技術與 Gate-Last 技術 (Intel 則是在 45 奈米製造工藝上引入這兩項特性),比起上次轉入 40 奈米製程的時候遭遇了許多額外的困難。
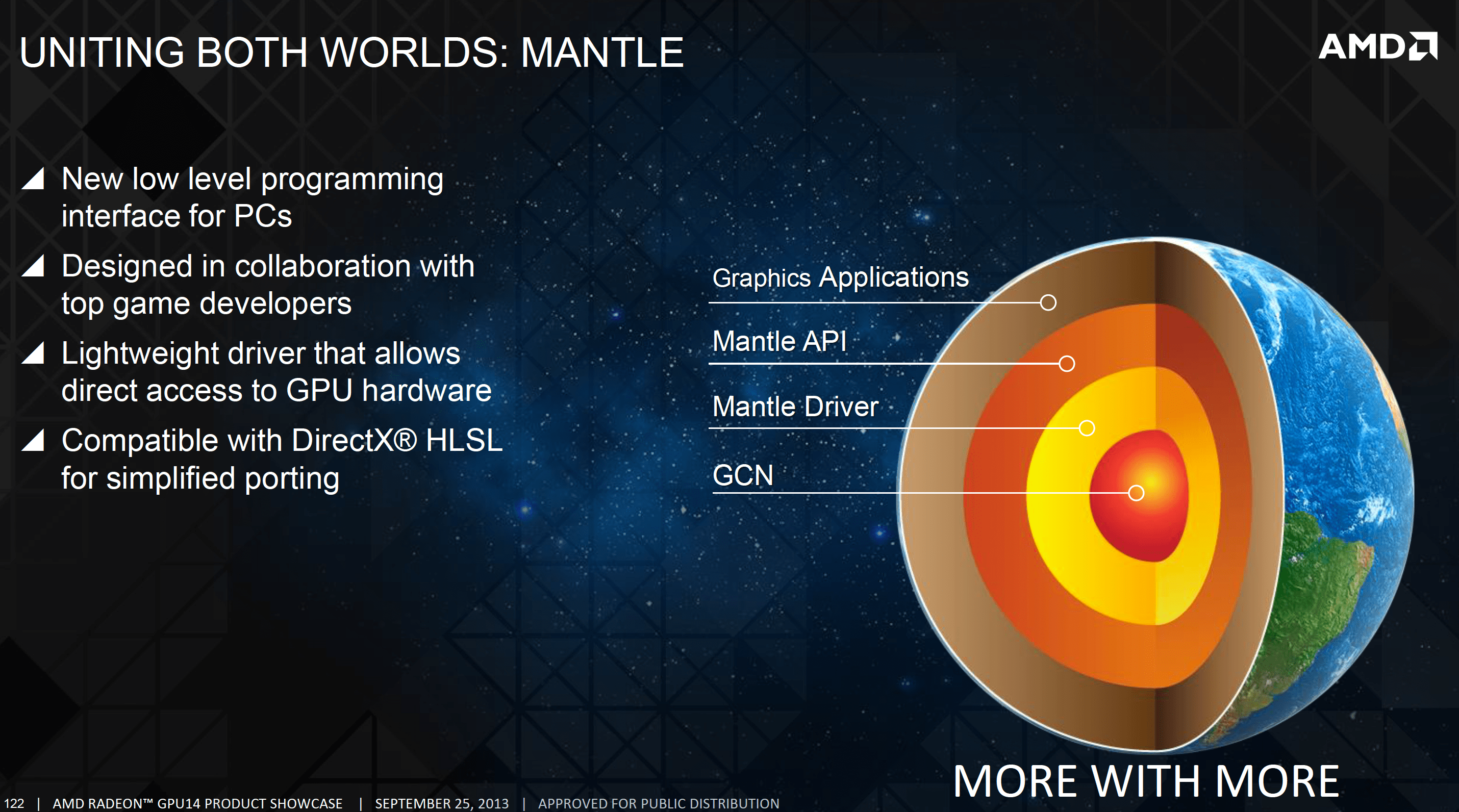
第一款支援 Mantle API 的 GPU
Mantle 是由 AMD 與 DICE 合作提出的一款 3D 圖形 API,主要是作為 DirectX 與 OpenGL 的補充並且針對 GCN 架構特別優化因而可以更充分發揮 GCN 架構 GPU 的性能,當初原先希望透過 AMD 掌握各家遊戲機繪圖晶片供應商地位的優勢來推動,但最終 AMD 在 2015 年宣佈放棄 Mantle API 並建議開發者轉用 Vulkan、DirectX 12 等 API。
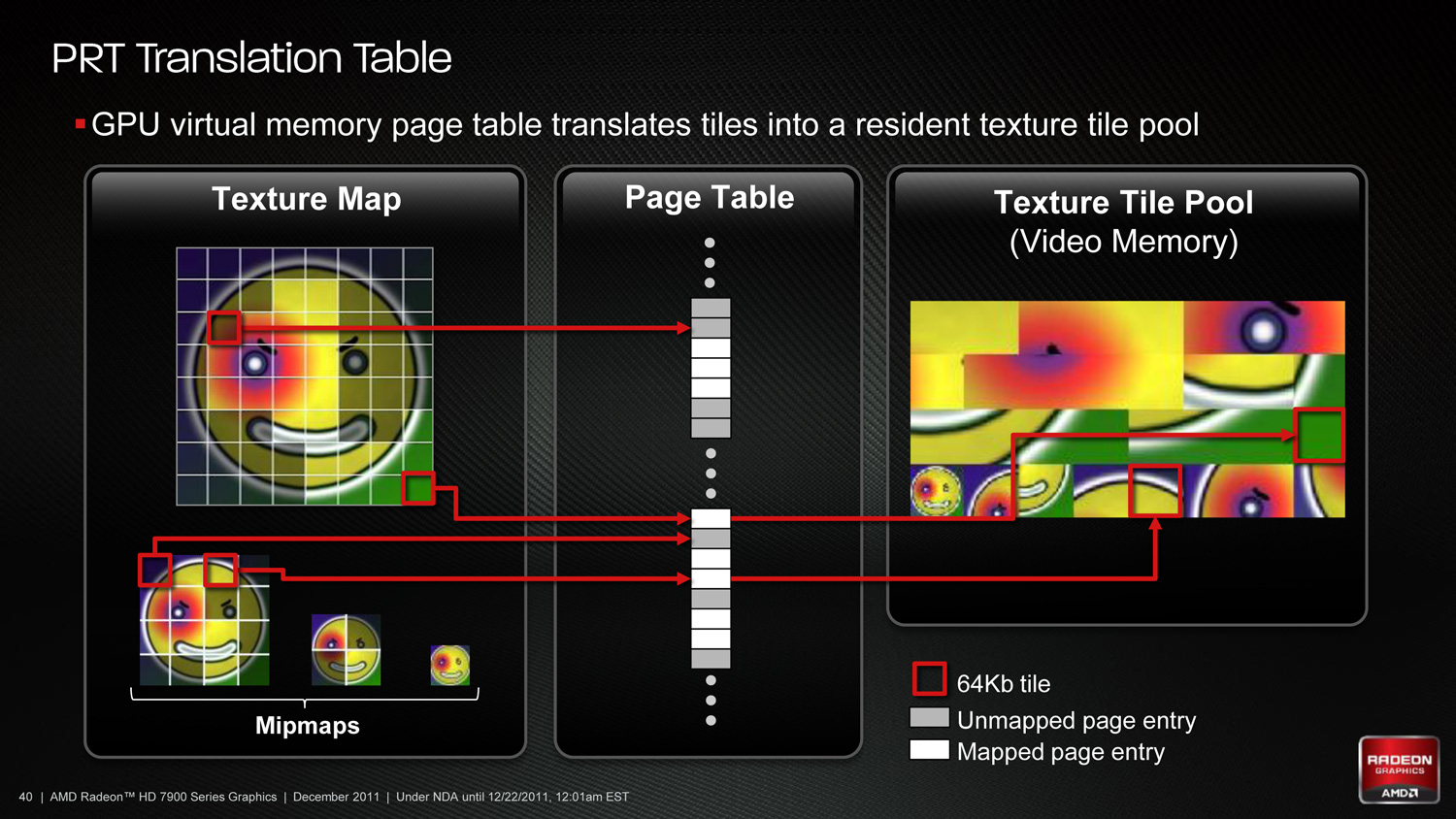
部分儲存材質 Partially Resident Textures (PRT)
在第一代 GCN 架構當中還引入了一項稱為 Partially Resident Textures (PRT) 的超大材質處理技術,這項技術的概念源自於 id software 所發展的 Megatexture 技術 (Megatexture 是以 OpenGL 3.2 API 軟體實作,而 PRT 則是硬體實作),主要是允許 GPU 可以只將大型的材質貼圖分割為數個部分 (tiles),在應用程式不會需要所有材質貼圖時,只把會使用到或相關聯的材質貼圖載入到記憶體中,其餘部分則是略過或只載入較低解析度的版本 (NVIDIA 也有類似技術,稱為 UltraShadow)。

除此之外 Southern Islands 所包含的 PRT 技術還運用了先前曾經提到 GCN 架構可以運用 x86 虛擬記憶體功能將顯示記憶體對應到系統的記憶體分頁當中,因此在處理大型材質貼圖的時候可以不必經過相對而言慢上許多的系統記憶體,而是可以直接對應到較快的顯示記憶體上。
HDMI 1.4a 支援
而在輸出部分 Southern Islands 系列則加入了對 HDMI 1.4a 標準的支援,因此得以支援 4K 顯示輸出與高達 120 Hz 的 3D 顯示器輸出功能。

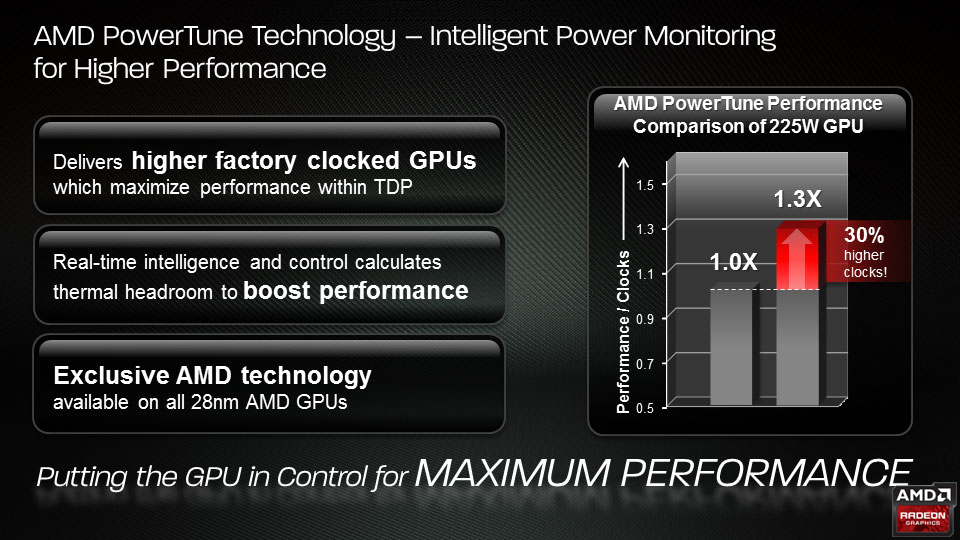
PowerTune 動態超頻技術
在 Southern Islands 當中 AMD 與前代產品同樣引入了 PowerTune 的動態超頻技術,透過即時監控 GPU 耗電與 TDP 進行動態電壓、時脈調控來允許 GPU 在需要強大性能的時候暫時以高於預設時脈的速度運作。
ZeroCore Power 省電技術
Southern Islands 系列最後一項要特別提及的特色就是被 AMD 稱為 ZeroCore Power 的省電技術,這項技術主要是以壓低 GPU 的待機耗電為主要目的,最低可以將顯示卡的待機耗電量壓低到 3W (GPU本身可以達到近乎 0 耗電)。

不過這項功能真正最重要的特色其實是體現在 CrossFire 多顯示卡系統上,ZeroCore Power 技術可以允許系統依據當下 GPU 資源的使用情形來動態將其他 GPU 切換到休眠模式進而達到降低風扇噪音與耗電量的效果。

Tahiti 核心
首波 Southern Islands 系列的核心一共有 Tahiti、Pitcairn 與 Cape Verde 三款,其中 Tahiti 是針對高階遊戲市場推出的產品,同時也是 Southern Islands 系列產品當中最完整的核心。


Tahiti 核心首次在 2012 年 01 月推出,主要用於 HD 7900 與 HD 7800 系列,首發時的型號為 HD 7970 (搭載 Tahiti XT 完整版本核心,包含 32 組 CU、2,048 個 SP、提供 384-bit GDDR5 記憶體支援,時脈為 925 MHz) 與 HD 7950 (採用 Tahiti Pro 核心,只包含 28 組 CU、1,792 個 SP、提供 384-bit GDDR5 記憶體支援,時脈為 800 MHz),而在同年下半年,得益於台積電製程的穩定,再進一步推出時脈提升後的 HD 7970 GHz Edition (時脈拉高至 1000/1050 MHz) 與 HD 7950 Boost (時脈拉高至 850/925 MHz)。

而除了 HD 7900 系列之外,還有一張被歸入 HD 7800 系列的 HD 7870 XT (時脈 925/975 MHz) 實際上也是採用 Tahiti 核心 (其餘 HD 7800 系列產品多採用中階的 Pitcairn 核心),但 CU 的數量被進一步刪減到 24 組,記憶體頻寬也只剩下 256-bit (連帶 L2 快取也跟著減少)。

除了最初的 HD 7900/HD 7800 系列之外,實際上 Tahiti 核心的壽命非常的長,在 2013 年初先是由 HD 7950 Boost 更名為 HD 8950、HD 7970 GHz Edition 更名為 HD 8970,後來 AMD 又將 HD 7950 Boost 的時脈小幅調整之後再次更名為 R9 280 (827/933 MHz)、HD 7970 GHz Edition 的時脈小幅調降後更名為 R9 280X (850/1000 MHz),然而基於 Tahiti 核心的眾多產品之中最為有趣的應該就是當初拖了很久才正式公布與上市的 HD 7990 了。

Pitcairn 核心
相較於 Tahiti 核心而言,面向中階市場的 Pitcairn 的規模與面積均較小,除了 CU 的數量由 32 組刪減至 20 組,記憶體控制器的數量由 6 組調降為 4 組之外,絕大多數特性都與 Tahiti 核心相仿。

值得注意的是 AMD 並沒有刪減 Pitcairn 的渲染輸出單元與其他共同電路,Pitcairn 最早在 2012 年 03 月以 HD 7870 GHz Edition (採用 Pitcairn XT 核心,只包含 16 組 CU、1,024 個 SP、提供 256-bit GDDR5 記憶體支援,時脈為 1,000 MHz) 與 HD 7850 (採用 Pitcairn Pro 核心,只包含 20 組 CU、1,280 個 SP、提供 256-bit GDDR5 記憶體支援,時脈為 860 MHz) 之名上市。

Pitcairn 核心的情況與 Tahiti 核心相當相似,首先是在 2013 年初先由 HD 7870 GHz Edition 更名為 HD 8870,後來 AMD 又將 HD 7850 的時脈小幅調整之後再次更名為 R7 265 (900/925 MHz)、R7 370 (975 MHz) 與 R9 370 (950/975 MHz,被另外命名為 Curacao Pro)、HD 7870 GHz Edition 的時脈小幅調降後更名為 R9 270 (900/925 MHz)、R9 270X (1000/1050 MHz) 與 R9 370X (1000 MHz)。

Table of Contents
Cape Verde 核心
面向主流市場的 Cape Verde 核心則是首波 Southern Islands 核心當中規模最小的,至多只有 10 組 CU 與 640 個 SP,記憶體頻寬則進一步被折半為 128 bit 並砍除了一半的渲染輸出單元。

Cape Verde 最早在 2012 年 03 月以 HD 7770 GHz Edition (採用 Cape Verde XT 核心,只包含 10 組 CU、640 個 SP、提供 128-bit GDDR5 記憶體支援,時脈為 1000 MHz)、HD 7750 (採用 Cape Verde Pro 核心,只包含 8 組 CU、512 個 SP、提供 128-bit GDDR5 記憶體支援,時脈為 800/900 MHz) 與 HD 7730 (採用 Cape Verde LE 核心,只包含 6 組 CU、384 個 SP、提供 128-bit GDDR5 記憶體支援,時脈為 800MHz) 之名上市。

隨後在 2013 年初 AMD 先將 HD 7770 GHz Edition 更名為 HD 8760,後來 AMD 又將 HD 7770 再次更名為 R7 250X (1000 MHz)、HD 7750 更名為 HD 8730 (800 MHz)、R7 450 (1050 MHz) 。

Oland 核心
至於最後一款採用第一代 GCN 架構的處理器就是定位最低也最為精簡的 Oland 核心了,Oland 核心首次在 HD 8000 系列出現,以 HD 8570 與 HD 8670 型號上市,此二型號均只有 6 組 CU、384 個 SP,記憶體控制器也只有 128-bit 的頻寬,主要差異則出現在前者時脈為 800 MHz,而後者則為 1000 MHz。
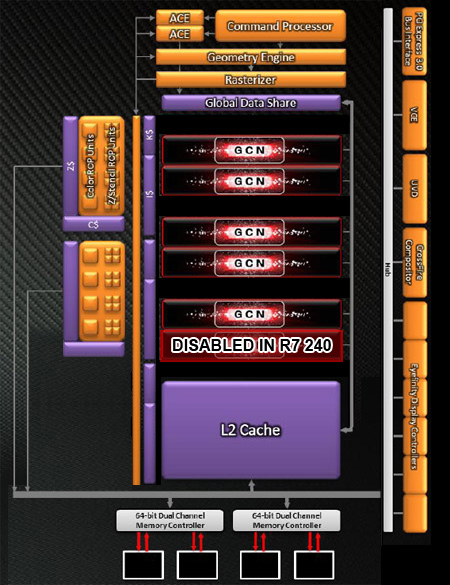
隨後 AMD 又在 2013 年以 Oland 核心分為三款產品,依序分別為 R5 240 (採用 Oland 核心,只包含 5 組 CU、320 個 SP、提供 128-bit GDDR5/DDR3 記憶體支援,時脈為 730 MHz/780 Mhz)、R7 240 (採用 Oland Pro 核心,只包含 5 組 CU、320 個 SP、提供 128-bit GDDR5/DDR3 記憶體支援,時脈為 730 MHz/780 Mhz,後又改名為 R5 330) 與 R7 250 (採用 Oland XT 核心,只包含 6 組 CU、384 個 SP、提供 128-bit GDDR5/DDR3 記憶體支援,時脈為 1000 MHz/1050 Mhz,後又依時脈差異更名為 R5 340、R7 340、R7 350 三款)。

而在 2016 年,Oland 核心終於迎來了最後一次更名,作為 R5 430、R5 435、R7 430、R7 435 四種型號推出,而 R5 430 與 R7 430 則具備較高的 CU 數量 (6 組)。
第二代 GCN (Sea Islands 海島)
- 推出日期:2013 年 03 月
- 所屬系列編成:Radeon HD 7000 系列、HD 8000 系列、RX 200 系列、RX 300 系列、RX 400 系列
- API 支援:DirectX 11.1、OpenGL 4.5、OpenCL、Vulkan
- Shader Model 支援:SM 5.0
儘管 AMD 在 2013 年曾經表示「2013 年的產品線將會維持穩定」因此被國外媒體誤會為 AMD 不打算在 2013 年推出任何新款 GPU,但實際上在 2013 年當中 AMD 仍然另外推出了兩款核心,而且這兩款核心在功能特性上與第一代 GCN 架構略有一點差異,因此當時被媒體稱為 GCN 1.1 架構 (其實這在 2013 年造成了一個蠻尷尬的情況,畢竟有極少數 Sea Islands 才有的特性在 2013 年 AMD 的當家旗艦上沒有,反而中階產品卻支援,類似的情況後來在 NVIDIA 的 Maxwell 架構時期也發生過)。

PowerTune 技術改進
在第二代 GCN 架構當中主要的改進並沒有很多,其中之一是在初代 GCN 架構與 Terascale 後期產品當中引入的 PowerTune 動態超頻技術獲得了改進,以往在 Terascale 與 Southern Islands 當中 PowerTune 只有四階動態控制 (低檔、中檔、高檔與超頻),但實務上由於檔位之間的落差很大,因此 GPU 從高檔與中檔之間切換的機會甚少 (通常都在高檔當中的各個次檔位當中移動),在大多數情況下 GPU 並沒有辦法來得及將電壓下調至中檔以達到省電的效果而使得 PowerTune 功能在省電方面效果非常有限。
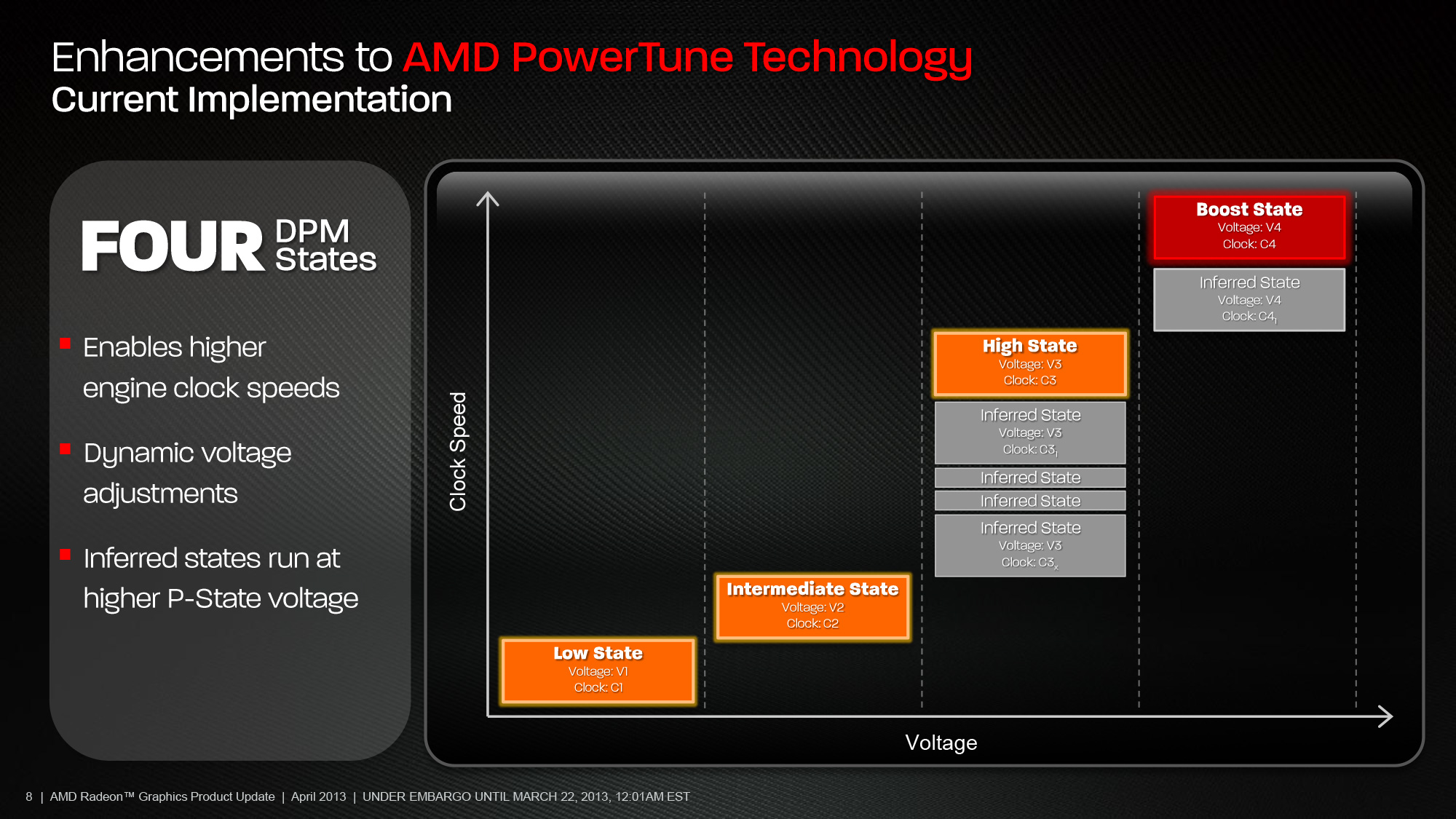
在 Sea Islands 世代 AMD 則將 PowerTune 的切換階數增加到八個檔位,透過細分檔位與加快電源管理單元的處理速度 (高達五倍快) 來讓 PowerTune 功能可以更快速、即時的根據當下的情況動態調整 GPU 的電壓與時脈,使 PowerTune 帶來的省電效果更加明顯。
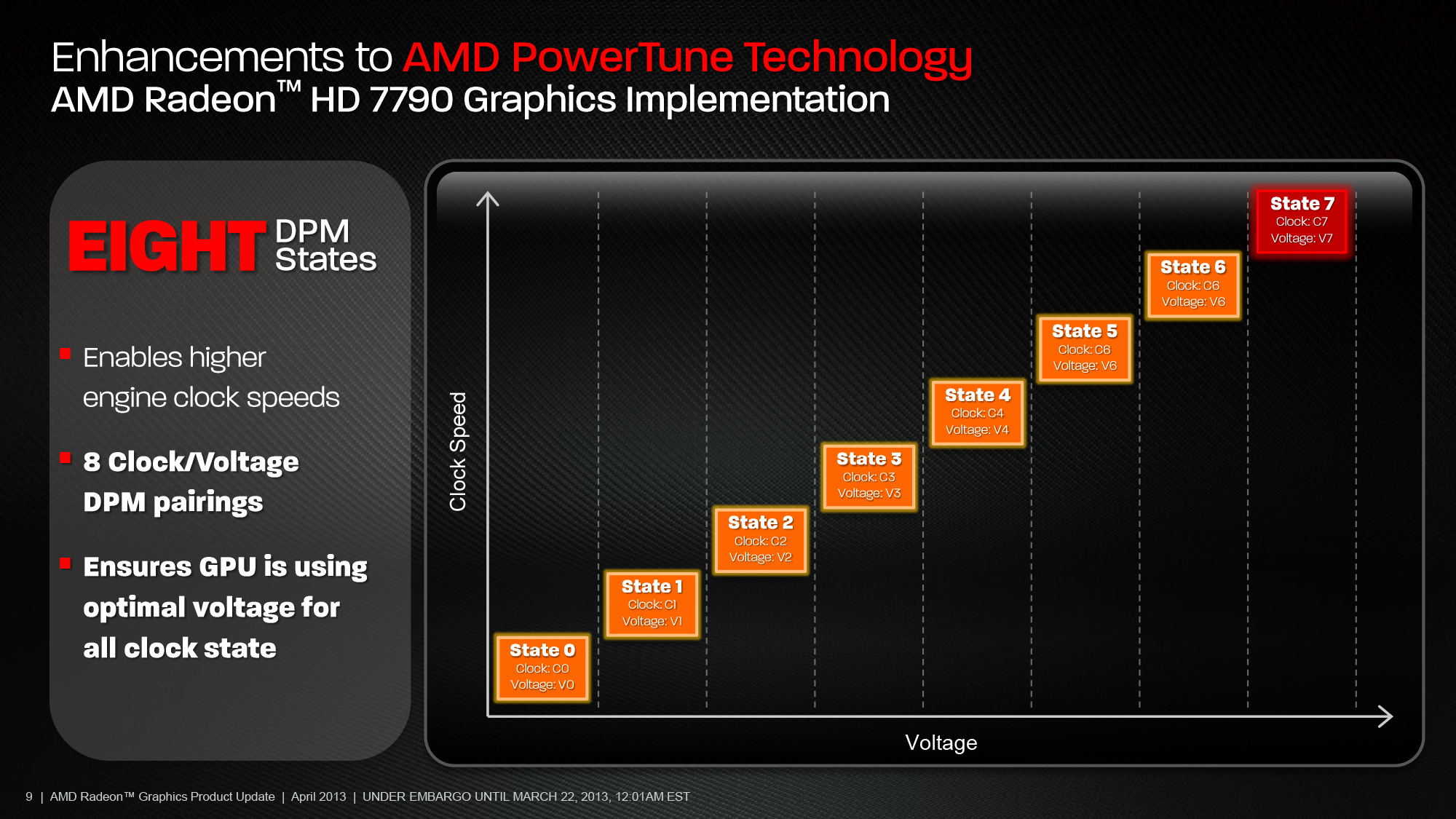
此外,在新版 PowerTune 功能當中動態調整 DPM 檔位的一句除了原先的 GPU 使用率、熱功率 (TDP) 之外,還額外新增了一項稱為熱設計電流上限 (TDC Limits) 的指標 (計算依據為通過 GPU 的電流大小)。
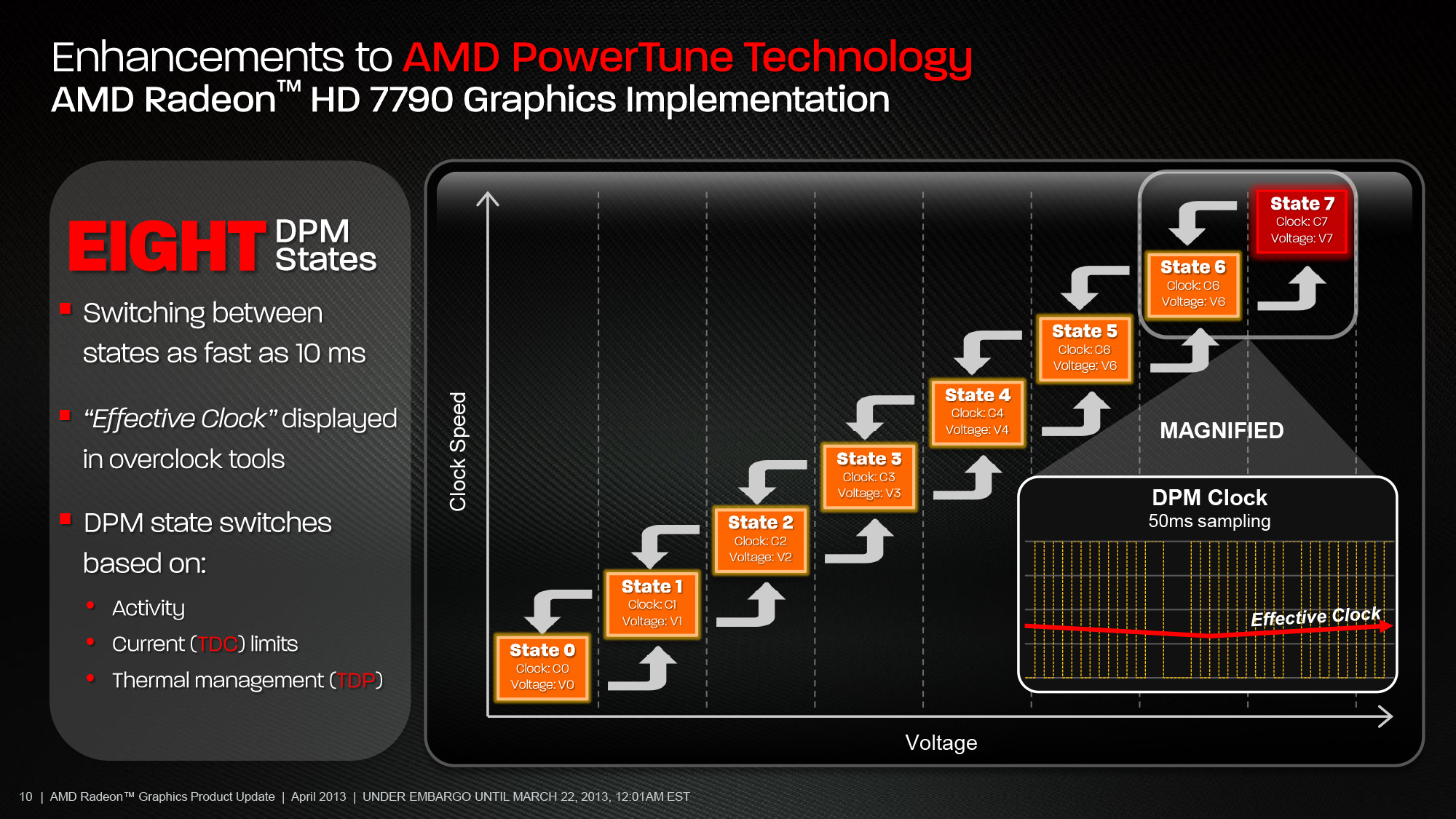
通用運算與前端單元的強化
另一項在 Sea Islands 當中引入的主要改進則是在指令集架構 (Instruction Set Architecture, ISA) 中納入了對通用位置定址、MQSAD 指令與一些雙精度向量運算相關的指令的支援與前端運算單元的改進,儘管前者主要是針對程式開發者因此一般用戶比較沒有辦法感受,但這對於 AMD 當時希望發展的異質運算架構 (HSA) 來說可說是至關重要。
至於在前端單元的改進方面則主要出現在異步運算引擎 (ACE) 上,ACE 是 GCN 架構當中負責執行緒排程與發派工作給 CU 的單位,與 GCN 架構 GPU 的資源調度效率有著至關重要的影響 (實際上後來幾代 GCN 架構當中幾乎都免不了針對 ACE 進行強化或增加數量),在第二代 GCN 架構當中允許 GPU 可以包含更多組的 ACE,每組 ACE 也都能支援更長的任務佇列,這是第二代 GCN 架構產品當中除了 CU 數量之外性能提升的主要來源。
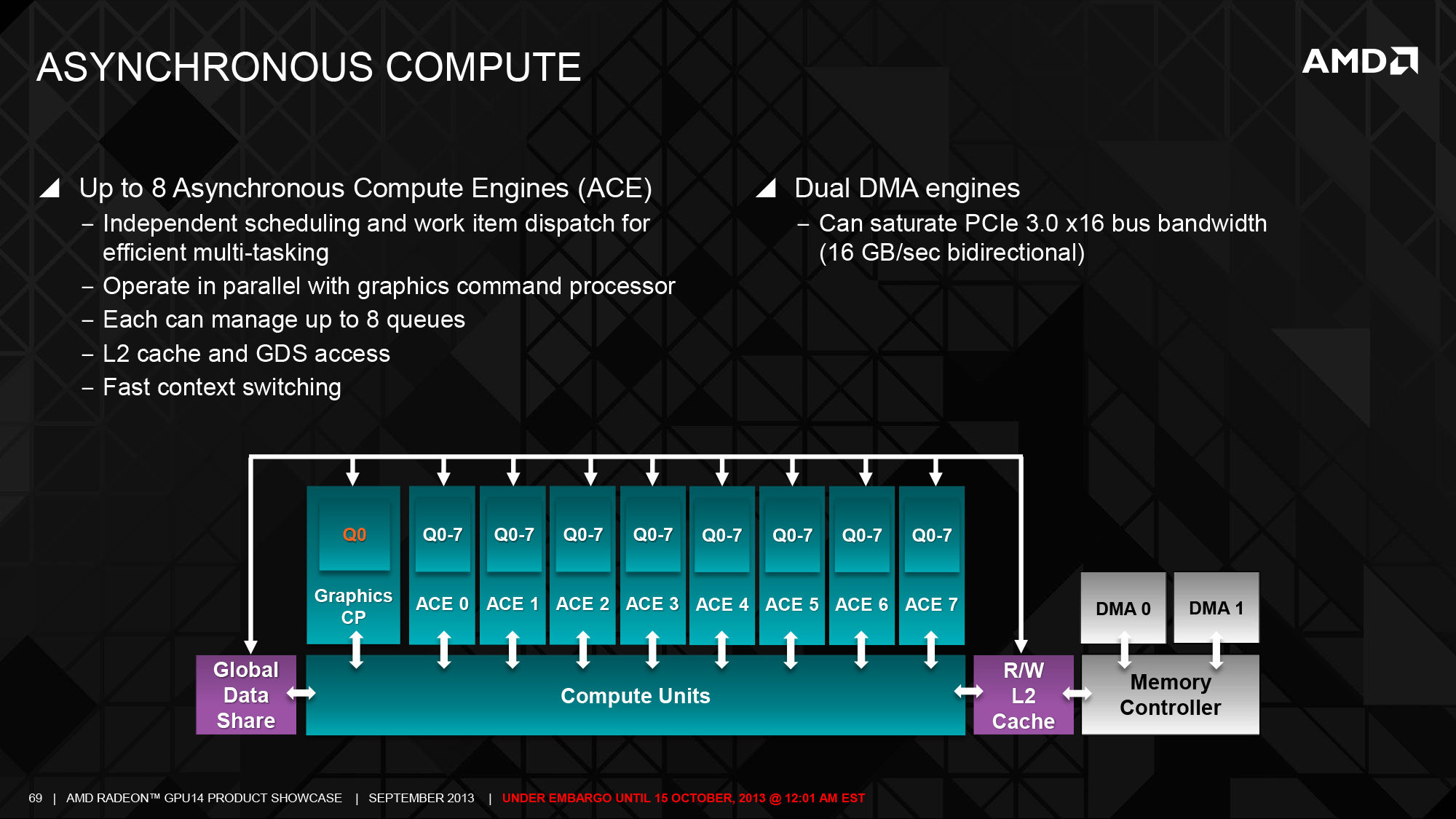
CrossFire 改進,捨棄 CF 連接器
在第二代 GCN 架構當中 CrossFire 也獲得了一些改進,透過改進 GPU 上的硬體 DMA 引擎 (設計改進並由一組改為兩組) 使多顯示卡偕同運作不再像過去一般需要依賴 CrossFire 連接器的協助,而是可以透過系統本有的 PCI Express 匯流排直接達成類似的目的,由於 PCI Express 通道的頻寬遠比以往的 CrossFire 連接器要來得大,因此可以避免 HD 7990 時代因 CrossFire 連接器頻寬不足而導致的跳格、掉圖問題,並且比起以往而言多卡 CrossFire 的性能衰退其實是大幅減少的。

但這樣的做法實際上也造成了新的問題,因 PCI Express 通道為與其他 GPU 資料共用的通道,與過去 CrossFire 連接器使用專屬的點對點通道不同,因此傳輸延遲較先前的設計略有增加,且在通道發生阻塞的時候可能會影響 CrossFire 的性能與穩定性。
Bonaire 核心
基於第二代 GCN 架構的桌上型 GPU 核心實際上只有兩款,其中第一款採用第二代 GCN 架構的 GPU 是定位於主流市場的 Bonaire 核心。

精確來說的話 Bonaire 實際上是定位在 Pitcairn 與 Cape Verde 之間的產品,主要是為了解決 Cape Verde 與 Tahiti、Pitcairn 之間性能落差過大造成中間出現空缺的問題而生。
Bonaire 的配置大致上與 Cape Verde 非常相似,同樣採用由四組記憶體控制器組成 128 位元的記憶體頻寬與具備 16 組渲染輸出單元,至於 CU 的數量則略為增加了四組 (亦即多了 256 個 SP),最大的差異則是出現在前端處理單元的部分。
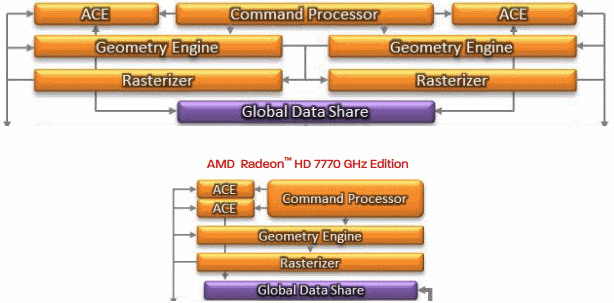
上圖當中出現的是 Bonaire (上方) 與 Cape Verde (下方) 的前端運算單元之比較,可以發現 AMD 當初在設計 Cape Verde 的時候刪除了一半的 Geometry Engine 與 Rasterizer,然而這正是 Cape Verde 與 Pitcairn 之間性能落差過大的主要原因,在 Bonaire 當中 AMD 就採用了與 Tahiti 與 Pitcairn 相同的前端設計了,得益於加倍的前端元件性能與 40% 的運算單元數量增長,因此 Bonaire 的性能比 Cape Verde 要好上不少,特別是在處理曲面細分的時候。

採用 Bonaire 核心的產品相較於其他 GCN 架構核心來說並不算多,首款產品為發佈於 2013 年 03 月的 HD 7790 (採用 Bonaire XT 核心,包含 14 組 CU、896 個 SP、提供 128-bit GDDR5 記憶體支援,時脈為 1000 MHz),而在同年九月則被改名為 HD 8770 再次推出。

與其他 GCN 架構的核心相似,Bonaire 在接下來幾代的 Radeon GPU 家族當中也都有更名產品推出,首先是 2013 年 08 月的 R7 260X (採用 Bonaire XTX 核心,包含 14 組 CU、896 個 SP、提供 128-bit GDDR5 記憶體支援,時脈為 1100 MHz)、2013 年 12 月的 R7 260 (採用 Bonaire 核心,包含 12 組 CU、768 個 SP、提供 128-bit GDDR5 記憶體支援,時脈為 1000 MHz)、2015 年 05 月的 R9 360 與 R7 360 (採用 Bonaire Pro 核心,包含 12 組 CU、768 個 SP、提供 128-bit GDDR5 記憶體支援,時脈為 1000 MHz/1050 MHz) 與 2016 年 06 月推出的 RX 455 (採用 Bonaire Pro 核心,包含 12 組 CU、768 個 SP、提供 128-bit GDDR5 記憶體支援,時脈為 1050 MHz)。
Hawaii 核心
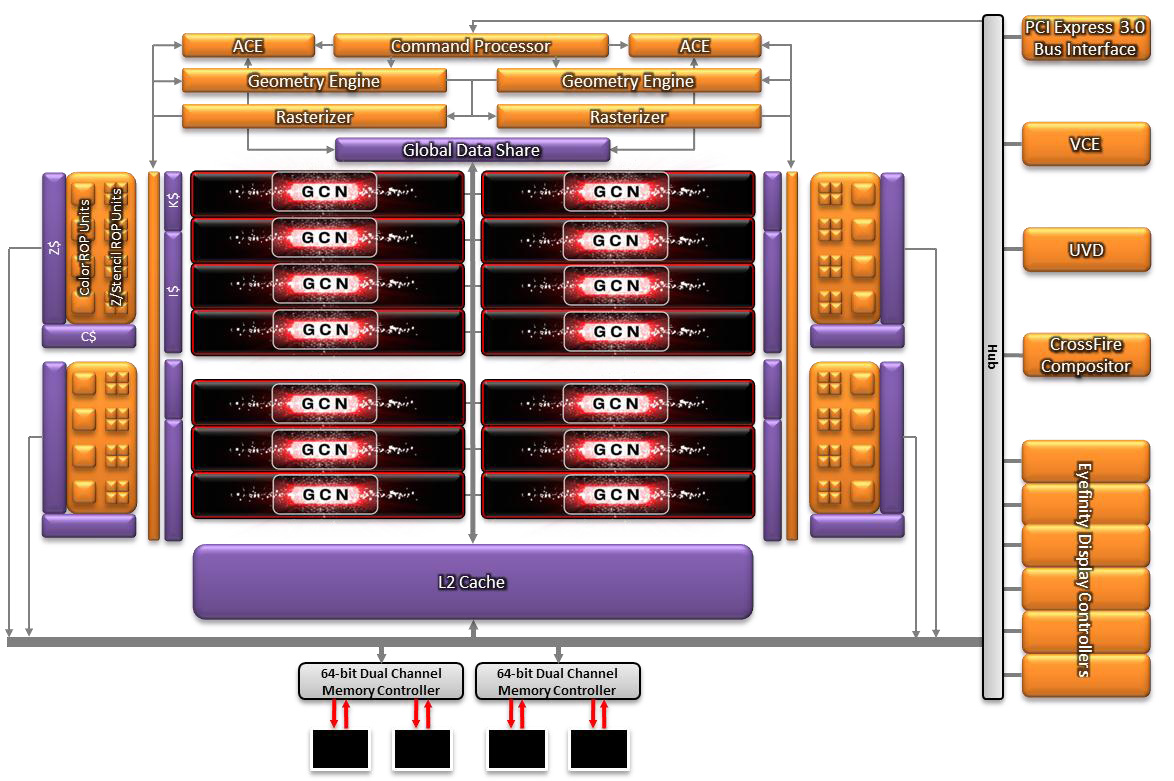
而第二代 GCN 架構的重頭戲實際上是面向頂級市場的 Hawaii 核心,Hawaii 是 AMD 在進入 GCN 架構時代之後的第一款大型 GPU 核心,同時也是在 R600 之後 AMD 所設計過規模最大的 GPU 核心,主要是為了迎戰 NVIDIA 推出的頂級 GPU 產品 GTX TITAN 而生,Hawaii 在面積上足足比先前的 Tahiti 要大上將近 25% (當然這一切得歸功於 TSMC 的 28 奈米製程優異的良率使得 Hawaii 核心成為可能) 並且在各方面的數量配置都出現了明顯的增長,性能更是出現了飛躍性的提升。
從架構圖上可以很容易注意到 Hawaii 核心的規模比起 Tahiti 要來得壯觀許多,不論是前端單元還是運算單元都出現了大幅度的數量增長,首先讓我們從明顯數量大增的前端單元開始看起。

在先前的 Tahiti 核心當中只使用了兩組異步運算引擎 (ACE),而在 Hawaii 核心當中一舉提升了四倍來到了整整八組之譜,再加上前面提過在第二代 GCN 架構當中每個 ACE 可以處理的運算佇列不再僅限於兩個指令,在 Hawaii 核心當中每個 ACE 可以處理的運算佇列可以長達八個指令之多 (八個 ACE 表示單一週期可以處理高達 64 個指令),這意味著 Hawaii 的前端單元處理、分派指令的吞吐量是 Tahiti 的 16 倍之多,這對於 Hawaii 核心的通用運算能力來說有著相當大的幫助 (可以有效提升 CU 的利用效率)。
接下來往運算單元的部分前進,在 Hawaii 核心發佈的時候 AMD 採用了類似於 NVIDIA 慣用 SMX 描述其 GPU 核心所包含的運算核心的方式,在 Compute Unit (CU) 上面加入了更高一層的 Shader Engine (渲染引擎) 概念,每組 Shader Engine 都包含了一組 Geometry Processor、一組 Rasterizer、L1 快取與一票 CU,此外 AMD 本次也將對應的渲染輸出單元納入 Shader Engine 當中 (可以在 1 組到 4 組間調整)。

不過與 NVIDIA 在縮減核心規模時只能砍掉整組 SMX 不同,AMD 可以透過減少每組 Shader Engine 當中所包含之 CU 的數量來達到類似目的卻有著保留四組 Shader Engine 當中的 Geometry Processor 與 Rasterizer 的好處,在 Hawaii 核心當中這些元件的數量都是 Tahiti 的兩倍之多,是 AMD 在 Terascale 後期產品之後首次針對這部分進行提升,對於曲面細分的性能有著很大的幫助。
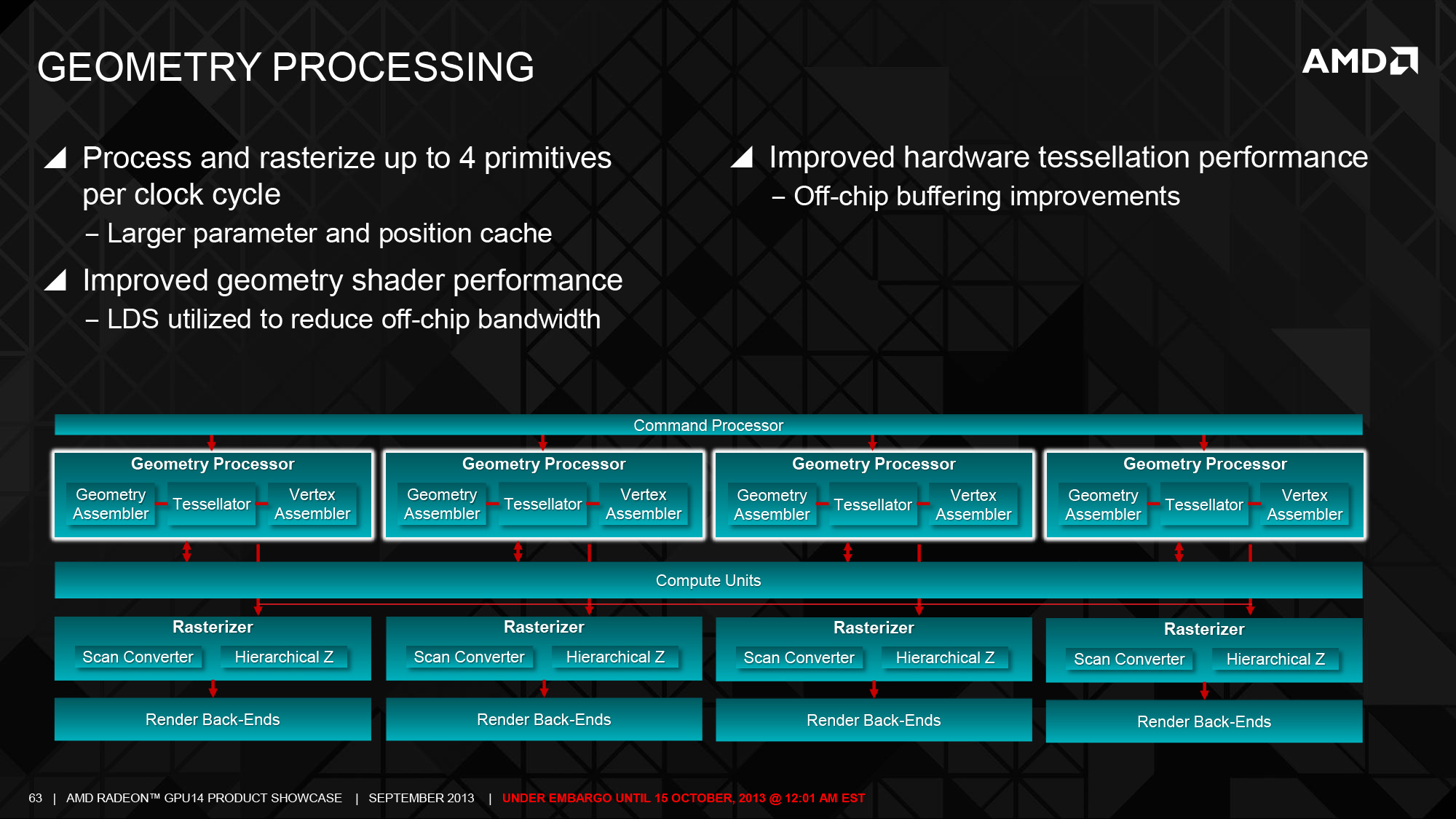
至於運算核心的部分呢,Hawaii 核心所包含的 CU 則是從 Tahiti 的 32 組提升到 44 組,因此 SP 的數量便從 2,048 個提昇到了 2,816 個之多,而在記憶體頻寬的部分由於記憶體控制器的數量進一步從 12 組增加到 16 組,因此記憶體頻寬也從 384-bit 提升到了驚人的 512-bit。

至於在產品的部分,由於 Hawaii 的定位相當高,因此基於 Hawaii 核心的產品種類並不多,首批採用 Hawaii 核心的產品為 R9 290X (採用 Hawaii XT 核心,包含 44 組 CU、2,816 個 SP、提供 512-bit GDDR5 記憶體支援,時脈為 1000 MHz) 與 R9 290 (採用 Hawaii Pro 核心,包含 40 組 CU、2,560 個 SP、提供 512-bit GDDR5 記憶體支援,時脈為 947 MHz) 兩款。

不過 Hawaii 核心同樣也在後來出現過幾次改名版本,包含了 2015 年的 R9 390 (改自 R9 290)、R9 390X (改自 R9 290X) 但基本上沒有本質上的差異。

最後要提到的是第二代 GCN 架構當中性能最強的產品,代號為 Vesuvius (維蘇威火山) 的 R9 295X2,由兩顆完整版 Hawaii XT 核心組成,而且最特別的是這次 AMD 在組合雙晶片版本的時候居然沒有降頻,反而是將時脈設定為小幅提高的 1018 MHz,而且還是歷來第一張公版標配水冷散熱器的顯示卡。

