

在 2000 年我們說個人電腦圖形界最大的變革是將原本由 CPU 負責的 T&L 運算移交給 GPU,隨著時間即將進入 2001 年,下一場革命也已經在醞釀當中,基本上 2000 與 2001 年應該是 GPU 架構變動最劇烈也最為密集的兩年。
2001:可程式化管線架構

由於 DirectX 從 6.0 版本開始在市場上占有重要地位,從 7.0 版本開始與 OpenGL 成為市場上唯二的主流 (GLIDE 已經躺在旁邊半死不活了),但 OpenGL 直到 2003 年之前其實都沒有引入太大的變革,因此 2001 年 GPU 架構上出現的革新基本上幾乎可以說是與 DirectX 8.0 的發展切齊的,所以接下來我要先稍微介紹一下 DirectX 8.0 引入的新特色。
發展方向的轉變
在 2001 年以前,基本上 GPU 的發展目標非常明確,除了增加每秒能生成的多邊形數量之外,就是盡可能在同樣時間內處理更多、更複雜的材質貼圖,在 3D 圖形的初期來說,這樣的做法絕對是正確的,畢竟構成圖形用的多邊形不夠多,立體圖形就會顯得粗糙;材質貼圖不夠複雜、豐富,立體圖形的表面看起來就不真實,在這樣的思維底下,為了追求速度與避免過於複雜的架構設計,當時的顯示晶片中的各個單元的功能是「固定」的,只能根據晶片上設計好的模式 (State) 來運作,每個步驟要做哪些事情都是固定的,並不能隨著場合不同而有所變動,稱之為固定功能管線 (Fixed Function Pipeline)。
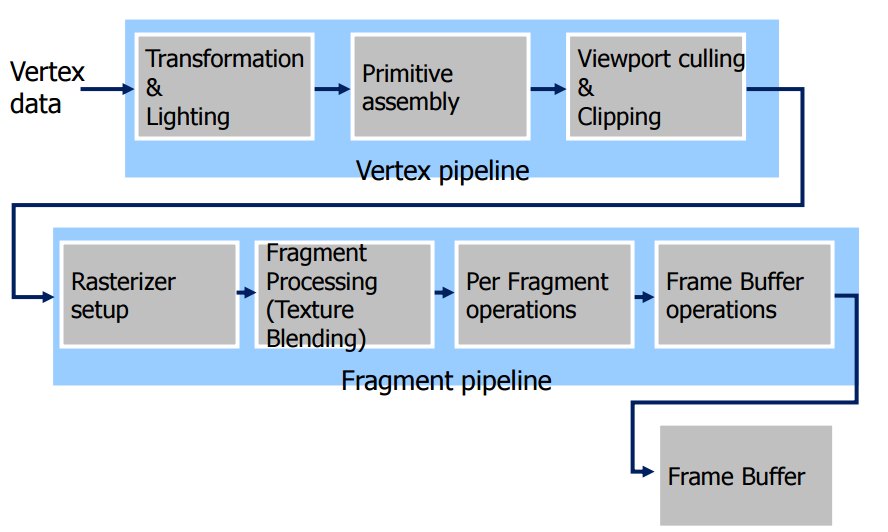
舉例來說,一筆資料進入 GPU 之後,首先要進行頂點處理、T&L 運算、多邊形生成、視角運算、材質貼圖等過程,如同大量生產的生產線一般,每個像素需要經過的工序都完全相同,不能因用途不同而運用軟體方面的手段給予差別待遇。
固定功能管線的困境
但是在面對更加複雜 (卻也更加現實) 的 3D 畫面時,舊有的思維顯然是不敷使用的,舉例來說,在大自然的景象當中經常出現的水面波紋,若用原有的思維來處理,顯然得把整個畫面拆成 N 多倍數個的多邊形與 N 多倍複雜的貼圖來處理,但這樣肯定是不合效益也不切實際的吧?在這種時候,如果可以讓這些功能能夠依據實際狀況來隨機應變,那不是很好嗎?於是人們開始思考,要怎麼樣讓 GPU 內的各個部分「更有彈性」一些。
首先要思考的問題是,要達到這個目的我們該從硬體著手還是軟體著手呢?如果從硬體著手,那顯然我們得在硬體上老老實實地把各種不同功能的電路通通塞進去,但這顯然會造成電路複雜度無量上升,連帶導致晶片的設計、生產成本也一飛衝天,所以這條路顯然行不通。
既然從硬體硬上的手段行不通,顯然我們得加上軟體的協助。於是我們得回到整個電腦的架構開始重新思考,顯然在電腦當中與 GPU 在設計上最為接近,又能根據軟體交辦的事項隨時隨機應變處理各種運算的代表就只有 CPU 了,那麼我們如果像設計 CPU 那樣,把顯示晶片上負責「某些功能」的「某些部分電路」改成「支援某些功能」的「處理器」,是不是就能達到我們要的目的了呢?
Shader Model 的誕生
於是為了達到剛剛所說的目的,微軟在 DirectX 8.0 當中首次引入了被稱為「Shader Model」的概念,而在 DirectX 8.0 當中,Shader Model 主要又可以分為 Vertex Shader (頂點渲染器) 與 Pixel Shader (像素渲染器) 兩種。
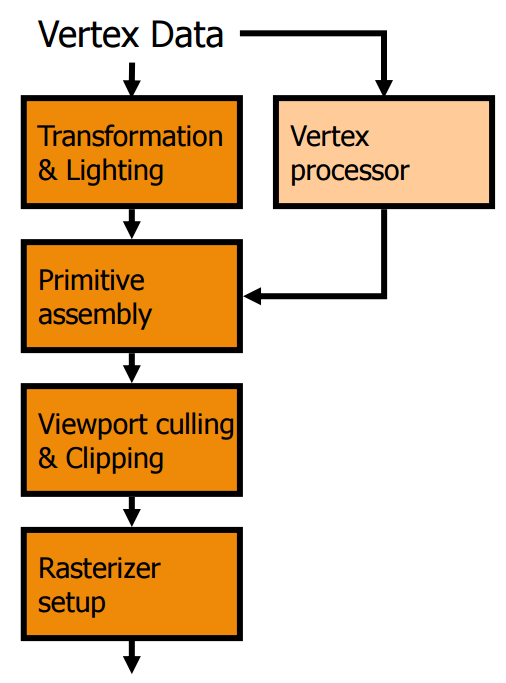
單從字面上來看可能不是很容易了解這兩種渲染器到底有甚麼功能,所以我們要再次回到剛剛看過的固定功能管線上,以往像素資料進入 GPU 時,要先經過 GPU 內「硬體 T&L」運算電路的處理,而 Vertex Shader 實際上就是用來取代原本在 2000 年剛剛加入 GPU 內不久的硬體 T&L 電路用的,本質上如同前面所說,可以想像成一種「主要指令集由各種 T&L 相關功能組成」的「小型處理器」,於是軟體工程師就可以透過編寫軟體的方式來達到一定程度上彈性調整、改變 T&L 功能的效果了。
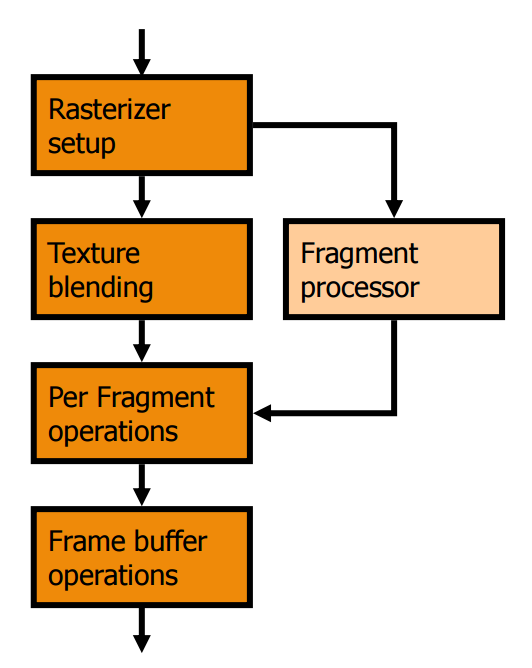
至於 Pixel Shader 的部分其實也是基於差不多的想法發展出來的,主要是用於取代原本負責將材質貼圖與像素融合這道工序的電路之用,在經過這樣的變革之後,軟體工程師能夠發揮的地方一下子多了很多,因此在 DirectX 8.0 開始遊戲的畫面品質可以說是有了飛躍性的成長 (儘管第一版的 Shader Model 還很陽春,而且只能用低階語言控制),接下來基本上每次 DirectX 的改版都多多少少會對 Shader Model 做一點更新,例如根據軟體工程師的需要來增加這些 Shader 所能支援的指令之類的,最後,由於從這個時期開始,軟體工程師可以透過程式來控制甚至改變 Shader 的功能或表現,因此被稱之為「可程式化管線」(Programmable Pipeline)。
NVIDIA GeForce3 (NV20)
發佈時間:2001 年 03 月
API 支援:Direct3D 8.0、OpenGL 1.2
Shader Model 版本:Vertex Shader 1.1, Pixel Shader 1.1
像素渲染器 (PS):4 組/頂點渲染器 (VS):1 組/材質對應單元 (TMUs):8 組/著色輸出單元 (ROUs):4 組

NVIDIA 在 2001 年初推出的 GeForce3 是世界上第一款配合 DirectX 8.0 規範而推出的產品,基本上是從上一代的 GeForce2 修改而來,同樣是採用 4 條像素管線、8 組 TMU 與 4 組 ROU 的配置,但如同其代號又再次從 NV15 跳到 NV20 所顯示的,在架構上 GeForce3 的變動其實很多。

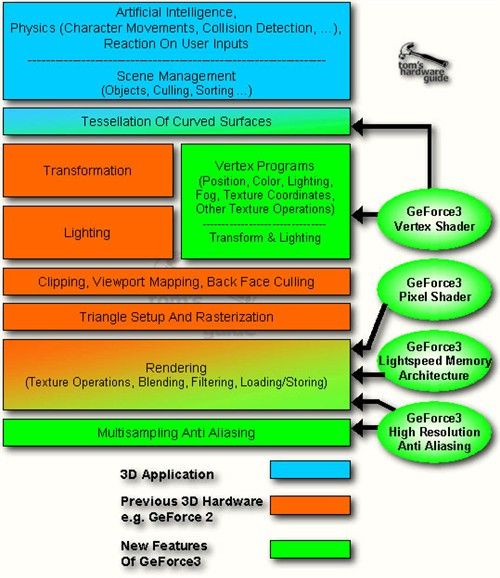
相較於上代產品來說,GeForce3 最主要的改進有三個地方,首先要提的是被 NVIDIA 官方稱之為 nFinite FX Engine 的技術,實際上 nFiniteFX Engine (有不少人懷疑這名字是不是與 3dfx 有關,畢竟 NVIDIA 剛在幾個月前收購了 3dfx 的所有技術,不過我個人認為應該只是名字用到而已,畢竟距離收購案宣布只過了三個月而已) 就是我們剛剛花費不少篇幅探討的 Shader Model,這是 GeForce3 與前作之間最大的不同。

但 nFiniteFX Engine 的引入實際上並沒有讓 GeForce3 成為一代成功的 GPU,一方面因為初期能夠得益於這項技術的遊戲軟體並不多 (跟 GeForce256 第一次加入硬體 T&L 時的狀況很像),另一方面是因為牽涉到架構方面的大幅改變與重新設計,這很大程度影響了 GeForce3 的實際表現與生產良率 (這又直接影響了生產成本,並且進一步牽動了價格)。
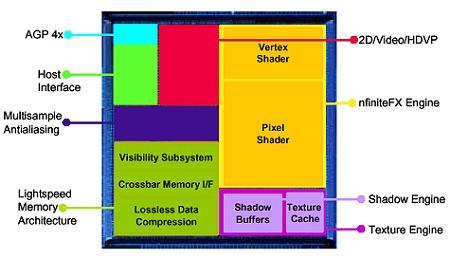
第二個不同則是在記憶體頻寬的利用機制上,GeForce3 引入了被稱之為光速記憶體架構的 Lightspeed Memory Architecture (LMA) 技術,有效解決了過去 GeForce256 與 GeForce2 最大的弱點-記憶體頻寬不足,某種程度上你可以把它當成 NVIDIA 家的 HyperZ 技術來看 (儘管實作的方式並不完全相同,但目的與結果是相似的,也用到了一些類似的東西,像是 Z-Buffer 壓縮技術之類的)
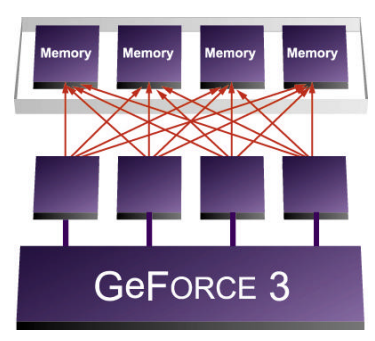

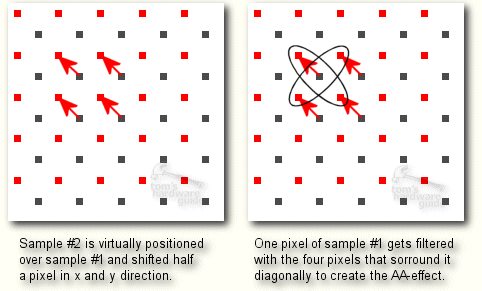
而最後一項不同則比較沒有前兩項那麼來得重要,GeForce3 的反鋸齒能力相較於前幾代 GeForce 來說有了明顯的提升,NVIDIA 將這項技術稱為「高解析度反鋸齒 (HRAA)」,具體上來說是運用一種稱為「Quincunx」的特殊演算法 (抓兩條對角線組成一個梅花點的形狀) 來執行多重取樣反鋸齒 (MSAA),由於需要的取樣點比起以往使用超取樣反鋸齒 (SSAA) 時來得少,所以在速度上比起 SSAA 來得快上許多,但是在效果上又與過去使用的反鋸齒相差無幾 (理論上 2x Quincunx MSAA 差不多就能有 4x SSAA 等級的效果)。
至於在系列編成的部分呢,相較於 GeForce2 由 GTS 與 MX 兩大家族分別負責高、低階市場的作法而言,GeForce3 的家族組成顯得單薄許多,受到第一次導入可程式化管線設計但技術還不夠成熟的影響,最原始的 GeForce3 (2001 年 02 月推出) 由於在繪圖管線配置上與 GeForce2 GTS 很相近 (有著幾乎相同的理論像素填充率),因此在性能測試中沒辦法佔到太多便宜 (甚至由於時脈較低,很多時候還會反過來輸給 GeForce2 Ultra),基本上可以視為具備可程式化管線設計的 GeForce2 GTS,但由於價格高昂許多卻沒能帶來太多性能提升,因此在市場上並未獲得太多親睞,可以算是典型的「付出很多心力卻沒甚麼收穫」的案例 (下圖當中綠色的部分就是 GeForce3 有大改變的部分)。
這樣的尷尬情況大約要等到 2001 年 10 月 NVIDIA 重新規劃 GeForce 家族,以 GeForce Ti 為名將整個家族的階級分別整個砍掉重練才有所好轉,新的 GeForce Ti 家族包含針對頂級市場推出的 GeForce3 Ti 500、對應中高階市場的 GeForce3 Ti 200 與目標為低階入門市場的 GeForce2 Ti (比 GeForce2 Ultra 還要略差一點的型號,處理能力大致相同,但記憶體頻寬降到 GeForce2 Pro 等級) 三種 (在這個時期裡 Ti 是「最高 CP 值」的象徵,並不是如同目前 GeForce GTX980 Ti 中的 Ti 代表「強化高級版本」的意思)。

面向頂級市場的 GeForce3 Ti 500 實際上是 GeForce3 的時脈提升版本,運作時脈從原本的 200/460 MHz 大幅提高到 240/500 MHz,直到這之後 GeForce3 的性能表現才真正具有競爭力 (畢竟是當家旗艦,新科旗艦居然打不過上代王牌說真的很難看),至於面向主流市場的 GeForce3 Ti 200 則是「GeForce3 的降頻版本」,價格上比 GeForce3 還要略低,但是性能基本上經常輸給 GeForce2 Ultra,甚至在對上 GeForce2 Ti 時也是如此,並沒有太大的可看性,設計這款型號的主要目的大概只是為了加快可程式化管線與 DirectX 8.0 的普及吧?

至於為什麼 NVIDIA 不比照 GeForce2 時代的做法推出 GeForce3 MX 來擔當主流與入門市場的主角呢,其實不是「不想」,是技術上還「做不到」,當年由於 GeForce3 第一次導入許多全新的架構設計,因此在良率上的表現一直都不夠理想,反映在成本上之後自然導致 NVIDIA 實際上很難以足夠低的成本來設計出低階入門版本的 GeForce3 MX,畢竟賠錢的生意沒人肯做的。
ATI Radeon R200 (8000 系列、9000 系列低階版)
發佈時間:2001 年 08 月 (R200)、2002 年 08 月 (RV250)、2003 年 04 月 (RV280)
API 支援:Direct3D 8.1、OpenGL 1.4
Shader Model 版本:Vertex Shader 1.1, Pixel Shader 1.4
像素渲染器 (PS):4 組/頂點渲染器 (VS):1 組/材質對應單元 (TMUs):8 組/著色輸出單元 (ROUs):2 組 (R200)
像素渲染器 (PS):4 組/頂點渲染器 (VS):1 組/材質對應單元 (TMUs):4 組/著色輸出單元 (ROUs):1 組 (RV250、RV280)
進入 21 世紀的 GPU 產業早已與 20 世紀末大有不同,隨著 OpenGL 與 DirectX 的興起主宰了整個個人電腦 3D 圖形的天下,GPU 開發已經不必像過去那樣瞎子摸象般的尋找未來趨勢並擔心一跟不上、一給對手可乘之機可能就會被其他競爭對手給取代的問題,最基本的發展方向是很清楚的,跟著 API 走基本上不會有太大的問題 (而設計 API 的微軟與 OpenGL 組織實際上也會與 GPU 廠商互動來發展更強大的 API)。

因此在 NVIDIA 推出 GeForce3 進入 DirectX 8 與可編成化管線的時代時,ATI 當然也不可能不跟隨時代的腳步走上相同的道路,不過這次 ATI 不搶快的策略倒是押對寶了,因為在 DirectX 8.0 規範推出後沒幾個月,微軟就發布了 DirectX 8.1 作為 DirectX 8.0 的補充 (主要是 Shader Model 方面的改進,可以支援的規格參數更高也更有彈性),於是 GeForce3 上市沒多久就面臨了「不支援最新版 DirectX」的窘境,這某種程度上導致了 GeForce3 終究只能做為過渡產品的命運。
儘管晚了幾個月,但是 Radeon R200 在 2001 年 08 月得以「全球第一款完整支援 DirectX 8.1 的 GPU」稱號風光上市,對於 ATI 的市占與評價提升有著一定的作用,而且最值得紀念的是-這是有史以來第一次 ATI 的 GPU 產品在功能方面得以超越 NVIDIA 當下的旗艦。
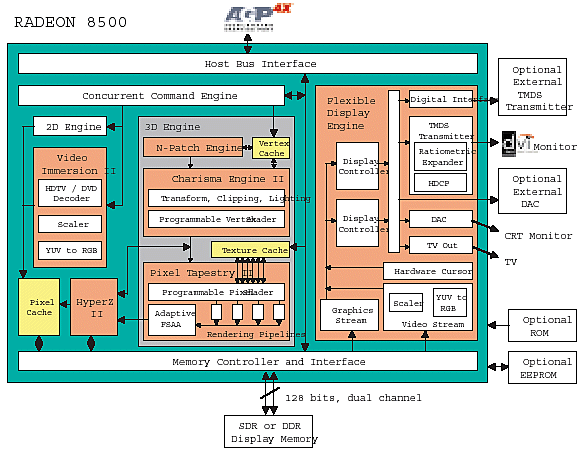
首先從架構看起,還記得之前我們談到 Radeon R100 系列的時候有特別提到 Radeon R100 的像素管線配置 (Charisma Engine) 很特別嗎?當時為了支援三重紋理貼圖所以 ATI 給每條像素管線設計了三組紋理對應單元 (TMUs),但實際上絕大多數程式都只能活用雙重紋理貼圖因此多出來的那組 TMU 其實往往沒甚麼事情可做,因此造成了 Radeon R100 理論性能高於 GeForce2,但卻沒辦法反映在實際使用中的問題。而 Radeon R200 就沒有這個問題了,ATI 不再堅持三重紋理貼圖技術,每組像素渲染管線 (Charisma Engine II) 都只設計了兩組 TMUs 可供使用,而多出來的空間則是用來將像素渲染管線的總數一口氣加倍增加到了四組。

受到架構更加貼近實際需求,得以大幅提升 TMU 資源的使用效率,而且像素管線的組數大有成長的因素影響之下,Radeon R200 相較於 R100 來說在性能上有了非常大的成長 (特別是與 GeForce3 的「不長進」兩相對照之下感覺更明顯)。

除此之外 Radeon R200 也首次加入了 ATI 自行研製的曲面細分硬體加速引擎-TruForm (如下圖與上方影片,不過由於使用上相當依賴開發者編寫程式時的方法,而且只在一些特定的狀況下有好的效果,因此採用率並不高,在後續產品中就見不到這個硬體加速單元了,改為使用軟體支援的方式呈現,直到 2007 年的 Radeon HD 2000 系列才又加入類似功能的硬體加速單元)。

不過儘管硬體上 Radeon R200 大致上解決了 Radeon R100 中有的問題,並且追上 NVIDIA 進入了可程式化管線世代,甚至在功能性方面超越了 NVIDIA (特別是 Pixel Shader 1.4 的支援),但這款產品最大的敗筆就是驅動程式,上市初期的驅動程式甚至幾乎沒辦法正常進行遊戲,玩家光是看錯誤訊息與各種各式各樣的破圖、異常效果就飽了,這樣拙劣的驅動程式根本無法完整發揮 Radeon R200 晶片的實際能力 (特別是反鋸齒的部分,ATI 似乎根本沒寫完驅動程式就趕著讓 Radeon 8500 上市了,當時的驅動程式只能在 Direct3D 模式下提供反鋸齒功能,而且速度慢到非常驚人的地步)。

看過架構上的簡單介紹之後,接下來我們回到產品本身來看,Radeon R200 晶片先後有三個衍伸型,分別是最原始的 R200 與針對中低階市場推出的 RV250、在 R300 系列推出之後用來擔當入門級產品的 RV280 三種,儘管 ATI 曾經試圖發展以 R200 為基礎的強化版本 R250 (可能會稱為 8500 XT,預計的時脈配置高達 300/600 MHz),並希望能將 R250 用來對抗 NVIDIA 的新科旗艦 GeForce4 Ti,但或許是看到了 3dfx Rampage 的前車之鑑吧?最後 ATI 選擇放棄 R250 計畫直接進攻下一世代的 R300。
R200 後來以 Radeon 8500 的名義發售 (時脈設定為 275/550 MHz),之後隔年二月又推出了降頻版本稱之為 Radeon 8500 LE (降頻至 250/500 MHz),而在 R300 系列推出之後 Radeon 8500 LE 又被改名為 Radeon 9100 發售,這與 NVIDIA GeForce Ti 應該是 NVIDIA 與 ATI 一直以來幫老 GPU 改名舊瓶裝新酒重新上架惡習的開端。

至於 RV250 則是在 2002 年 08 月 (在 R300 推出前一兩個月時) 針對中低階市場推出的版本,砍掉了一組頂點渲染器與一半的像素對應單元、拿掉了 TruForm 硬體加速單元,並以 Radeon 9000 (時脈設定為 200/500 MHz) 與 Radeon 9000 Pro (時脈設定為 275/550 MHz) 的名義發售,作為 Radeon 9000 系列的最入門產品。

最後要提的則是 RV280,這款產品與 RV250 很接近,唯一的差別為 RV280 加入了對 AGP 8x 的支援,除此之外幾乎一模一樣,定位與性能還是比 R200 低,但最後卻用了 Radeon 9200 (時脈設定為 250/400 MHz)、Radeon 9200 SE (時脈設定為 200/333 MHz,而且記憶體頻寬砍半) 的名義發售,這在當時應該是有史以來整個顯示晶片發展史當中命名最亂的一次 (ATI 官方後來號稱 7000 系列是只支援 DirectX 7.0 API、8000 系列是能支援 DirectX 8.1 API、9000 系列則是能夠支援 DirectX 9.0 API 的意思,不過 Radeon 9200 等基於 R200 系的產品顯然是不能支援 DirectX 9.0 的)。

基於 R200 晶片架構的最後一款產品則是 2004 年 07 月推出的 Radeon 9250,雖然型號看起來最大但實際上只是時脈比較高的 RV280 罷了 (設定為 240/400 MHz)。
NVIDIA GeForce4 (NV25/NV17/NV18/NV28)
發佈時間:2002 年 02 月
API 支援:Direct3D 8.1、OpenGL 1.4 (NV25/NV28)
API 支援:Direct3D 7.0、OpenGL 1.2 (NV17/NV18)
Shader Model 版本:Vertex Shader 1.1, Pixel Shader 1.4 (NV25/NV28)
像素渲染器 (PS):4 組/頂點渲染器 (VS):2 組/材質對應單元 (TMUs):8 組/著色輸出單元 (ROUs):4 組 (NV25/NV28)
像素管線:2 條/材質對應單元 (TMUs):4 組/著色輸出單元 (ROUs):2 組 (NV17/NV18)

要談 GeForce4 之前我們得先對這代 GPU 的系列編成有基本的認識,GeForce4 在個人電腦上分為 MX 與 Ti 兩條產品線,雖然都叫做 GeForce4,但實際上兩者之間大不相同,如果你以為 GeForce4 MX 與 GeForce4 Ti 之間的關係和之前 GeForce2 GTS 與 GeForce2 MX 之間的關係很像的話,那你就上了 NVIDIA 的當了。
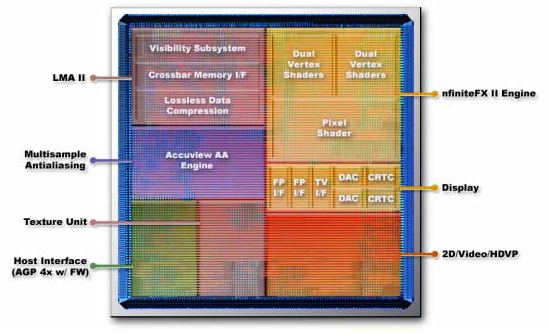
首先看到的是面向主流與高階市場的 GeForce4 Ti,從上面這張架構圖應該不難看出,相較於 GeForce3 來說基本上這代產品其實並沒有太大的變動,某種程度上可以看做是 GeForce3 的補完版,像是把被 ATI 超車的 DirectX 8.1 API 支援補上去了之類的改良,除此之外主要的改進有三大部分。

第一部分是關於繪圖管線配置,GeForce4 Ti 引入了第二代的 nFiniteFX 引擎,與 GeForce3 最主要的差別在於頂點渲染器從一組增加為兩組 (實際上這最早可以追溯到一款特化過的 GeForce3 晶片,NV2A 上,這款晶片是被用於初代微軟 Xbox 遊戲機的繪圖晶片,就具備了兩組頂點渲染器),靠著更加精進的頂點渲染器,GeForce4 Ti 每秒能處理的頂點數量相較於前作而言有了大幅度的提升 (不過其實我真心不太懂下面這段技術展示到底是想表達甚麼 XD)。

第二部分則是多螢幕的支援,NVIDIA 在 GeForce4 這一世代當中引入了被稱為 nView 的多螢幕技術 (其實說穿了就是內建兩組 RAMDAC 與 TDMS 輸出)。
第三部分則是記憶體頻寬利用方面再次獲得了改進,在 GeForce3 當中透過 Lightspeed Memory Archhitecture 來解決 GeForce2 當中記憶體頻寬嚴重不足的問題,而在 GeForce4 當中我們可以見到強化版的第二代 LMA 設計,透過演算法方面的改良,可以更進一步提高記憶體頻寬的利用效率,並加入了記憶體預充電技術,能有效降低讀取記憶體資料時的延遲。

至於系列編成的部分,GeForce4 Ti 系可分為前期、後期兩階段,前期 (2002 年 04 月起) 使用的是 NV25 核心,共有 GeForce4 Ti 4400 與 GeForce4 Ti 4600 兩個成員,這兩款的差異出現在運作時脈上,前者預設時脈為 275/550 MHz,後者則可以高達 300/650 MHz,而後來又加入了 GeForce4 Ti 4200 這款較為平價的版本,時脈更進一步下降,若搭配 128 MB 記憶體則記憶體頻寬還需要進一步砍半 (搭配 64 MB 的款式則沒砍)。

至於後期則是使用 NV28 核心 (2003 年 01 月起),僅有 GeForce4 Ti 4800 SE 與 GeForce4 Ti 4800 兩個版本,實際上前者就是原先的 Ti 4400 加入 AGP 8x 支援的版本,而後者則是以 Ti 4600 為基礎加入 AGP 8x 支援的版本。

得益於時脈的提升與第二組頂點渲染器的加入,GeForce4 Ti 毫無疑問是可以完封 GeForce3 系列的,也將才登上效能王者王位幾個月的 ATI 再次踹下王座。

接下來,在開始談 GeForce4 MX 之前,先想想聽到 GeForce4 MX 這名詞的時候,你會有甚麼樣的想像吧?
- 簡化版、入門版的 GeForce4?
- 當年難產而延期至今的 GeForce3 MX,所以是入門版的 GeForce3?
- 是 GeForce3 改名而來?
一般人的想法大概不出這三種吧?特別是對於知道 GeForce2 MX 是甚麼概念的人來說,多半應該會覺得 GeForce4 MX 應該就是低階版本的 GeForce4 Ti,不過實際情況並不是這樣,簡單來說,GeForce4 MX 其實只是昇級版的 GeForce2 MX,而且從 NVIDIA 官方給的比較表你看不出這點的。
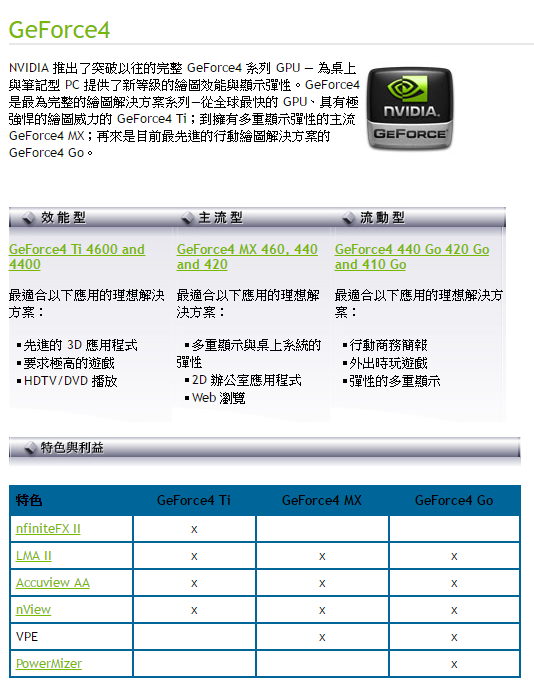
為什麼我會這樣說呢?NVIDIA 官方在宣傳 GeForce4 系列的時候通常都是同時宣傳 Ti 系與 MX 系,而且在規格比較上只有提到 GeForce4 MX 不支援 nFiniteFX II 引擎這件事情,單看上面這張圖大概會這樣覺得;「畢竟是比較低階的版本嘛,沒有最新的 nFiniteFX II 引擎也不奇怪,那總有上一代的 nFiniteFX 引擎吧?而且還多了 VPE 這項不知道是甚麼的功能呢。」
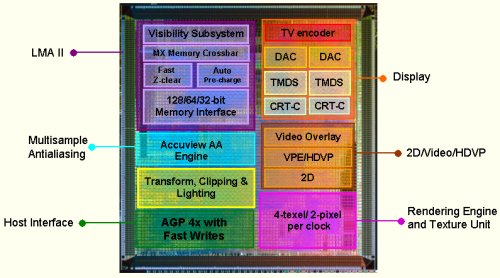
不過實際上 GeForce4 MX 也不包含 nFiniteFX 引擎,應該說其實從架構上就跟 GeForce4 Ti 與 GeForce3 一點也不像了,從上面這張圖可以很明顯看到,DirectX 8.0 的最核心部分-Shader Model 整個不見了,反而看起來比較像是 GeForce2 的架構,是吧?

是時候揭曉答案了,其實 GeForce4 MX 就是拿 GeForce2 核心修改而來的版本,把原本主掌記憶體頻寬這最大瓶頸的記憶體控制器抽掉,換上 GeForce4 Ti 當中使用的 LMA II (其實有稍微降級,比 GeForce3 用的 LMA 還要略差),並把 GeForce4 Ti 新引入的 nView 雙螢幕技術與 GeForce3 開始支援多重取樣反鋸齒加進來就是 GeForce4 MX 了,從開發代號上也可以證實這件事情:GeForce4 MX 使用的是 NV17 核心,數字編號比 GeForce3 的 NV20 還要來得更小,而且 GeForce4 MX 的 DirectX API 支援能力都只到 7.0 版本。

至於系列編成的部分,GeForce4 MX 系列的成員比較多一些,同樣可分為前後兩期,前期使用的是 NV17 核心 (自 2002 年 02 月起),可分為 MX420 (預設時脈 250/166 MHz,只能搭配 SDR 記憶體)、MX440 (預設時脈 275/400 MHz)、MX440 SE (預設時脈 250/332 MHz)、MX460 (預設時脈 300/550 MHz) 四種。

至於後期的發行情形則與 GeForce4 Ti 的情況類似,改採新增了 AGP 8x 支援能力的 NV18 核心,先後以 MX440 為基礎推出了 GeForce4 MX440 with AGP 8x (記憶體時脈從 400 MHz 提高到 500 MHz) 與 GeForce MX4000 (2013 年 12 月,預設時脈為 250/332 MHz,且記憶體頻寬只有一半,代號 NV18B) 兩款。

而在 2004 年 NVIDIA 還曾經另外以 NV18 為基礎加上 BR02 橋接晶片後製作出稱為 NV19 的組合,並以 NVIDIA GeForce PCX4300 的名義發售 (上圖,記憶體時脈高達 666 MHz,但頻道寬度與 GeForce MX4000 一樣只有一半)。
儘管後來看起來 GeForce4 MX 的做法好像很不可思議,但實際上在當時卻沒有造成市場反應不理想,反而因為價格與 GeForce2 MX 相差無幾,卻又因為解決了記憶體頻寬問題使得效能有明顯的提升,合理的價格與充足的性能使得 GeForce4 MX 後來其實很受歡迎,在很短的時間內就成功取代了原本 GeForce2 MX 長年佔據的低價與 OEM 市場。而且 GeForce4 有一點很有趣的現象,那就是只有 GeForce4 MX 才有內建影像處理引擎 (就是剛剛提到的 VPE) 與可變長度編碼解碼器,高階的 GeForce4 Ti 反而沒有支援這些功能,於是如果只是想看影片的話,選用低階的 GeForce4 MX 表現反而會比較好。