

在簡介完硬碟與磁碟介面的發展過程與特色之後,接下來站長打算把主題轉向回到較具技術性的部分,談談現代電腦硬碟的運作原理與作業系統等軟體如何利用硬碟儲存空間。
Table of Contents
現代電腦硬碟運作原理
在現代的電腦架構中,最早、最廣泛且最長期使用的就是磁性儲存媒介,從 7-1 節介紹過的磁帶、軟碟片到 7-2 節與 7-3 節所談的硬碟都是基於磁性儲存媒介設計出來的儲存設備 (一般而言會包含讀寫頭、塗有磁性物質的碟盤與控制電路板等元件所組成),而磁性儲存媒介的基本原理就是透過讀寫頭與塗滿磁性物質的碟片之間的交互作用來進行資料的讀寫。


採用磁性材料作為儲存媒介之儲存設備的基本原理為利用讀寫頭發出的磁場改變儲存媒介上塗布的磁性材料的分布情形進行資料寫入、利用讀寫頭感測各區域的磁性材料分布情形 (感應各區塊的磁性物質所產生的磁場方向) 來讀取資料,也就是我們接下來要探討的主題——磁性紀錄技術。
磁性記錄技術
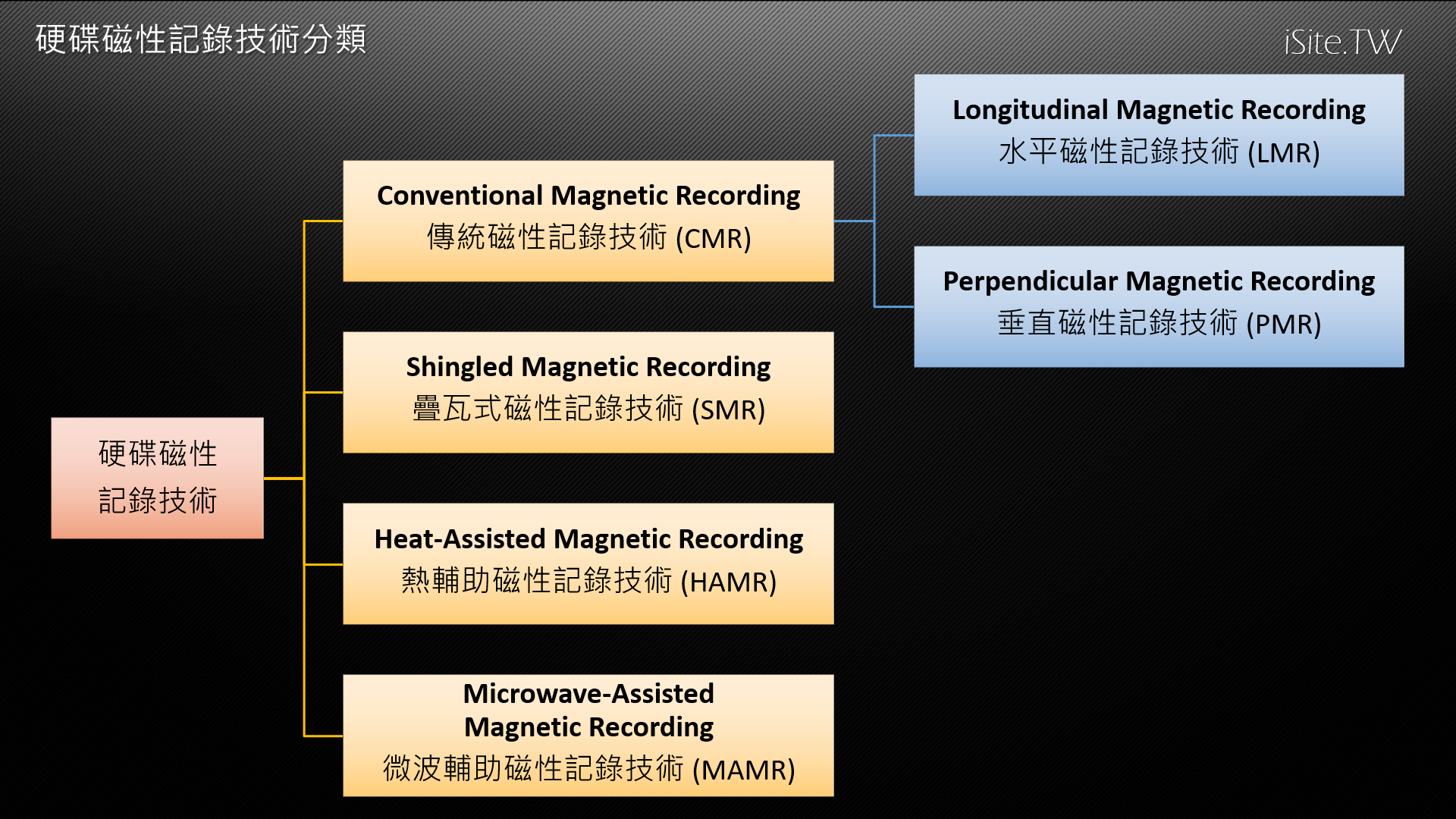
雖然過去幾十年內推出的電腦硬碟運作的基本原理大致相同,但在實作方面其實有著多種不同做法。從最早被發展出來的水平磁性記錄技術 (LMR) 到十幾年前讓電腦硬碟容量大幅提升的垂直磁性記錄技術 (PMR),再到近年來為追求更高儲存密度推出,但因其特性而引發許多爭議的疊瓦式磁性記錄技術 (SMR),隨著時代變遷至今已有許多種類不同的記錄技術被發展出來。
水平磁性記錄技術 (LMR)
水平磁性記錄技術 (Longitudinal Magnetic Recording,LMR) 為最初被發展出來的磁性記錄技術,在 2005 年以前的硬碟都是採用此種技術,此種硬碟所使用的磁盤其上塗佈的磁性物質的磁性主要分布方向是與盤面平行的。
水平磁性記錄技術伴隨著電腦硬碟的發展一路走過了五十多個年頭,但隨著儲存密度的上升、用於儲存資料的磁性物質體積愈縮愈小而變得益發明顯的超順磁效應問題 (隨著磁性物質體積縮小,使其磁場方向改變所需的能量也隨之下降,最終到了在室溫環境下磁場方向也會自發性發生改變的程度,無法維持穩定的磁場方向自然也就無法穩定儲存資料) 使得硬碟容量與可靠性的提升遭遇了嚴重的瓶頸,水平磁性記錄技術所能允許的極限儲存密度大約是每平方英吋 120 Gb 左右。
垂直磁性記錄技術 (PMR)
為了應對水平磁性記錄技術愈來愈嚴重的超順磁效應問題,硬碟廠商在 2005 年開始推出採用垂直磁性記錄技術 (Perpendicular Magnetic Recording,PMR) 的硬碟產品,首款上市的產品為 TOSHIBA 在 2005 年 08 月所推出的 1.8 吋微型硬碟 (這種硬碟當年被大量應用在 iPod 上),隨後 Seagate 等廠商也在 2006 年陸續推出用於筆記型電腦與桌上型電腦的 PMR 硬碟 (又稱為「垂直寫錄硬碟」)。
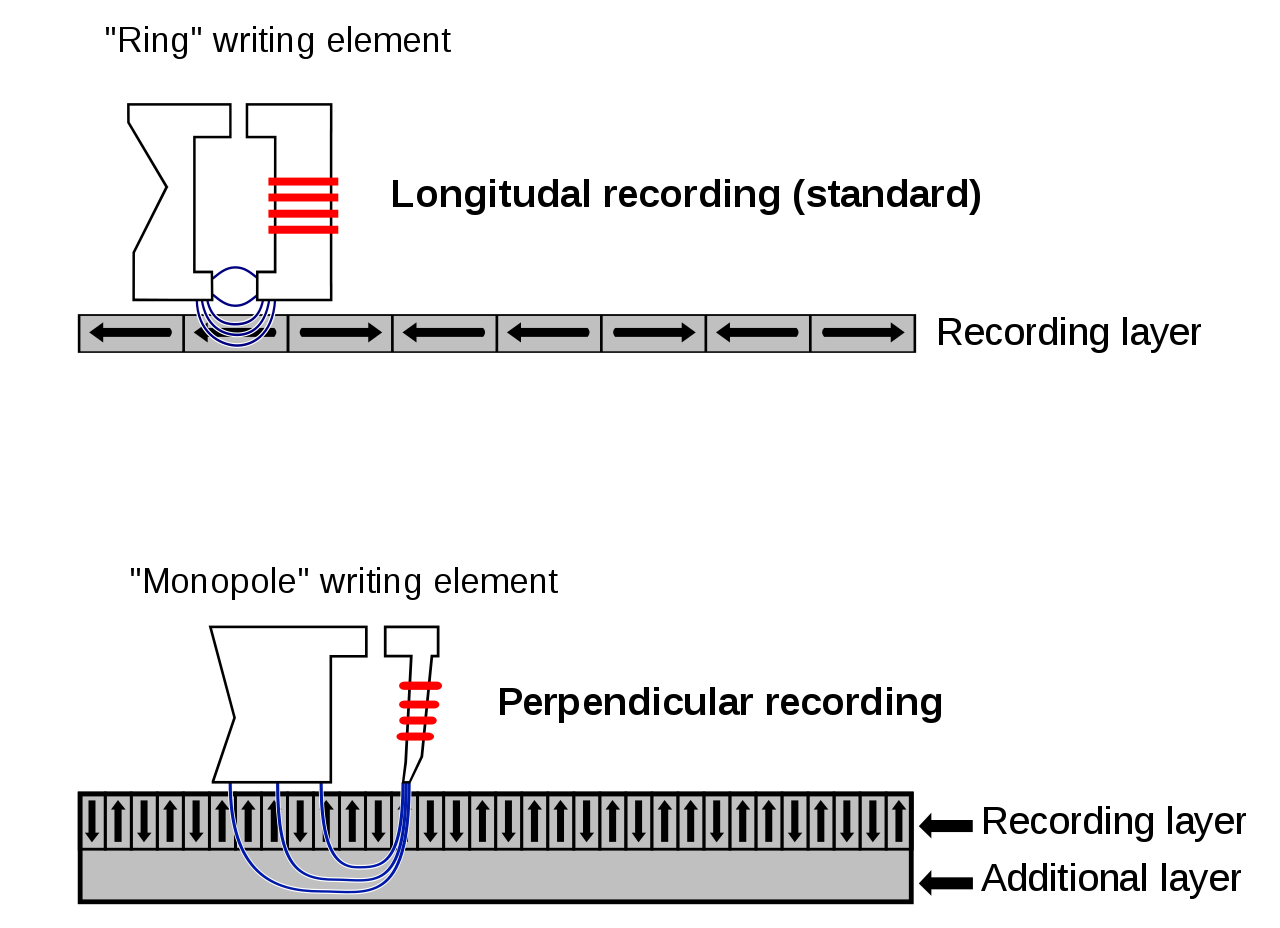

PMR 技術的主要原理為透過將磁盤上塗佈的磁性單元「立起來」使其磁性主要分布方向變為與盤面垂直來達到抑制超順磁效應的效果,從而使得磁盤上的單位面積儲存密度得以再次大幅提升,750 GB 以上的 2.5 吋硬碟與 1 TB 以上的 3.5 吋硬碟大多至少需要採用 PMR 技術才得以實現,隨著電腦硬碟容量的持續提升,目前 PMR 也已成為最主流的硬碟技術。
此外,由於 PMR 與 LMR 技術的原理十分相似,主要差異為磁性記錄單元的方向有所不同,因此 PMR 與 LMR 這兩種磁性記錄技術近來常被合稱為「傳統磁性記錄技術 (Conventional Magnetic Recording,CMR)」。
疊瓦式磁性記錄技術 (SMR)
由於磁軌寬度持續縮減會導致超順磁效應問題再次變得明顯,因此追求提高儲存密度時以磁軌為改進標的已經不太可行,因此硬碟廠商不得不尋找其他的途徑。

在 2013 年 Seagate 正式發布了疊瓦式磁性記錄技術 (Shingled Magnetic Recording,SMR),與傳統磁性記錄技術相比,SMR 技術最大的特性在於磁軌的排列方式由原先的互不重疊甚至為了配合讀寫頭的寬度而保有一定間距改為層層相疊、狀似屋瓦或階梯的結構,而這也是其中文名稱「疊瓦式」的由來。
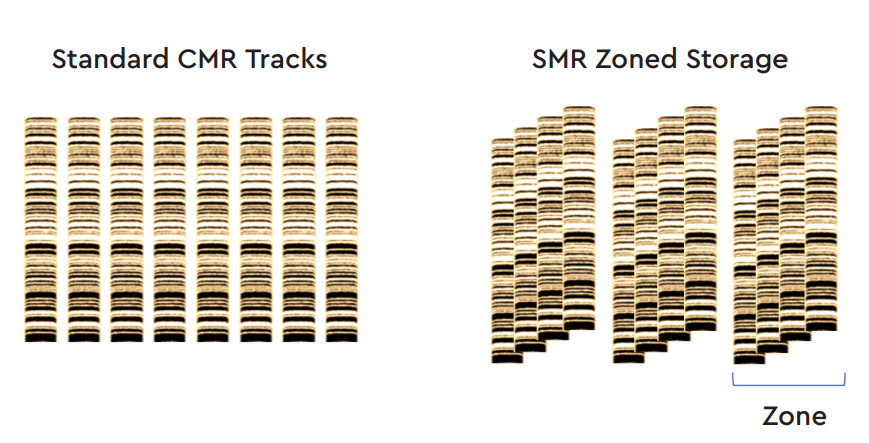

既然 SMR 的磁軌層層相疊,其單位面積所能容納的磁區數量顯然會因此而顯著成長,硬碟廠商認為這可以做為隨儲存密度持續上升而讓 PMR 技術再次遇上超順磁性效應問題時的解決方案,但 SMR 技術並非沒有缺點,而那些缺點也使得廠商在推動 SMR 技術時產生了不少爭議。
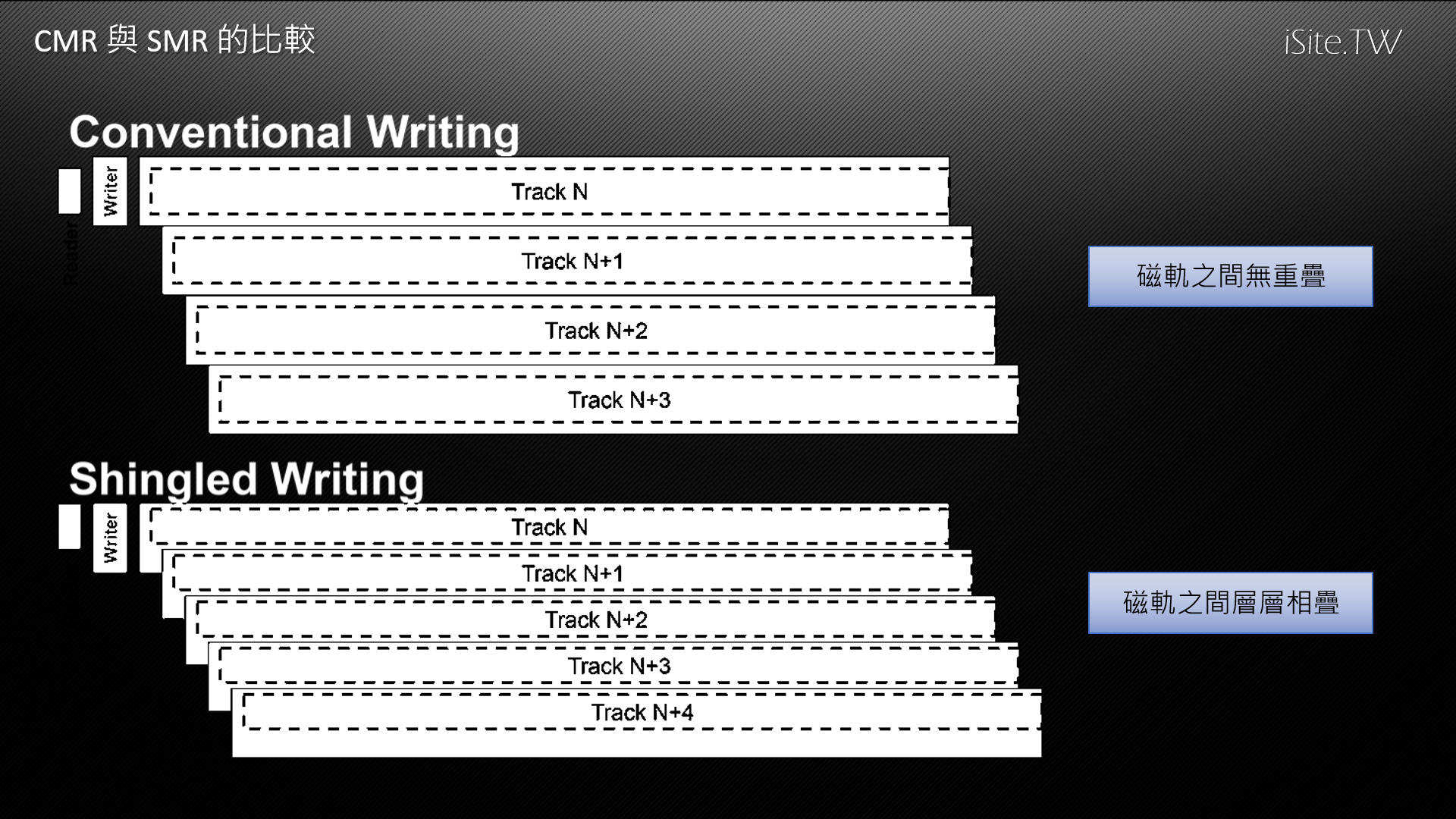
SMR 技術得以實現且有其意義的關鍵在於就目前技術而言讀寫頭當中負責「讀」的部分可以做得比負責「寫」的部分來得小,因此將磁軌層層相疊而每層僅露出與讀寫頭負責「讀」的部分等寬的部分就可以達到提高儲存密度同時又不影響讀取的目的,但對於 SMR 技術來說真正的挑戰是在寫入的部分。


由於讀寫頭當中負責「寫」的部分寬度比重疊之後露出的磁軌還要來得寬,因此無可避免的讀寫頭在進行寫入時勢必會同時影響到相鄰的磁軌,因此在寫入資料之前得把鄰近磁軌的資料先暫存到其他位置,等到寫入操作完成之後再把周圍所有磁軌重新寫入一次。
這樣的做法會導致幾個問題:
- 隨機寫入時需要大量進行鄰近磁軌重新寫入,導致性能的減退、壽命的縮短與可靠性的下降,在快取空間被用光之後寫入性能會出現非常劇烈的下跌。
- 為了確保相鄰磁軌的資料不在寫入時發生遺失,需要頻繁將資料搬入暫存區再回寫,導致延遲與發生斷電時資料遺失的風險提高。
- 在軟體、韌體支援不佳的情況下頻繁的資料移動可能導致發生錯誤進而引發檔案毀損的機率提高。
- 每多一次寫入便多一次出錯的可能,整體而言可能造成可靠性的下降。
為了應對這些缺點,硬碟廠商針對 SMR 技術的硬碟大多會採行加大快取、將磁軌分群應用、在磁盤上增加採用 PMR 技術的特殊區域同時應用這兩種技術等作法來緩解這些問題所帶來的影響。
由於採用 SMR 技術的硬碟在處理大量隨機寫入時的劣勢,目前而言一般不建議將採用 SMR 技術的硬碟用於安裝作業系統與日常操作用途,SMR 技術硬碟較適合用於大型資料備份與冷儲存等用途,根據 WD 在 2019 年所發布的預測,在 2023 年資料中心硬碟總出貨量當中將有近半是採用 SMR 技術的硬碟。
能量輔助磁性記錄技術 (EAMR)
除了 SMR 之外,目前磁性記錄仍有許多技術持續在發展中,目前看起來較有潛力的發展方向是以尋求透過外加能量輔助寫入來克服超順磁效應的能量輔助磁性記錄技術 (Energy Assisted Magnetic Recording,EAMR)。

各家硬碟廠商目前已經提出了多種不同的 EAMR 技術方案,例如 2006 年富士通發表了熱輔助磁性記錄技術 (Heat Assisted Magnetic Recording,HAMR) 與 2017 年由 WD 所發表的微波輔助磁性記錄技術 (Microwave Assisted Magentic Recording,MAMR) 等都屬於此類技術,前者使用雷射快速加熱磁性儲存單元,後者則使用發射微波的方式達成抑制超順磁性效應的目的。


至於首款進入量產階段的 EAMR 類技術硬碟則是 WD 在 2020 年所推出的 Ultrastar HC550,使用的不是 HAMR 也非 MAMR,而是相對而言較為簡單的「能量輔助式垂直磁性記錄技術 (Energy-Assisted PMR,ePMR)」,是基於現有垂直磁性記錄技術 (PMR) 的改進產物。


ePMR 技術透過在現有 PMR 的基礎上於讀寫頭主要結構通入電流產生額外磁場以進一步穩定讀寫頭對微小磁性單元進行寫入的能力,使磁軌密度得以再次在不使用目前消費者仍有許多疑慮的 SMR 技術的狀況下再次小幅提升,使單一硬碟機可提供多達 18 TB 的儲存空間。


至於 HAMR 與 MAMR 的部分,目前所知的是 Seagate 較傾向於發展 HAMR 技術,而 WD 則傾向於押寶 MAMR 技術並認為 HAMR 使用熱能作為寫入時的重要條件很可能有不易控制、可靠性低的問題,不過截至目前為止二者都還在研發階段中,僅有少量樣品被產出。
電腦軟體如何利用硬碟空間
在談完硬體層面的問題之後,接下來讓我們把目光轉向電腦軟體如何利用硬碟空間上,對於軟體來說,硬碟廠商使用什麼樣的技術去實作一款硬碟其實並不重要,軟體需要在意的是「有哪些空間可以運用」、「如何去劃分出這些空間的位置」、「如何維持高效率的存取」、「要用什麼規格去紀錄這些資料」等方面,因此我們發展了許多標準規範來解決這些問題,例如磁區的劃分與定址方式、硬碟分割的規劃方式與檔案系統等。
磁盤的區域劃分
由於軟碟與磁碟是利用「磁性物質在儲存媒介的分布情形」來做資料的讀寫,因此對磁性儲存媒介進行分區並且在儲存與讀取資料時精準定位各分區的實體位置非常重要,因此我們將磁性儲存媒介上劃分為許多磁區作為最小單位,並且根據不同的磁區分群方式創造出了磁軌、磁叢等名詞。
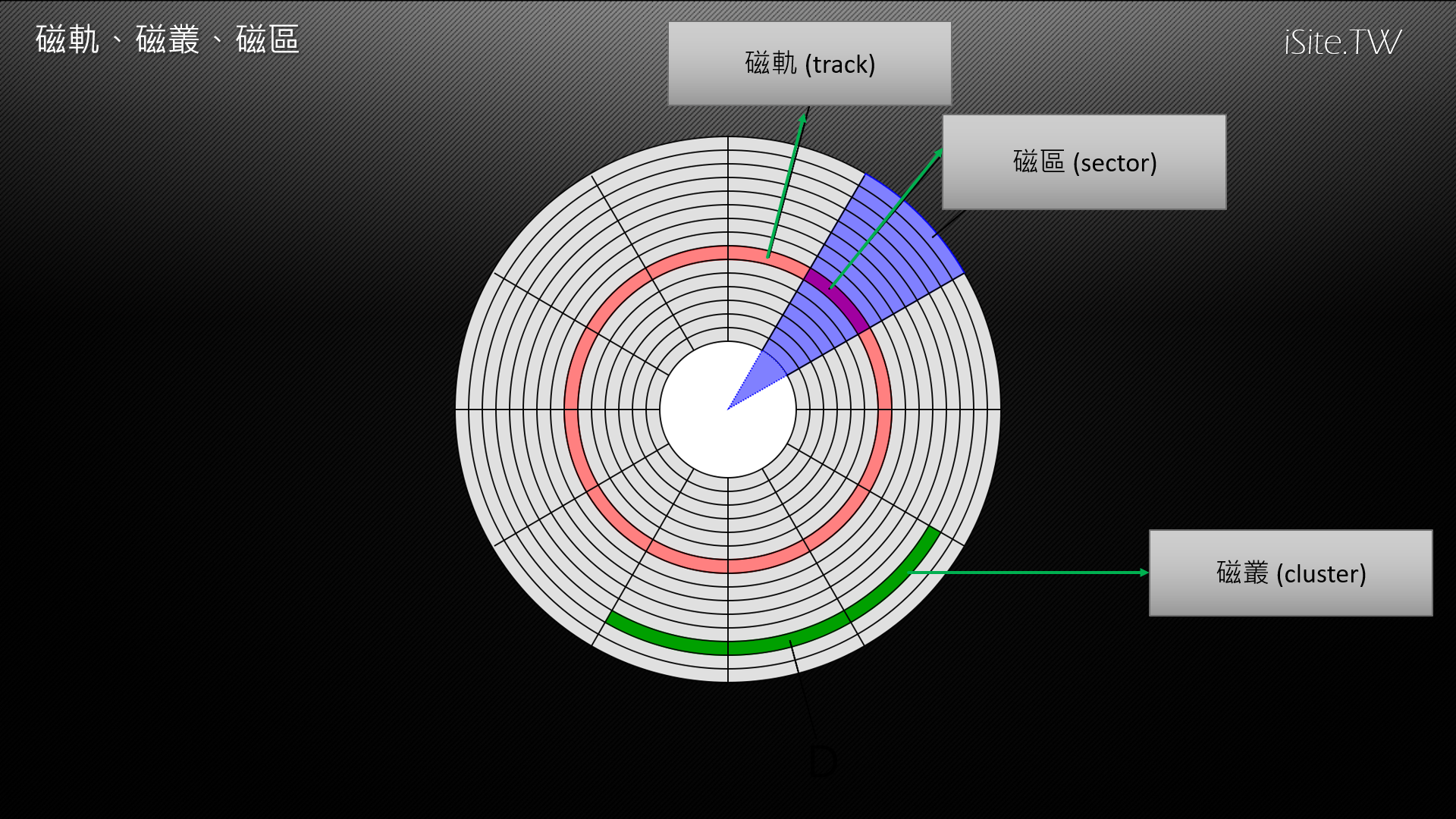
為了加速資料的存儲,我們在軟碟與硬碟上都是採用圓形的磁性儲存媒介 (稱為磁盤 disk),以透過快速轉動的方式來縮短讀寫頭在各個區域之間移動所需要耗費的時間,在結構上如同上面的簡圖,一塊硬碟可能有多個磁盤 (disk),而每個磁盤都具有正、反兩面,而每個磁盤表面上可以劃分為許多個同心圓,稱之為磁軌 (track),由於每面磁盤都需要一個讀寫頭,而且這些讀寫頭都裝置在同一個支架上面,因此會同步進行移動並同時接觸相對位置相同的磁軌,基於這樣的特性,讀取所有盤面上同一相對位置的磁區的效率會比讀取分散在不同相對位置的磁區來得高上許多 (可以減少讀寫頭移動的需求),而這些由上往下將每個磁盤上對應相對位置的磁軌可合稱為一個磁柱 (cylinder)。
而每個磁軌上可以分出許多稱之為磁區 (sector) 的小格子,這些小格子就是硬碟儲存資料時的最基本單位,絕大多數的硬碟都是以 512 bytes 為一個磁區的容量大小,近來硬碟廠商大力推廣的先進格式化 (Advanced Format,AF) 硬碟則是順應硬碟容量提升為了降低 ECC 校驗所需佔用的空間與造成的性能影響而將單一磁區的大小提升為 4,096 bytes 的意思。


此外,根據作業系統與檔案系統的設計,多個磁區有時也可以被合成為一個磁叢 (cluster) 或磁段 (block) 以方便作業系統處理檔案並進一步提高效率。
CHS 定址系統
在將這些單位定義清楚之後,接下來就可以對每個磁區賦予一個專屬位置,也就是所謂的「定址 (addressing)」,一般而言儲存設備所使用的定址方式主要有 CHS (Cylinder, Head and Sector) 與 LBA (邏輯區塊定址,Logical Block Addressing) 兩種方式,早期的電腦系統大多使用 CHS 定址,由其名稱可以知道這種定址方式是根據磁柱、磁頭以及磁區的方式來給予每個磁區一個專屬位置,先定出磁柱 (就是讀寫頭落點的位置),再決定磁頭 (其實就是選擇一個盤面) 以標定出特定的磁軌,最後在從這個磁軌上選出所要的磁區。
這種方式主要是對人類而言較為直觀,因為可以直接從定址的結果當中看出該磁區的實際位置,但缺點也很顯而易見,因為磁區位置的長度是固定的,而又要分段做固定的定義,因此相對而言所能定址的磁區數量就會比較受限。
例如在早年設計 IBM PC 的 BIOS 時,當年的工程師認為磁盤的密度提昇可能會很有限,而人們可能會透過堆疊大量磁盤的方式來提高硬碟的儲存容量,因此在設計 CHS 定址時將多達八個位數定義給了磁頭 (head),磁柱 (cylinder) 則分配了 10 個位數。
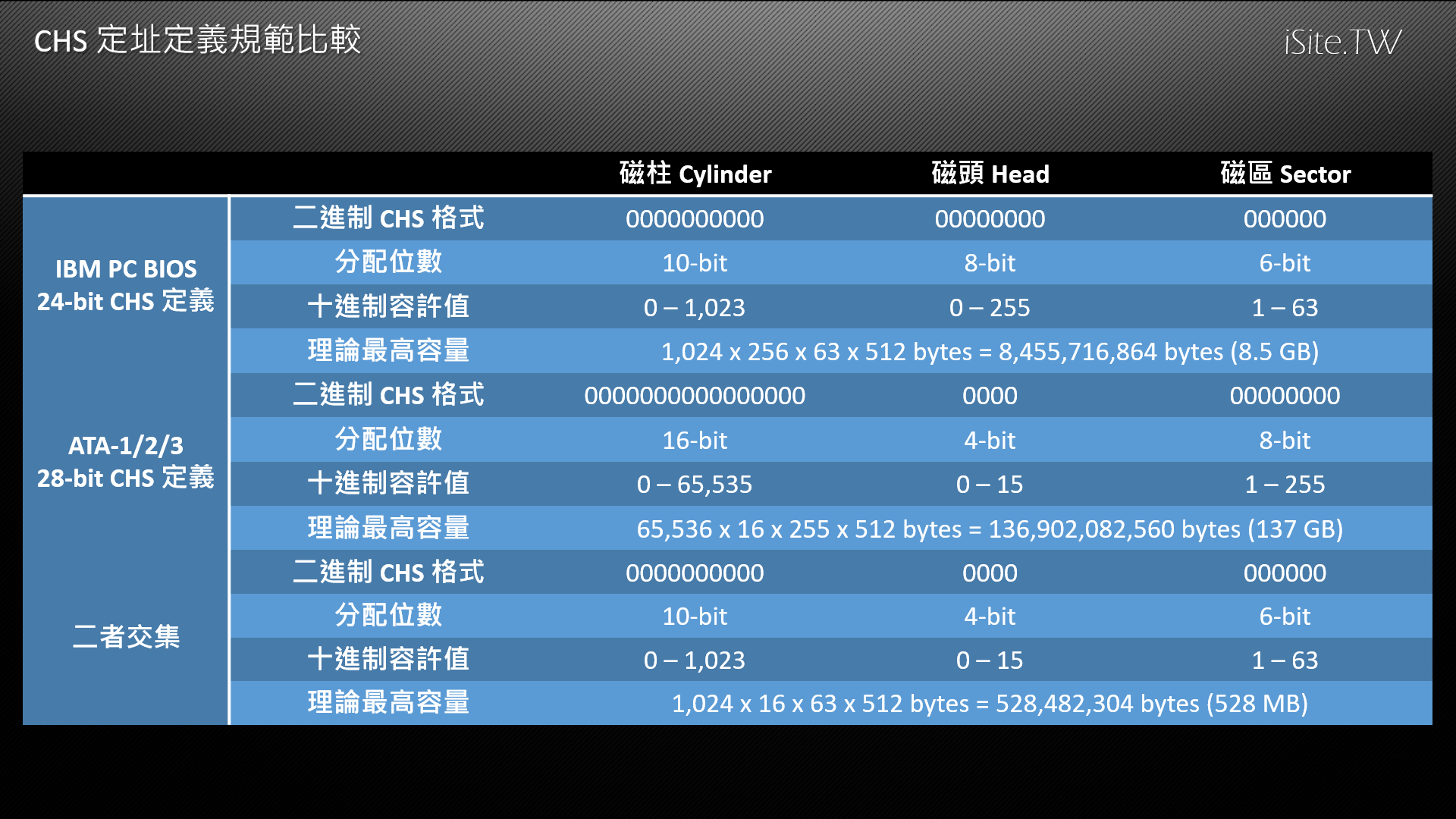
但後來的情況卻不是當年工程師所想的那樣,時至今日硬碟磁盤數量再怎麼多通常也不會超過 8 片,最多也就只有 16 面而已,根本不可能用到 255 個磁頭定址,這導致依照這種 CHS 定義規則設計出來的系統能夠定址的磁碟容量就變得有限許多,遠遠達不到原先理論估計的 8.4 GB。
而後來發展的 ATA 規範所採用的 CHS 定義規則則是將採用 28 位元定址,且磁頭被分配的位數只剩下 4 位,磁區則增加為 8 位,磁柱更是提高為 16 位,將理論上限提高至 137 GB,但卻引發了相容性問題,在早期的系統上只能正常存取 BIOS 定義與 ATA 規範定義的最大共同範圍內的定址-也就是磁柱 10 位元,磁頭 4 位元,磁區 6 位元,結果反而使最大容量被限縮到只剩下 528 MB,直到 1996 年廠商才透過在 BIOS 內新增大型硬碟模式 (Large Mode) 將磁頭的定義位數減少兩位並將空出來的二個位元重新分配給磁柱的方式使可支援的硬碟容量增加至 2.1 GB。
LBA 定址系統
然而,如同前面所提及的,實際上對軟體而言其只需要能夠標定出所有磁區的正確位置就足夠了,實際上軟體在讀寫資料時並不需要真正知曉每個磁區實際落在哪個盤面、哪條磁軌上,再加上越來越多非磁性儲存媒介的儲存裝置誕生 (這些裝置不採用磁性儲存媒介,因此自然也沒有甚麼磁軌、盤面的問題),因此後來的系統多改採 LBA 定址,這種方式非常直接,其實就只是直接賦予每個磁區一個專屬編號而已,可定址的理論最大容量會隨著位置編號的位數長度而持續指數增長。
磁區的結構
解決如何賦予磁區專屬位置以利使用的問題之後,接下來站長要談的是磁區本身的結構。

在傳統的架構中一個磁區可以存放 512 bytes 的資料,但一個完整的磁區並不是只由包含這 512 bytes 資料的區塊所組成,還要加上作為頭部的導入區塊 (Sync / DAM)、作為尾部的磁區間隙 (Gap) 與為了提高資料正確性而設計的 ECC 錯誤校正碼區塊這三個部分才能構成一個完整的磁區。
由此我們可以知道一個完整的磁區在磁盤上所佔據的面積實際上會略大於存放 512 bytes 資料所需要的最小空間,且每多存放 512 bytes 的資料就要多增加一組導入區塊、磁區間隙以及錯誤校正碼。
隨著硬碟的容量愈來愈大,單一磁盤上容納的磁區數量愈來愈多,這些不斷重複的導入區塊與磁區間隙就對磁盤上的面積造成了浪費,這就是接下來站長要談的「先進格式化 (Advanced Format)」的發展由來。
先進格式化 (Advanced Format,AF)
先進格式化雖然有著響亮的名字,但其實本質上並不是甚麼非常特別的技術,只是把原先單一磁區所容納的資料量由 512 bytes 提高至 4,096 bytes 而已,這使得硬碟在儲存相同大小的資料時所需要的磁區數量會下降為原來的四分之一,因此可以有效節省磁盤上被用做導入區塊與磁區間隙區域的面積,進而提高單位面積所能儲存的資料大小,根據 WD 的說法,採用先進格式化的硬碟磁盤單位面積所能容量的資料量可以提高約 11%。

若文字敘述上不是那麼好理解的話,搭配上方的示意圖應該就能很容易明白先進格式化到底是怎麼一回事了,值得注意的是由於先進格式化縮減磁區數目、提高單一磁區所包含的資料量後 ECC 錯誤校正碼區塊的數量也跟著減少,為了避免硬碟保存資料的可靠性下降,因此多數廠商在先進格式化硬碟上所使用的 ECC 錯誤校正碼區塊會較原先來得大,以彌補磁區數量減少之後 ECC 錯誤校正碼區塊縮減的問題。
磁碟分割
在談完磁區的架構與定址之後,下一個要探討的議題就是作業系統如何去應用這些磁區,為了方便使用與提高相容性、效率,作業系統不會直接依據前述的實體結構使用磁碟空間,作業系統會將特定範圍的磁區以虛擬的方式組織在一起進行應用,其中與使用者日常使用最為相關且最大的單位即為磁碟分割。
目前個人電腦所使用的磁碟分割方式主要有 MBR 與 GPT 兩種,其中前者多用於較老舊的電腦,近幾年的新電腦大多以 GPT 模式為主,接下來站長會分別介紹這兩種磁碟分割模式,由於相較於近年已成為主流的 GPT 磁碟分割模式而言,傳統的 MBR 磁碟分割模式的架構較為單純,因此我們先從 MBR 磁碟分割模式開始看起。
主要開機紀錄 (Master Boot Record,MBR)
在電腦啟動時會先從磁碟上的第一個磁碟區開始讀起 (即 CHS 定址編號 0,0,1 的磁區,這個磁區被特別命名為主要開機磁區 Master Boot Record,縮寫為 MBR),這個 512 bytes 大小的磁區當中包含了啟動程序、磁碟分割表 (Disk Partition Table,DPT)兩大部分,其中啟動程序佔據絕大部分空間 (約 446 bytes 左右),磁碟分割表則固定佔據 64 bytes 的空間。
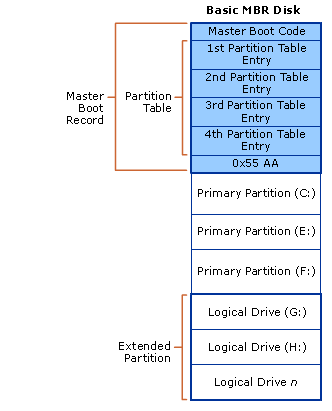

而這固定的 64 bytes 空間會被分為四組,每組分別代表一個磁碟分割,依照下列的格式紀錄這個磁碟分割的各種基本特性:
| 位置 | 長度 | 內容 |
| 00H | 1 bytes | Boot indicator bit flag 標示是否為啟動磁碟) |
| 01H | 1 bytes | 起點磁頭 |
| 02H – 03H | 2 bytes | 起點磁區、磁柱 |
| 04H | 1 bytes | 檔案系統類型 |
| 05H | 1 bytes | 終點磁頭 |
| 06H – 07H | 2 bytes | 終點磁區、磁柱 |
| 08H – 11H | 4 bytes | 起點磁區的 LBA 定址 |
| 12H – 15H | 4 bytes | 總磁區數 |
從上面的格式我們可以知道 MBR 磁碟分割表主要紀錄的事項包含了該分割是否為啟動磁碟、該分割在磁性儲存媒介上的起點與終點、該分割所使用的檔案系統類型與其實際大小這四項資料,且分割的起點與終點是採用前面提過的 CHS 定址方式標示的。
MBR 磁碟分割表的限制
在了解 MBR 磁碟分割表的格式之後我們可以很明顯發現 MBR 磁碟分割表的規範非常固定且使用了過時的 CHS 定址編碼格式,隨著時代發展這些特性就導致了 MBR 磁碟分割表開始有不敷使用的情形出現,例如固定只能存放四組磁碟分割紀錄導致一個磁碟上最多只能有四個分割區、使用 CHS 定址限制了所能取用的磁碟空間範圍等,而在 GPT 被發展出來之前,人們也發展了多種方式來暫時繞過這些限制,例如延伸分割區、改採相對 LBA 位置定址為主要定址方式等。
延伸磁碟分割
隨著硬碟容量的增長,單一硬碟上建立多個磁碟分割區的需求開始增加,但如同前面提過的,MBR 磁碟分割表在設計上是由固定的四組 16 bytes 磁碟分割紀錄所組成,本身並沒有預留擴充的空間,因此理論上每個硬碟上只能建立四個磁碟分割區,為了突破這個限制,因此後來便發展出了「延伸磁碟分割」的作法。


延伸磁碟分割的基本概念在於將硬碟上的磁碟分割區重新定義為主要磁碟分割與延伸磁碟分割兩類,其中現有直接利用標準 MBR 所能給予的四組磁碟分割紀錄的普通磁碟分割被重新命名為「主要磁碟分割 (Primary partition)」,當使用者需要在同一硬碟上建立超過四個磁碟分割時,延伸磁碟分割定義允許「犧牲」MBR 當中的一筆記錄空間用於建立虛擬的「延伸磁碟分割 (Extended partition)」。
在延伸磁碟分割的範圍內使用者可以建立多個「邏輯磁碟區 (logical volume)」,而每個邏輯磁碟區的起點磁區都會具有類似第一個磁區的 MBR 結構,稱之為延伸開機紀錄 (Extended Boot Record, EBR),當中會記載此邏輯磁碟區的起點、終點等資訊以及下一個 EBR 磁區的位置,透過這樣的方式來實質突破單一硬碟上只能有四個分割區的限制。
但要特別注意的是,邏輯磁碟區並不能做為啟動磁碟使用,除此之外在日常用途中與主要磁碟分割並沒有什麼顯著差異。
定址能力的延伸
除了磁碟分割的數量上限外,另一項 MBR 磁碟分割的主要限制則是來自其所能定址的硬碟大小範圍,在最初的設計中 MBR 磁碟分割紀錄主要是依賴 CHS 定址格式的起點、終點磁區來進行磁碟分割區的定位,但如同前面提及的,CHS 定址格式的最多只能定址約 8.4 GB 的磁碟空間,為了能夠使用超出 8.4 GB 部分的磁碟空間,因此原有的定址機制勢必需要調整。
但好在當初設計 MBR 時磁碟分割表當中除了 CHS 定址格式的磁碟分割區起點、終點之外還設計了紀錄以 LBA 格式定址的絕對起點磁區位置 (長度為 4 位元組) 與各磁碟分割的總磁區數 (長度亦為 4 位元組),因此可以透過轉向採用 LBA 定址為主、忽略原有基於 CHS 格式定址的起終點磁區位置之方式來大幅擴增 MBR 磁碟分割表的定址能力,從原有的 8.4 GB 一舉提升至 2.2 TB (4 位元組長度的位址包含 32 個位元,可定址出 2^32 個磁區,即 4,294,967,296 個磁區,以每個磁區 512 bytes 計算即為約 2.2 TB)。
GUID 磁碟分割表 (GUID Partition Table,GPT)
隨著電腦硬碟容量的快速發展,個人電腦硬碟的容量迅速逼近 MBR 磁碟分割表所能定址的最大上限 2.2 TB,為了解決這個問題與修正 MBR 磁碟分割表在多年使用過程中為了實際使用需求而做出的妥協措施所造成的各種混亂與規範不一,Intel 在發展可延伸韌體介面 (UEFI) 時一併提出了全新的磁碟分割表規範 GPT。
GUID 磁碟分割表的基本結構
相較於 MBR 將整個磁碟分割表全部塞在第一磁區而言,採用 GUID 磁碟分割表的硬碟會使用多個磁區存放磁碟分割表,除了第 0 磁區為了維持與 MBR 的相容性會塞入格式類似於 MBR 的保護性 MBR (Protective MBR)、第 1 磁區會放置 GUID 磁碟分割表的表頭 (包含分割表位置、定義磁碟可用空間、分割表目前的項目數量等資訊) 之外,GUID 磁碟分割表會使用多個磁區用於存放磁碟分割表。
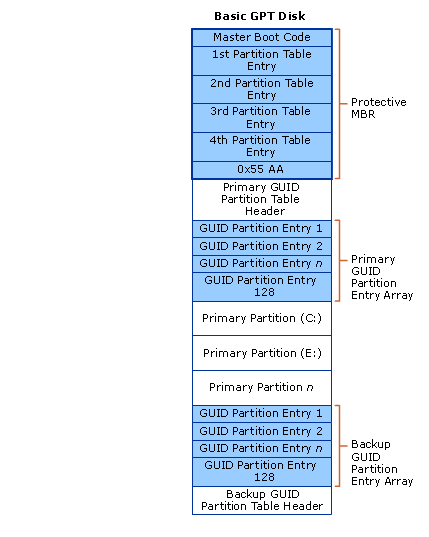

根據分配給磁碟分割表的磁區數多寡可以彈性擴增 GUID 磁碟分割表所能支援的磁碟分割數量,但在 Windows 系統中固定為使用 32 個磁區,因此在 Windows 系統中採用 GPT 格式的硬碟實際用於存放資料的磁區是自第 35 個磁區起 (LBA 編號為 34)。
保護性 MBR (Protective MBR)
出於相容性與避免資料損毀上的考慮,在 GPT 格式硬碟當中第一個磁區 (LBA 編號 0) 依然會擺放一組格式基本上與傳統 MBR 一致的數據,當中除了與傳統 MBR 一樣會容納初始啟動程序之外還會包含一個類型標示為 0xEE 的特殊分割區,作為該硬碟採用 GPT 格式的識別依據。
這樣的做法有什麼意義呢?實際上主要是為了讓不支援 GPT 格式的作業系統在讀取 GPT 格式的硬碟時會偵測到一個類型不明的磁碟分割區,從而避免系統誤以為該硬碟為空白硬碟而逕自使用導致該硬碟上的資料產生毀損,並且也避免使用者在不支援 GPT 格式的作業系統下因看不見依循 GPT 格式規範所建立的分割區而意外將這些分割區覆蓋或移除。
GUID 磁碟分割表頭 (GPT Header)
GPT 格式磁碟上的第二個磁區 (LBA 編號 1) 則固定作為 GUID 磁碟分割表的表頭使用,包含了 GPT 版本識別、表頭位置與可用空間的起點與終點等資訊,此外為了避免 GUID 磁碟分割表表頭損毀,在 GPT 格式規範中會將此磁區內的所有資訊複製一份放在硬碟上的最後一個磁區中。
| 位置 | 長度 | 內容 |
| 00H – 07H | 8 bytes | EFI PART (固定識別標示) |
| 08H – 11H | 4 bytes | GPT 版本標示 |
| 12H – 15H | 4 bytes | 表頭長度 |
| 16H – 19H | 4 bytes | 表頭的 CRC32 校驗碼 |
| 20H – 23H | 4 bytes | 固定為 0 |
| 24H – 31H | 8 bytes | 當前表頭所在的磁區 LBA 定址 |
| 32H – 39H | 8 bytes | 另一表頭所在的磁區 LBA 定址 |
| 40H – 47H | 8 bytes | 首個可用磁區的 LBA 定址 |
| 48H – 55H | 8 bytes | 最後可用磁區的 LBA 定址 |
| 56H – 71H | 16 bytes | 此硬碟的 GUID |
| 72H – 79H | 8 bytes | 首個分割表項目所在的 LBA 定址 |
| 80H – 83H | 4 bytes | 分割表項目數量 |
| 84H – 87H | 4 bytes | 單一分割表項目的長度 |
| 88H – 91H | 4 bytes | 分割表項目的 CRC32 校驗碼 |
| 92H 起 | 剩餘空間 | 全數填 0 |
GPT 磁碟分割紀錄 (Partition Entries)
自第三個磁區 (LBA 編號 2) 起即為存放 GPT 磁碟分割紀錄的位置,不同於 MBR 當中每筆磁碟分割紀錄的長度僅有 16 bytes,由於 GPT 格式內的磁碟分割紀錄不再需要與初始啟動程序共用第一磁區的空間,因此 GPT 格式中各筆磁碟分割紀錄的長度一舉大幅提高至 128 bytes (每個磁區所能存放的磁碟分割紀錄則仍然維持四筆,但可透過增加用於存放磁碟分割紀錄之磁區數量的方式來彈性增加可建立之磁碟分割紀錄數量,在 Windows 系統中目前固定為 32 個磁區,因此可存放多達 128 筆磁碟分割紀錄)。
除了可用的紀錄空間增加外,GPT 格式中的磁碟分割紀錄同時還捨棄了 CHS 定址欄位,改為採用加長一倍的 LBA 定址來標示磁碟分割區的起點與終點,大幅提升了其所能處理的磁碟空間大小 (在使用 512 bytes 大小磁區的情況下可高達 9.44 ZB)。
此外,與 GUID 磁碟分割表頭相同,在 GPT 格式中為了避免磁碟分割表遭遇損毀的情況,在設計上會將所有存放磁碟分割紀錄的磁區內的所有資訊複製一份,依序自硬碟的倒數第二個磁區往反向放置在硬碟的最末端。
| 位置 | 長度 | 內容 |
| 00H – 15H | 16 bytes | 磁碟分割類型 (GUID 格式) |
| 16H – 31H | 16 bytes | 磁碟分割的唯一識別碼 (GUID 格式) |
| 32H – 39H | 8 bytes | 起點磁區 LBA 定址 |
| 40H – 47H | 8 bytes | 終點磁區 LBA 定址 |
| 48H – 55H | 8 bytes | 磁碟分割特性標示 |
| 56H – 127H | 72 bytes | 磁碟分割名稱 |
作業系統對 GPT 格式硬碟的支援
從前面的敘述我們大致可以知道 GPT 格式幾乎在各方面都比傳統的 MBR 磁碟分割表來得強大,但由於是較晚提出的標準,因此並非所有作業系統都能正常搭配 GPT 格式的硬碟使用,有部分較老舊的作業系統可能僅能支援對 GPT 格式的硬碟進行一般的讀寫操作,但並無法直接自 GPT 格式的磁碟分割啟動。
| 作業系統 | 讀寫操作 | 啟動磁碟 | 備註 |
| Windows 2000 或更早版本 | 不支援 | 不支援 | |
| Windows XP (32 位元) | 不支援 | 不支援 | |
| Windows Server 2003 (32 位元) |
支援 | 不支援 | 自 Service Pack 1 起支援 |
| Windows Server 2003 (64 位元) | 支援 | 僅 IA64 版本支援 | 自 Service Pack 1 起支援 |
| Windows Vista / Server 2008 (32 位元) |
支援 | 不支援 | |
| Windows Vista / Server 2008 (64 位元) | 支援 | 支援 | |
| Windows 7 (32 位元) |
支援 | 不支援 | |
| Windows 7 / Server 2008 R2 (64 位元) |
支援 | 支援 | |
| Windows 8 (32 位元) |
支援 | 不支援 | |
| Windows 8 / Server 2012 (64 位元) |
支援 | 支援 | |
| Windows 8.1 (32 位元) |
支援 | 不支援 | |
| Windows 8.1 / Server 2012 R2 (64 位元) |
支援 | 支援 | |
| Windows 10 (32 位元) |
支援 | 不支援 | |
| Windows 10 / Server 2016 (64 位元) |
支援 | 支援 | |
| Windows Server 2019 (64 位元) | 支援 | 支援 | |
| Windows 11 (64 位元) |
支援 | 支援 | |
| Windows Server 2022 (64 位元) | 支援 | 支援 |