

在上篇談了第一代與第二代 GCN 架構與相關的產品之後,接下來在本篇當中我打算接著把第三代與第四代 GCN 架構的各項改進一併寫完,如同先前曾經提過的,AMD 在 Graphics Core Next 架構發展完畢之後接下來直到現今最新的 Vega 架構 (即第五代 GCN 架構,但由於本篇連載規劃的時候 Vega 還沒有誕生,因此目前預計只會先撰寫前四個世代的介紹) 都是從第一代 GCN 架構衍伸與優化而來,因此在主體結構的部分大致上都是相同的。
第三代 GCN (Volcanic Islands 火山島)
- 推出日期:2014 年 09 月
- 所屬系列編成:RX 200 系列、RX 300 系列、RX 400 系列、RX 500 系列
- API 支援:DirectX 12.0、OpenGL 4.5、OpenCL、Vulkan
- Shader Model 支援:SM 6.0
在第二代 GCN 架構推出將近一年半之後,AMD 發佈了 GCN 架構的第二次改版,即當時被媒體稱為 GCN 1.2 架構的 Volcanic Islands (後來被 AMD 追認為第三代 GCN 架構),與第二代 GCN 架構的情況相似,基本上第三代 GCN 架構並沒有帶來甚麼根本上的變革。
將第二代 GCN 架構的改進引入高階市場
前面提過第二代 GCN 架構在第一代 GCN 架構的基礎上加入針對前端元件的配置使指令吞吐量提高、CrossFire 改走 XDMA、架構規劃中新增 Shader Engine 階層、強化版 PowerTune 動態超頻技術等改進,然而在第二代 GCN 架構當中僅有推出針對頂級旗艦市場的 Hawaii 與針對主流市場的 Bonaire 兩款,而原先第一代 GCN 架構當中擔綱高階市場的 Tahiti 則未有後繼,導致某些特性在高階的 R9 280、R9 280X 上未被支援,卻出現在較為低階的 R9 260 上的尷尬情況,因此在第三代 GCN 架構推出時,第一件做到的事情就是將這些特性引入到高階市場。
色彩差異壓縮技術
在第三代 GCN 架構當中 AMD 還針對渲染輸出單元的部分進行了一些改進,透過引入新的色彩差異壓縮技術使得 Volcanic Islands 在處理畫面時所需要的記憶體頻寬得以大幅降低 (在第三代 GCN 架構中記憶體控制器的數量有所減少,但根據 AMD 的說法實際上在性能上是成長的),根據 AMD 官方的說法,此項色彩壓縮技術可以提高將近 40% 的記憶體頻寬利用效率。

影像解碼、編碼能力強化
在第三代 GCN 架構當中 AMD 還引入了新的影像解碼、編碼單元 (AMD 在此之前實際上已經很久沒有碰過 Unified Video Decoder 這塊了),在此次更新之後 AMD 才終於追上 Intel 與 NVIDIA 的腳步,得以提供針對 4K H.264 FPS60 影片的硬體解碼支援,總算補上了 AMD GPU 無法完整支援 4K 硬體解碼的缺憾。
此外,與第二代 GCN 架構的情況相似,第三代 GCN 架構也在指令集架構中有所改進,主要是加入了半精度浮點運算與 16 位元整數運算相關的指令以強化在較低密度的 GPU 運算與影像處理時的省電效果 (不過實際上在個人電腦中使用到這類運算的機會並不多,一般來說遊戲所需的運算都以單精度浮點、32 位元整數為主,至於半精度與 16 位元整數運算則多見於行動裝置、SoC 設備上),並且增加了一些用於在 SIMD 通道之間分享資料用的資料平行處理指令。

Tonga 核心
與第二代 GCN 架構的情況相同,採用第三代 GCN 架構的核心也只有兩款,分別是面向高階市場準備接替 Tahiti 的 Tonga 與變得更大、更強、更複雜,主要是為了接替 Hawaii 的 Fiji,如同前面所提過的,基本上基於第三代 GCN 架構的 Tonga 核心就像是把 Hawaii 縮減到 Tahiti 的規模再加上一點優化之後得到的結果。

這點從 Tonga 的架構圖上應該也可以很容易看出來,乍看之下其實就只是 Shader Engine 變得比較短、記憶體控制器少了很多組的 Hawaii (這就是 AMD 為什麼要在第三代 GCN 架構當中加入新的色彩壓縮技術的原因)。

至於在產品的部分,基於 Tonga 核心的產品其實很少,而且僅見於 RX 200 系列與 RX 300 系列之中,最初出現在 2014 年 09 月發佈的 R9 285 (定位上接替 R9 280,性能與 R9 280X 依據項目互有優劣,採用 Tonga Pro 核心,包含 28 組 CU、1,792 個 SP、提供 256-bit GDDR5 記憶體支援,時脈為 918 MHz)。

隨後 AMD 又在次年將 R9 285 改名為 R9 380 推出,而完整版的 Tonga XT 核心則是要等到次年 11 月 AMD 才推出 R9 380X (採用 Tonga XT 核心,包含 32 組 CU、2,048 個 SP、提供 256-bit GDDR5 記憶體支援,時脈為 970 MHz) 才出現,而且僅此一款。

Fiji 核心
比起 Tonga 核心來說,第三代 GCN 架構當中比較具有可看性的其實是用於取代 Hawaii 的大核心 Fiji,某種程度上來說 Fiji 其實就是 Hawaii 核心的終極擴充版本,再次打破 Hawaii 的紀錄成為 R600 之後 AMD 歷代面積最大的 GPU。

實際上 Fiji 也是截至目前為止 AMD 所推出過面積與規模最大的 GPU 核心,與 NVIDIA 的 GM200 相同,一舉達到了 28 奈米製造工藝下 TSMC 當時所能接單生產的面積上限。

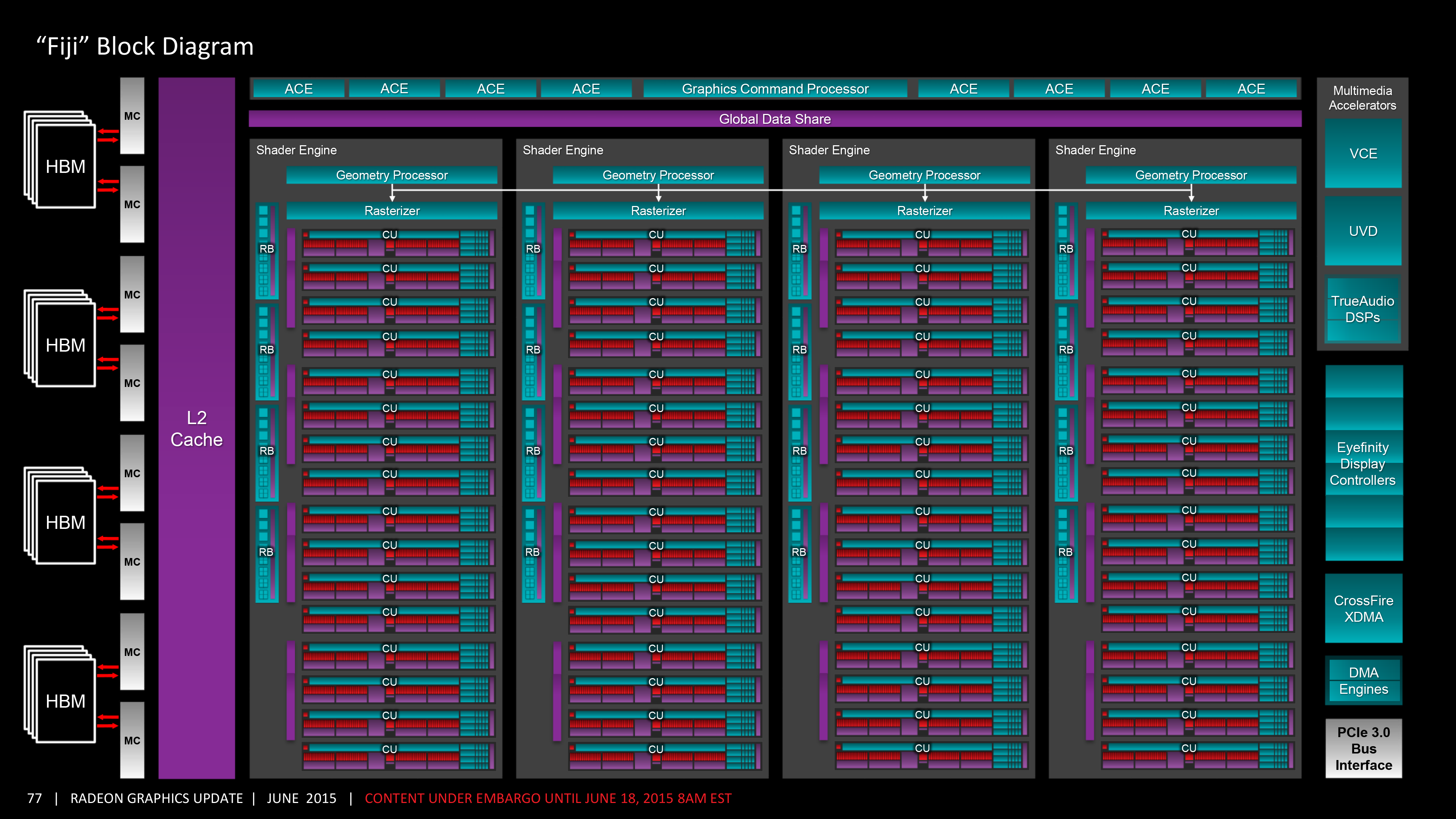
Fiji 核心最主要的特色有三,首先是 Fiji 是 AMD 截至目前為止架構規模最龐大的 GPU 核心,這點可以從密密麻麻的架構圖當中直覺得知,在本篇後半將介紹的第四代 GCN 架構當中沒有任何足以與之匹敵的核心,甚至直到今日目前剛剛推出不久的 VEGA 64 核心也僅僅具備同等的規模而已,Fiji 核心的每組 Shader Engine 可以支援多達 16 組 CU (合計一共有 64 組 CU、4,096 個 SP),渲染輸出單元的數量則是比照 Hawaii,是剛剛介紹的 Tonga 核心的兩倍,前端元件則是維持與 Hawaii 核心相同的規模。
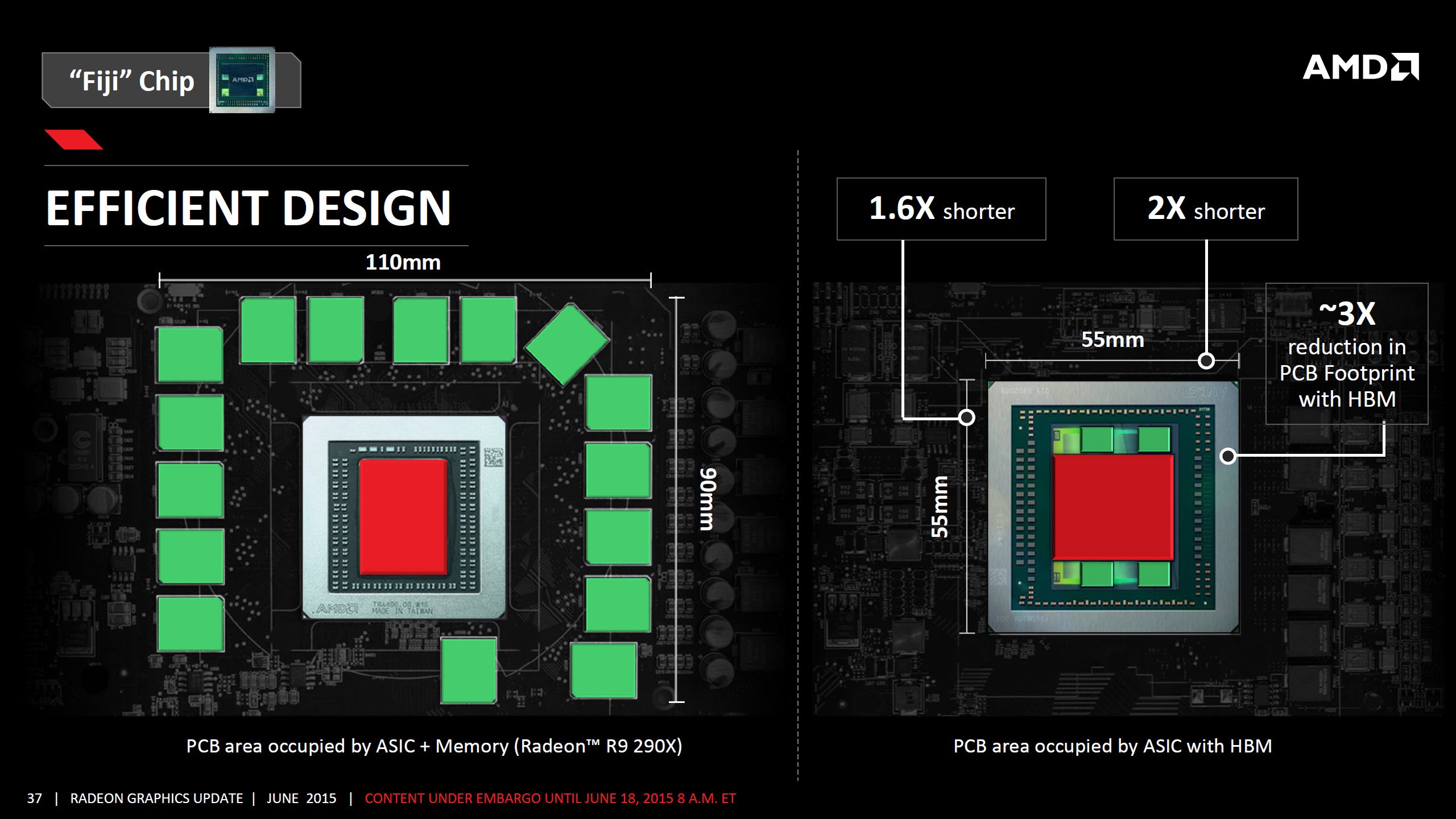
Fiji 的第二項主要特色則是其為 AMD 第一款採用 High-bandwidth Memory (HBM) 記憶體的產品 (同時也是第一款採用 HBM 的桌上型電腦 GPU),與以往傳統的顯示記憶體最大的差異在於 HBM 是與 GPU 核心本體封裝在同一塊基板上使其可以大幅降低與 GPU 之間通訊的延遲與大幅提高傳輸頻寬 (以 Fiji 來說一舉突破到 4096-bit 之譜),而且可以透過堆疊來大幅減少在 PCB 上佈建記憶體顆粒所需要占用的面積。

下圖左側為傳統顯示記憶體在顯示卡 PCB 上配置所需要的空間,右側則為 Fiji 與 HBM 記憶體堆疊之後的大小,比較之下確實可以縮減非常大片的面積,這項技術 AMD 早在 2007 年就已經開始發展,耗費了將近七年時間才加入旗下的 GPU 產品。

採用 Fiji 核心的產品僅有四款,這四款當中的前三款均屬於當時 AMD Radeon 系列當中定位最高的產品線-R9 Fury,最早發佈的是在 2015 年 06 月宣布的 R9 Fury X (採用 Fiji XT 核心,包含 64 組 CU、4,096 個 SP、提供 4096-bit HBM 記憶體支援,時脈為 1050 MHz),是系列當中單晶片規格設定最高的版本,採用了由 CoolerMaster 提供的水冷散熱器,是繼 R9 295X2 之後第二款預設搭配水冷散熱的顯示卡。

在次月 AMD 則推出了部分刪減之後的 R9 Fury (採用 Fiji Pro 核心,包含 56 組 CU、3,584 個 SP、提供 4096-bit HBM 記憶體支援,時脈為 1000 MHz),此款使用的就是一般的風冷散熱器了,不過由於發熱量大,因此並未採用 R9 Fury X 的短卡設計 (因 HBM 記憶體的緣故,Fiji 其實不需要很大的 PCB 面積)。

而在同年八月 AMD 則是推出了 Fiji 核心產品當中 PCB 面積最小的 R9 Nano,截至目前為止仍是世界上單位面積性能最為強大的顯示卡,值得注意的是 R9 Nano 也僅採用風冷散熱器,但使用的可是完整版的 Fiji 核心 (採用 Fiji XT 核心,包含 64 組 CU、4,096 個 SP、提供 4096-bit HBM 記憶體支援,時脈為 1000 MHz)。

將散熱器移除之後便可發現 R9 Nano 的 PCB 面積其實除了 Fiji 核心之外,幾乎是沒有任何空位了。

而最後一款採用 Fiji 核心的產品則是 Radeon Pro Duo,顧名思義此款產品是由兩枚 Fiji 核心所組成的,由系列名稱可以知道此款產品與其他 R9 系列的目標客群並不相同,不是針對玩家設計而是以遊戲開發者為主要對象,並且與 R9 295X2 一樣採用特殊訂製款的一對二水冷散熱器。

Radeon Pro Duo 使用的 Fiji XT 核心之設定參數則與 R9 Nano 相同,直到目前為止仍然是 AMD 單卡性能最強的顯示卡產品。

第四代 GCN (Polaris 北極星)
- 推出日期:2016 年 06 月
- 所屬系列編成:RX 400 系列、RX 500 系列
- API 支援:DirectX 12.0、OpenGL 4.5、OpenCL、Vulkan
- Shader Model 支援:SM 6.0

接下來要介紹的則是 AMD 在 2016 年中所推出的第四代 GCN 架構,相信這同時也是大家目前最為熟悉的 AMD GPU 架構吧?畢竟正好搭上加密虛擬貨幣挖礦熱潮使 AMD 的顯示卡意外出現賣到缺貨、一卡難求的盛況,以一款已經發展了四、五年的架構來說實屬難得,然而在第四代 GCN 架構發展的初期本來是依循過去慣例被命名為 Arctic Islands (北極島),不過在 Radeon Technologies Group (RTG) 改組成立之後便被新的部門領導人改名為 Polaris (北極星)。

睽違已久的製程改進
在第四代 GCN 架構當中,我們終於見到 GPU 所使用的製造工藝從 28 奈米製程提升到 14 奈米製程 (由於 20 奈米製造工藝被認為有著漏電率過高導致晶片效率不佳的問題,因此 AMD 在 28 奈米製程足足停頓了四年半之久) 了。

第四代 GCN 架構核心採用了由三星發展、Global Foundry 代工製造的 14 奈米 FinFET 製程 (另有部分產品使用 TSMC 的 16 奈米 FinFET 製程)。

同時這也是第四代 GCN 架構當中最為關鍵的改進,絕大多數第四代 GCN 架構所引入的性能改進除了架構上的許多小修小補之外,大多來自於本次製程使單位耗能可獲得的性能出現了明顯的成長,這一切基本上都要歸功於 FinFET 技術對降低漏電率帶來的幫助 (漏電率甚至可以壓到比先前 28 奈米製造工藝還要更低)。
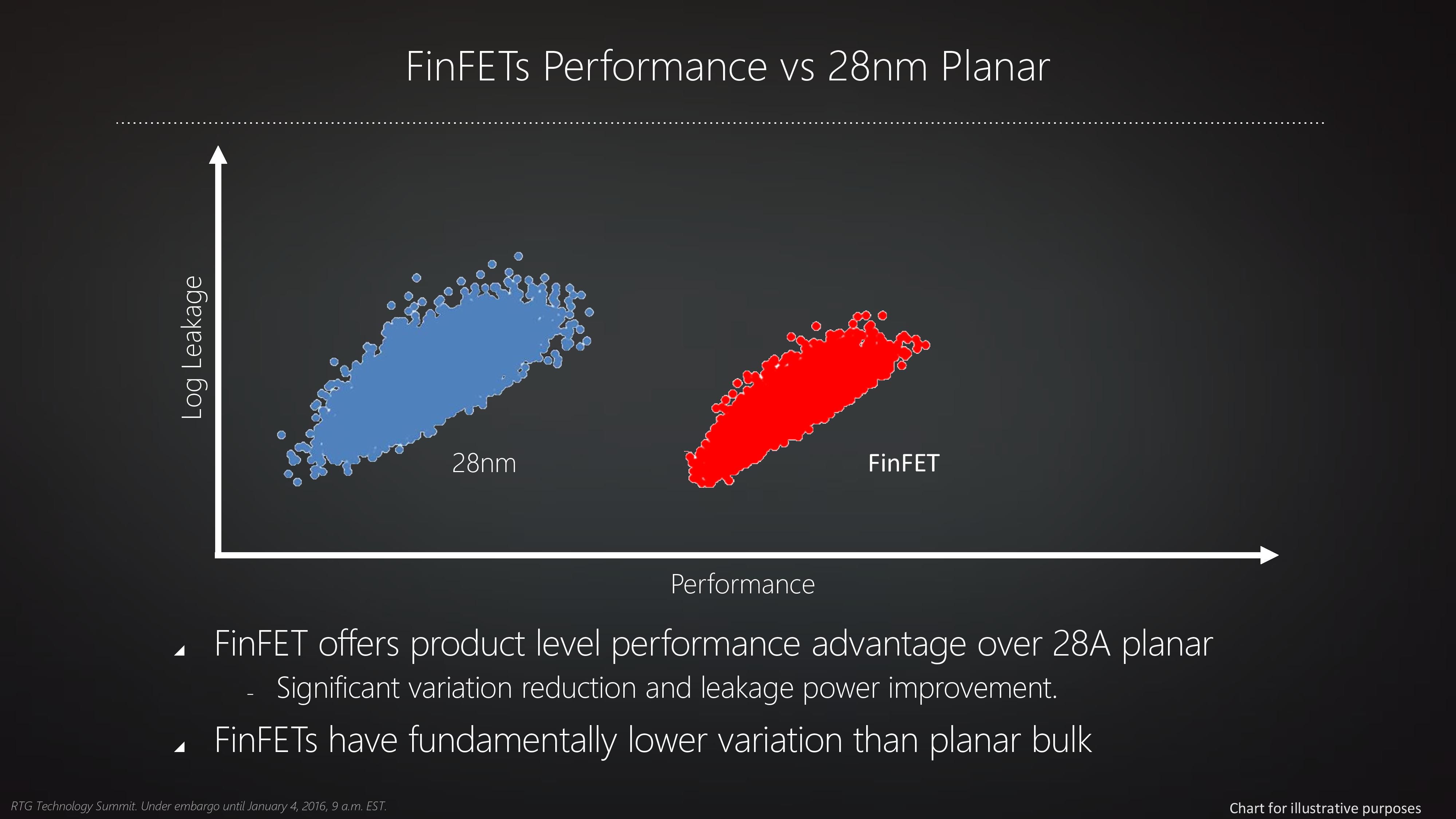
GCN 架構再次優化
基本上 Polaris 架構在結構上與過去的第三代 GCN 架構並沒有甚麼明顯的不同,但 AMD 在第三代 GCN 架構的各個元件 (基本上除了後端渲染輸出部分之外都有改良) 中都進行了一系列小修小補使得已經沿用多年的 GCN 架構得以再次獲得一些效率上的提升 (但性能方面並沒有出現讓人驚豔的增長,Polaris 此一世代基本上以降低耗電量、提升運作效率為主軸,同時這也是近年來兩大廠 GPU 架構發展的主要路線)。
整體來說第四代 GCN 架構對於架構本身的異動程度可說是「影響廣泛但幅度不大」,可以視為是第三代 GCN 架構的補完 (實際上第四代 GCN 架構的指令集架構與第三代 GCN 架構完全相同),主要的改進內容可以歸納為兩類,其中第一類是針對 CU 的優化,AMD 在第四代 GCN 架構當中引入了指令預取 (Instruction Prefetch) 機制,透過允許驅動程式預測下一個指令並交給 GPU 預先執行的手段來減少運算管線發生阻塞的機率以提高效率,此外第四代 GCN 架構所採用的指令緩衝區從以往的 12 DWORDs 擴大為 16 DWORDS,透過讓更多指令得以被放入緩衝區內來改進 CU 的單執行緒運算性能。

前端元件的優化
在第四代 GCN 架構中 AMD 在前端元件裡加入了一項稱為多邊形拋棄加速器 (PDA) 的功能,由名稱可以得知這項功能是用於加速在運算過程中拋棄不須用到之多邊形的速度,以避免 GPU 耗費太多運算資源在計算實際上並不會用到的多邊形上,根據 AMD 官方的說法,這項功能對 MSAA 反鋸齒有著不錯的效果。
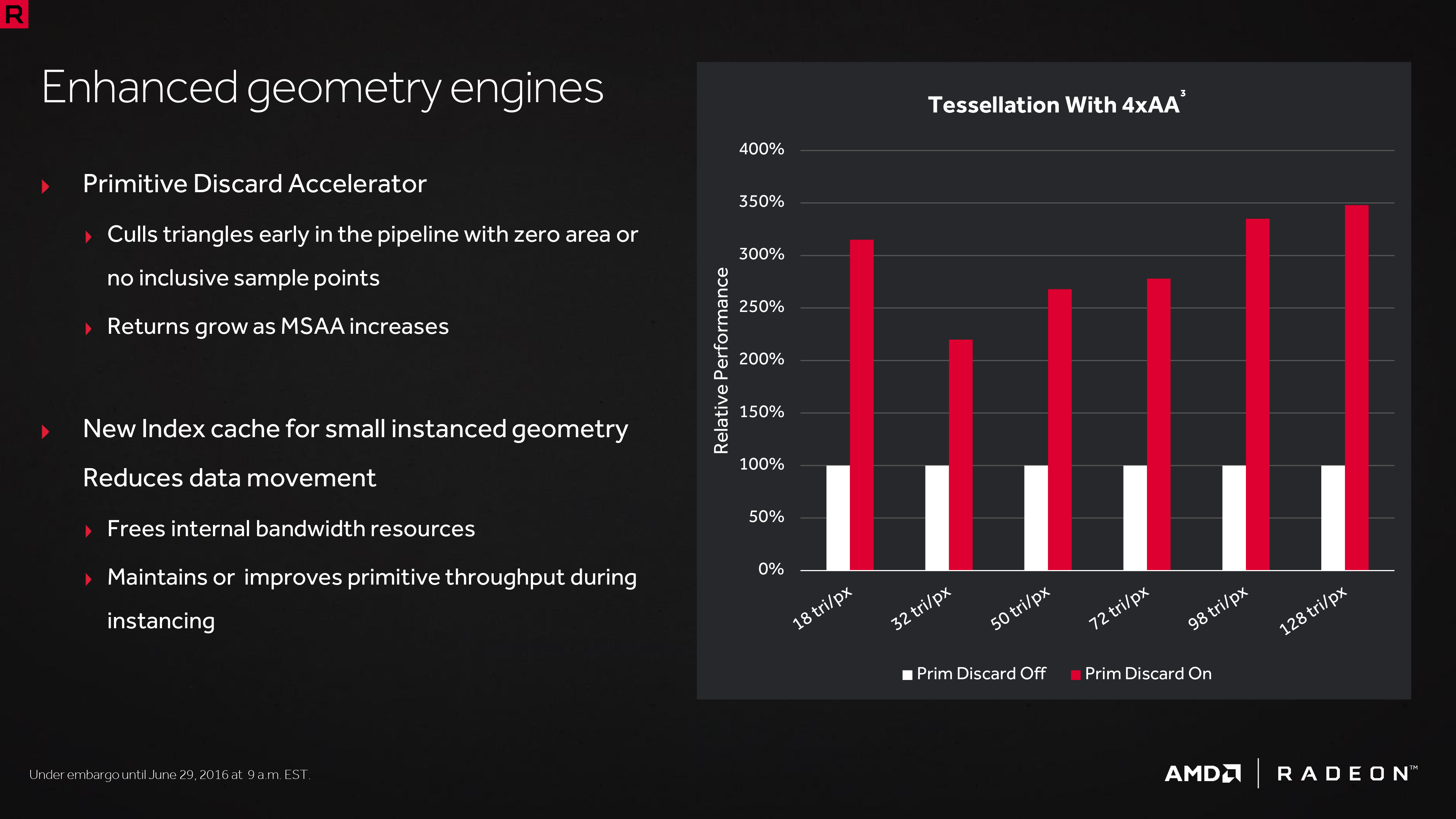
此外前端元件中用於加速多邊形生成性能的的索引快取也獲得了一些改進,可以起到一些降低資料在快取與顯示記憶體之間移動造成延遲的作用。
記憶體階層架構調整
在記憶體階層架構方面大致上第四代 GCN 架構是延續了第三代 GCN 架構的發展主軸,同樣是朝著改進差異色彩壓縮 (DCC) 技術以節省記憶體頻寬的方向前進,同時 AMD 也針對記憶體控制器與相關的傳輸介面進行了一些優化工作。
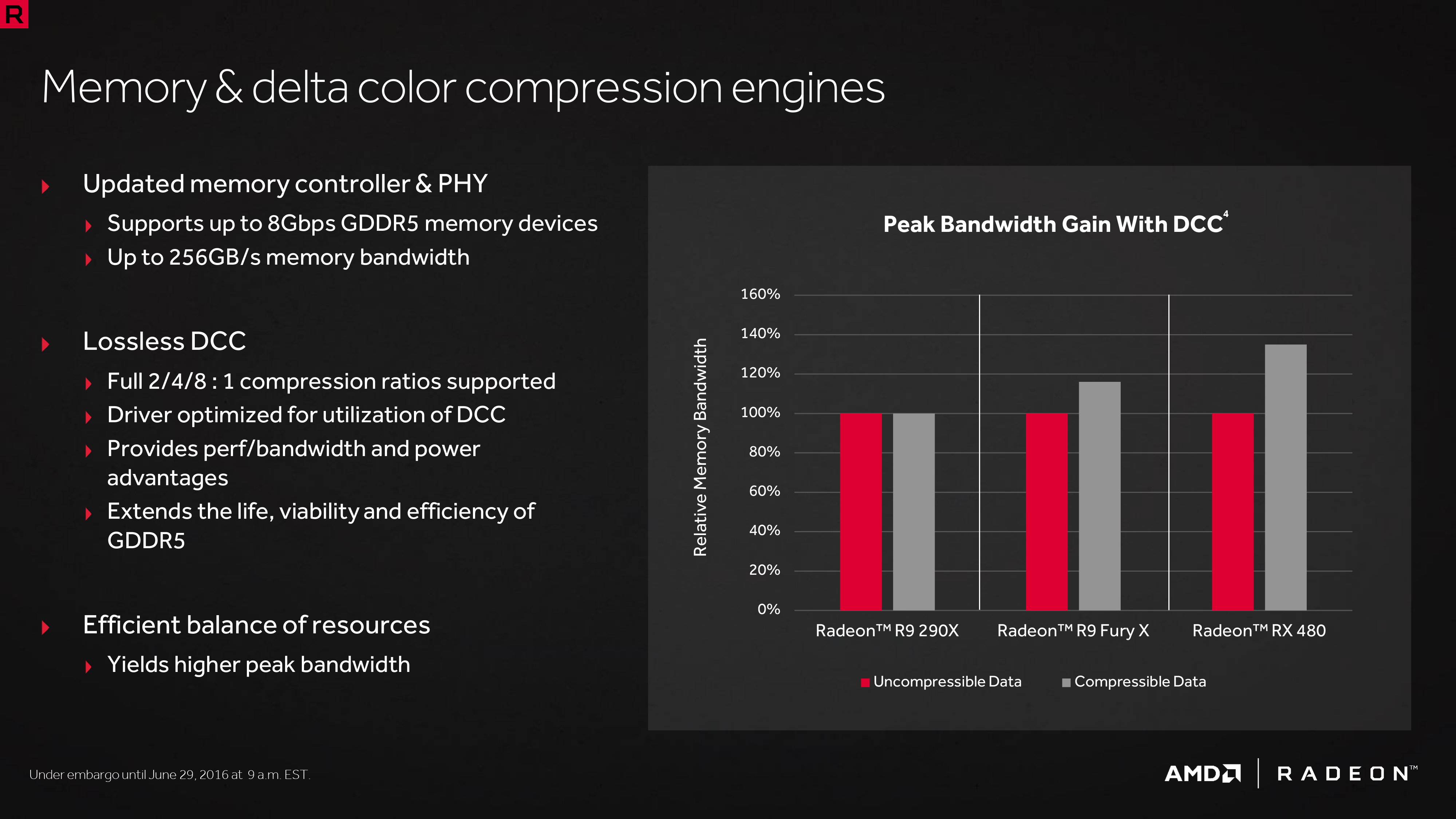
不過在架構上比較明顯的差異則是出現在快取記憶體的配置上,先前提過 GCN 架構中 L2 快取的大小實際上是與記憶體控制器的數量連動的,而在第四代 GCN 架構當中每組記憶體控制器所帶有的 L2 快取大小從 64 KB 或 128 KB 提高到最高 256 KB 並且優化了 L2 快取的運作模式。
Polaris 10 (Ellesmere) 核心
首批採用第四代 GCN 架構 (Polaris) 的核心有兩款,由於 AMD 一開始是將其命名為 Arctic Islands (北極島) 因此這兩款核心本來是分別被命名為 Ellesmere 與 Baffin,不過後來 AMD 將第四代 GCN 架構改名為 Polaris 時也一併把核心的命名規則改變了,之後 AMD 的核心將不再有各自專屬的名稱,這兩款核心則是被改稱為 Polaris 10 與 Polaris 11。
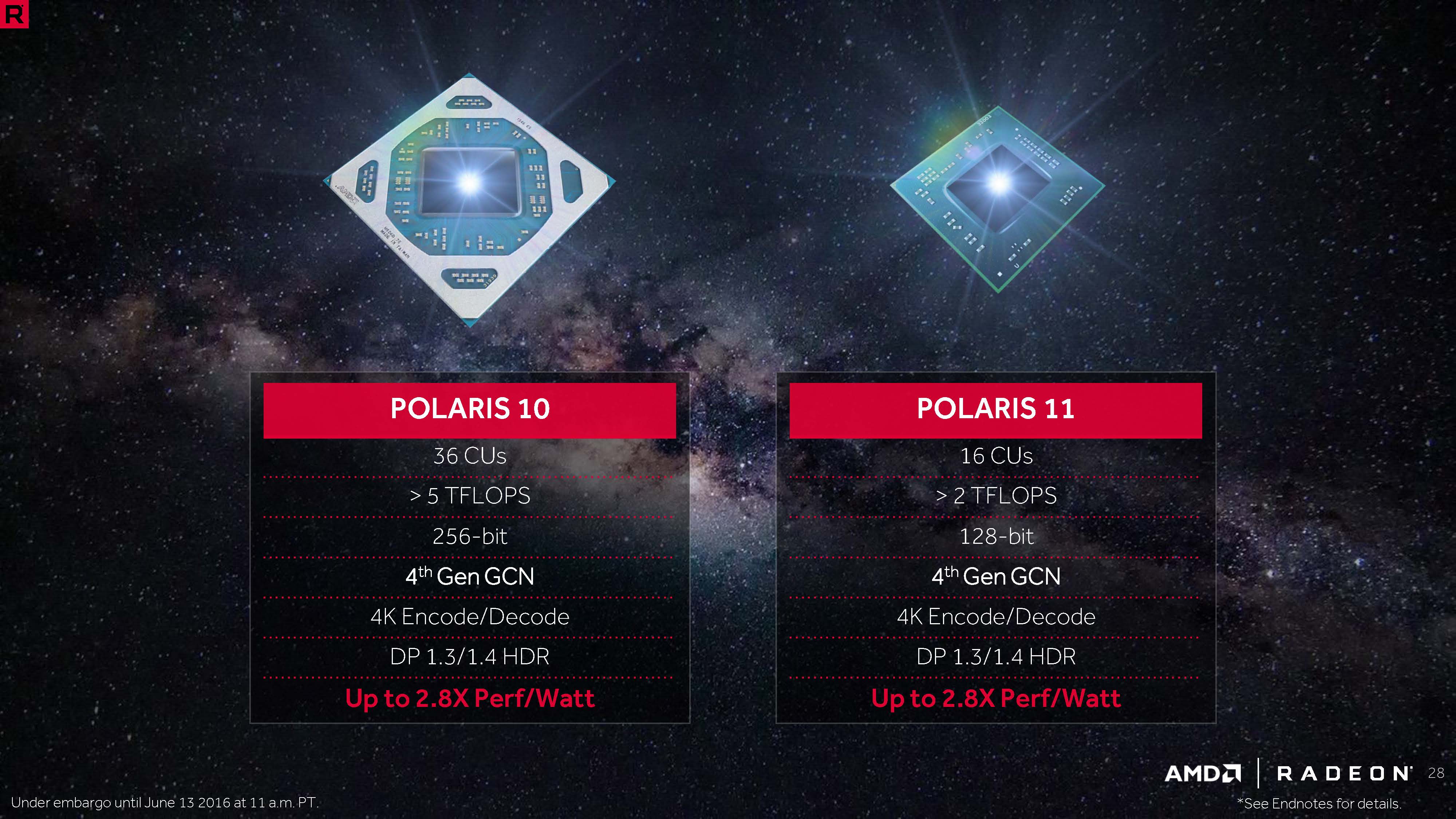
其中 Polaris 10 (Ellesmere) 這款核心在定位上是接替 Tonga 核心的位置,亦即主要是面向中高階市場,至於頂級市場的部分 AMD 則是選擇繼續由 Fiji 擔綱 (雖然當時也宣布了 Vega 將是 Fiji 的後繼,但 VEGA 後來一路延期到 2017 年中才上市,一般而言將其歸類為第五代 GCN 架構)。
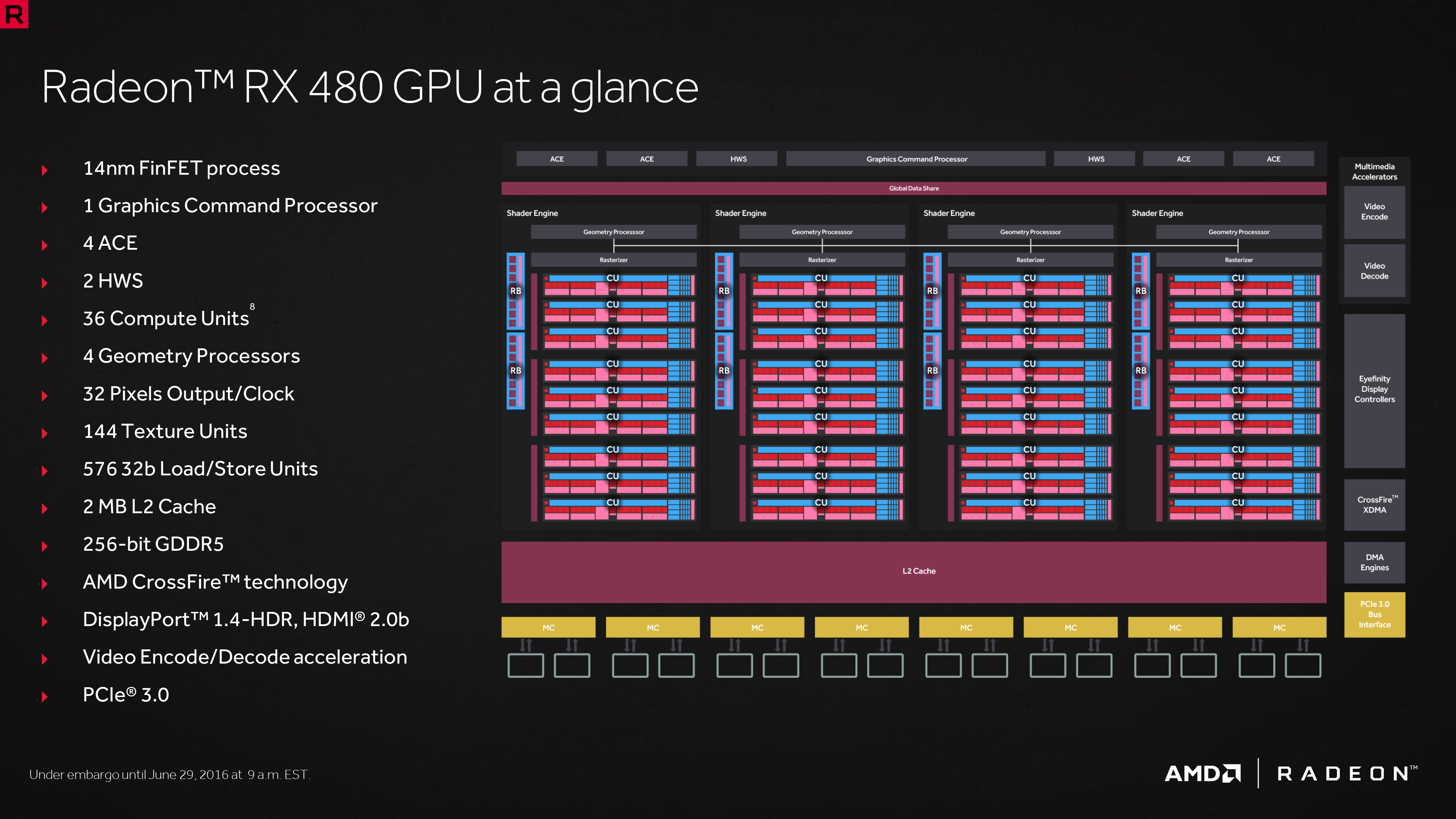
從上圖的架構當中可以得知 Polaris 10 的規模比起 Tonga 來說要來得更大一些,Tonga 的 CU 數量至多僅有 32 組而 Polaris 10 至多可以來到 36 組 (2,304 個 SP),至於記憶體通道寬度的部分則是維持在 256-bit,但得益於優化過的記憶體控制器與更高的記憶體時脈,因此 Polaris 的記憶體頻寬會比 Tonga 來的高上不少。

首批採用 Polaris 10 核心的產品僅有 RX 480 (採用 Ellesmere XT 核心,包含 36 組 CU、2,304 個 SP、提供 256-bit GDDR5 記憶體支援,時脈為 1120 MHz / 1266 MHz) 與 RX 470 (採用 Ellesmere Pro 核心,包含 32 組 CU、2,048 個 SP、提供 256-bit GDDR5 記憶體支援,時脈為 926 MHz / 1206 MHz) 兩款。

而隔年四月推出的 RX 580、RX 570 則分別對應是 RX 480 與 RX 470 的高時脈版本,前者的時脈提高到 1257 MHz / 1340 MHz,而後者則是提高為 1168 MHz / 1244 MHz,其餘規格則沒有任何變化。
Polaris 11 (Baffin) 核心
至於面向中階市場的 Baffin 則是擔綱接替已經廉頗老矣的 Pitcairn 核心扮演著為 AMD 在主流市場中攻城掠地的角色。
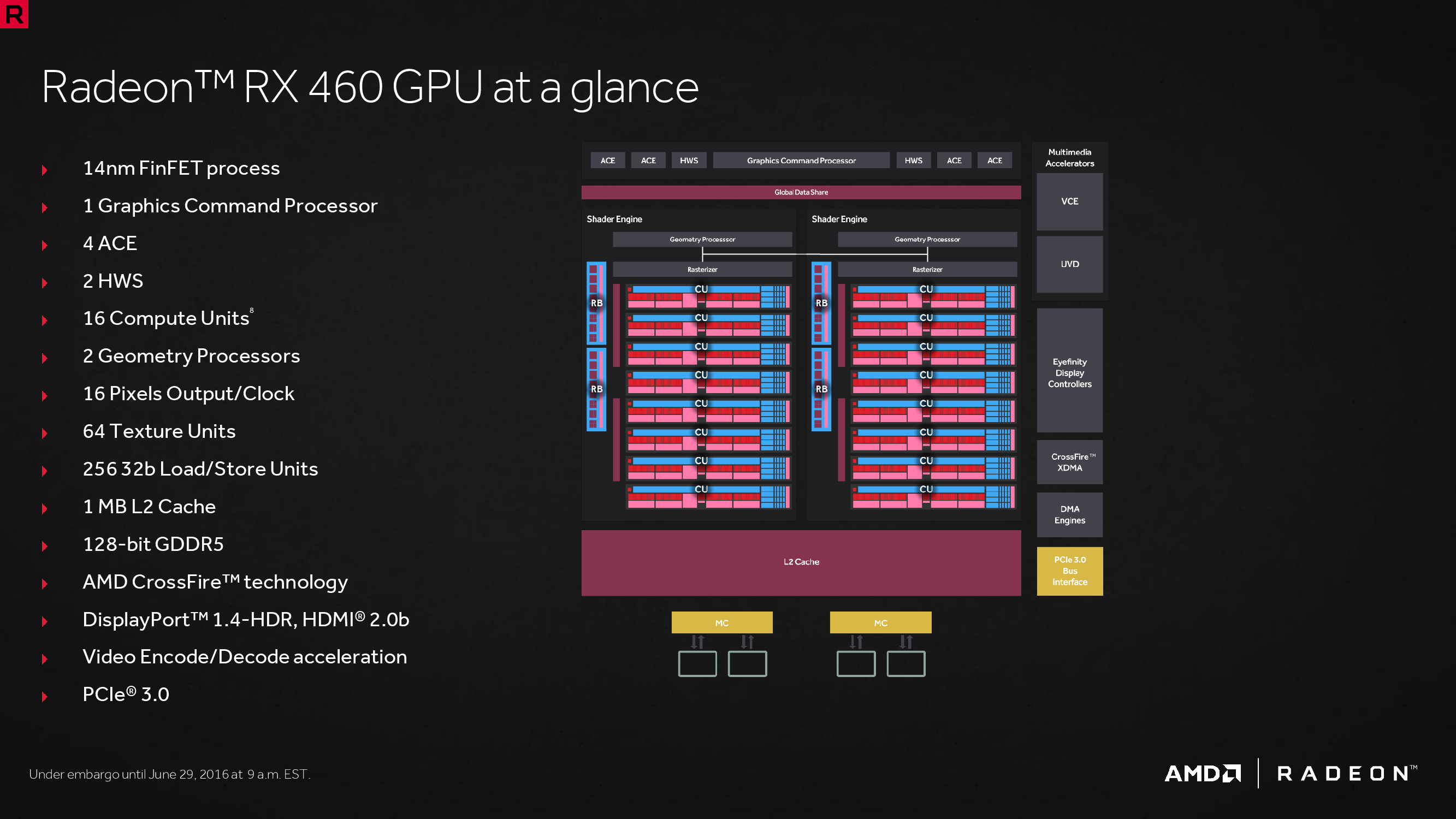

最初採用 Polaris 11 核心的產品僅有 RX 460 一款,值得注意的是 RX 460 所搭配的 Polaris 11 核心並不是完整版本,而僅包含了 14 組 CU、896 個 SP 與 128-bit 的 GDDR5 記憶體支援,運作時脈則設定為 1090 MHz / 1200 MHz。

後來直到隔年 AMD 才在 RX 560 上使用了完整版本的 Polaris 11 核心,包含了 16 組 CU、1,024 個 SP,且時脈小幅提升到 1175 MHz / 1275 MHz。
Polaris 12 (Lexa) 核心
最後一款基於 Polaris 架構的核心則是原先被命名為 Lexa 的 Polaris 12,或許是基於某些特殊考量吧?AMD 在 RX 400 世代當中並沒有推出搭載 Polaris 12 的產品,但從其也有著舊規則下的命名來看,應該也是與 Polaris 11、Polaris 10 同時間規劃的產物。


目前為止 Polaris 12 只用在 RX 550 與 RX 540 兩款型號上,這兩款產品都只具備 8 組 CU (512 個 SP) 與 128-bit 的 GDDR5 記憶體支援,就規格參數上看起來 Polaris 12 應該是 Polaris 11 把所有 Shader Engine 當中包含的 CU 數量刪減一半之後的結果,其餘周圍元件則沒有再被刪減。
歷史總是驚人的相似,卻又帶了點不同。
因為一些原因,電腦達人養成計畫直到 2017 年 05 月 18 日發佈了 5-26 節 NVIDIA Maxwell 架構之後就一路延宕了將近九個月的時間 (一方面是 GPU 發展史真的不好寫),其中 5-27 節其實早在 5-26 節完成當天站長就已經動筆了,不過後來始終斷斷續續沒能補出一篇完整的文章 (或許讀者也看得出來 5-26 節讀起來不太順,因為那篇文章的頭跟尾之間隔了九個月),不過為了能早點繼續接下去寫其他「比較好寫」的部分,站長在這兩、三天還是一口氣把 5-26 與 5-27 給補完了。
在寫到 5-27 節的尾聲,談完 Polaris 12 之後,我花了一點時間思考到底要給 GCN 架構的後半一個甚麼樣的總結作為全篇的標題比較好,最終我選擇了「歷史總是驚人的相似」這句話作為這五年左右的時間 AMD 的 GPU 部門 (現在的 Radeon Technologies Group) 的註解。
還記得在 5-23 節當中我曾經把 AMD/ATI 這樣的循環歸納為摔個半死 → 策略轉彎 → 大幅優化 → 了無新意 → 大幅衰退 → 摔個半死,GCN 架構這一世代又何嘗不是如此?在意識到不捨棄 VLIW 架構將無法在通用運算日益蓬勃的時代與 NVIDIA 競爭之後才有了 GCN 架構的誕生,而在歷經第二代、第三代 GCN 架構的大幅優化之後我們見到了基本上沒甚麼新意的 Polaris (第四代 GCN 架構)。
而目前眼下最近的消息大概就是當時曾經讓大家誤以為將是 AMD 觸底反彈機會的 VEGA 最後卻只是雷聲大、雨點小,做為頂級旗艦性能上卻只能緊追 GTX 1080 而根本無法威脅 GTX 1080 Ti 分毫的大幅衰退,最近又遇上 RTG 部門主管 Raja Koduri 跳槽 Intel、AMD 居然與 Intel 合作在 Intel 的 CPU 旁邊搭配 VEGA 核心一同封裝的驚人事情,看起來又是個準備要再次挑戰絕地逢生的節奏了。
不過雖然相似的歷史再次上演,但每次卻都仍然有那麼一點不同,現在 GPU 產業最大的變數與意料外的成長大概就是來自於加密貨幣蓬勃發展所連帶引發的挖礦熱潮吧?然而 AMD 受到的影響又比 NVIDIA 來的更大,供不應求的情況已經持續了將近一年之久,雖然給兩大廠商創造了許多意外收入,但也產生了排擠遊戲玩家的情況,甚或若未來發生礦難或是加密虛擬貨幣退燒的話可能會瞬間導致財務上的重挫等嚴重的問題。
在這樣的世道下對於兩大 GPU 廠商來說到底是福是禍?其實真的很難說。