

接下來我們終於要再次進入 2006、2007 年這具有傳奇意義且幾乎可說是奠定了未來十幾年個人電腦基礎的年份了,在這一年當中發生最重要的事情就是 Vista 的完工與上市,不論後來人們如何評斷 Windows Vista 的不流暢與「華而不實」,事實上從 2006 以降的所有 Windows 版本實際上其實都是以 Vista 為基礎下去微調出來的產品!要說微軟在 2006 年之後在作業系統技術面就沒有真正重大的架構革新其實也不為過。
Windows Vista 的變革
回顧當年 Windows Vista 帶來的改變其實絕大多數都是內外兼具的,外觀上的變化有非常大部分奠基於內部架構的徹底革新,像是為了創造用起來仍然讓人充滿熟悉感卻骨子裡已全然不同的桌面環境,只好把整個桌面渲染機制與顯示卡記憶體堆疊砍掉重練,又因此為了大幅提高的繪圖性能需求,只好把整個 Shader Model 規劃也砍掉重練,甚至連用了好幾年的可程式化繪圖管線的架構都升級到新的統一渲染器架構了。
Desktop Window Manager (DWM)
相信絕大多數人至今對 Windows Vista 留有最多印象的部分就是被稱之為 Windows Aero 的磨砂玻璃特效介面了吧?實際上這項功能真正的幕後功臣就是 Desktop Window Manager,單從桌面視窗管理員這名字上來說可能不太好理解這是甚麼東西,實際上在早期的 Longhorn 版本當中 DWM 曾經被稱為 Desktop Compositing Engine (桌面合成引擎,DCE),從這名稱應該就不難理解其實 DWM 負責的就是將各視窗的即時繪圖合成為我們所見到的桌面環境的功能。
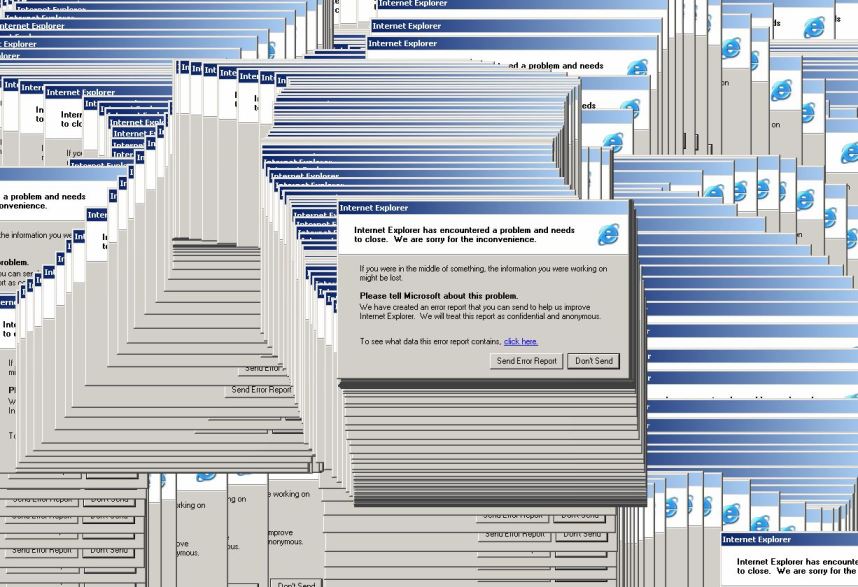
如果你是從 XP 或更早以前開始用電腦的話,應該對上面這張經典畫面不陌生吧?在 Windows 3.1 到 Windows XP 之前基本上 Windows 用來渲染桌面的機制都大同小異,也就是我在好幾篇前曾經介紹過的 GDI 與後來的 GDI+,當時 Windows 桌面是純粹的 2D 圖形組成,也就是直接將畫面進行渲染與輸出,在遇到有重疊視窗的時候才透過每個部分的 Z 軸值大小來判斷是否被遮住,將被遮住的部分挑出來不予渲染的方式來達成視窗重疊的效果的,不過這樣的作法意味著在上方視窗移動的時候,下面全部的視窗也都得跟著被重畫一次,而在渲染速度比視窗移動速度還要慢的時候,電腦會來不及去除正確的重疊部分,最後的結果就是像上圖那樣的殘影。
而且除了殘影問題經常發生之外,過去十年間實際上電腦的性能幾乎是直線上升的,穩定的一年一代,每年有更新、每代有升級讓人們對於未來電腦的前景實際上是比較有信心的,因此也有不少人開始思考,從 1994 年一路用到現在的 GDI 是時候該來點大改版了吧?3D 圖形都發展這麼久了,桌面環境為什麼不能 3D 化呢?有如水晶一般的半透明畫面不是很動人嗎?我們的顯示卡這麼強大了,為什麼在不玩遊戲的時候要讓顯示卡閒著呢?這些想法逐漸浮上了檯面,於是就有了這一系列的變革誕生 (實際上第一個弄出這類介面風格與類似架構設計的是蘋果的 Mac OS X)。
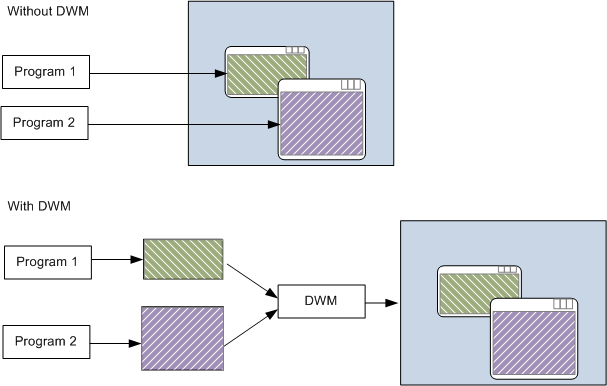
至於 DWM 是怎麼解決這個問題的呢?從上面這張示意圖應該就不難理解了,在進入 DWM 時代之後 Windows 會將每個程式的視窗繪製到專屬的虛擬空間中,再交給 DWM 進行合成處理以產生最後我們所看到的桌面環境,這意味著不論桌面上的東西怎麼移動,都不需要重新渲染視窗的內容,自然也就不可能再產生殘影的問題,而且還讓很多本來不可能實現的特效成為可能 (當然由於要渲染的東西多很多,性能方面的需求也跟著拉高了很多)。
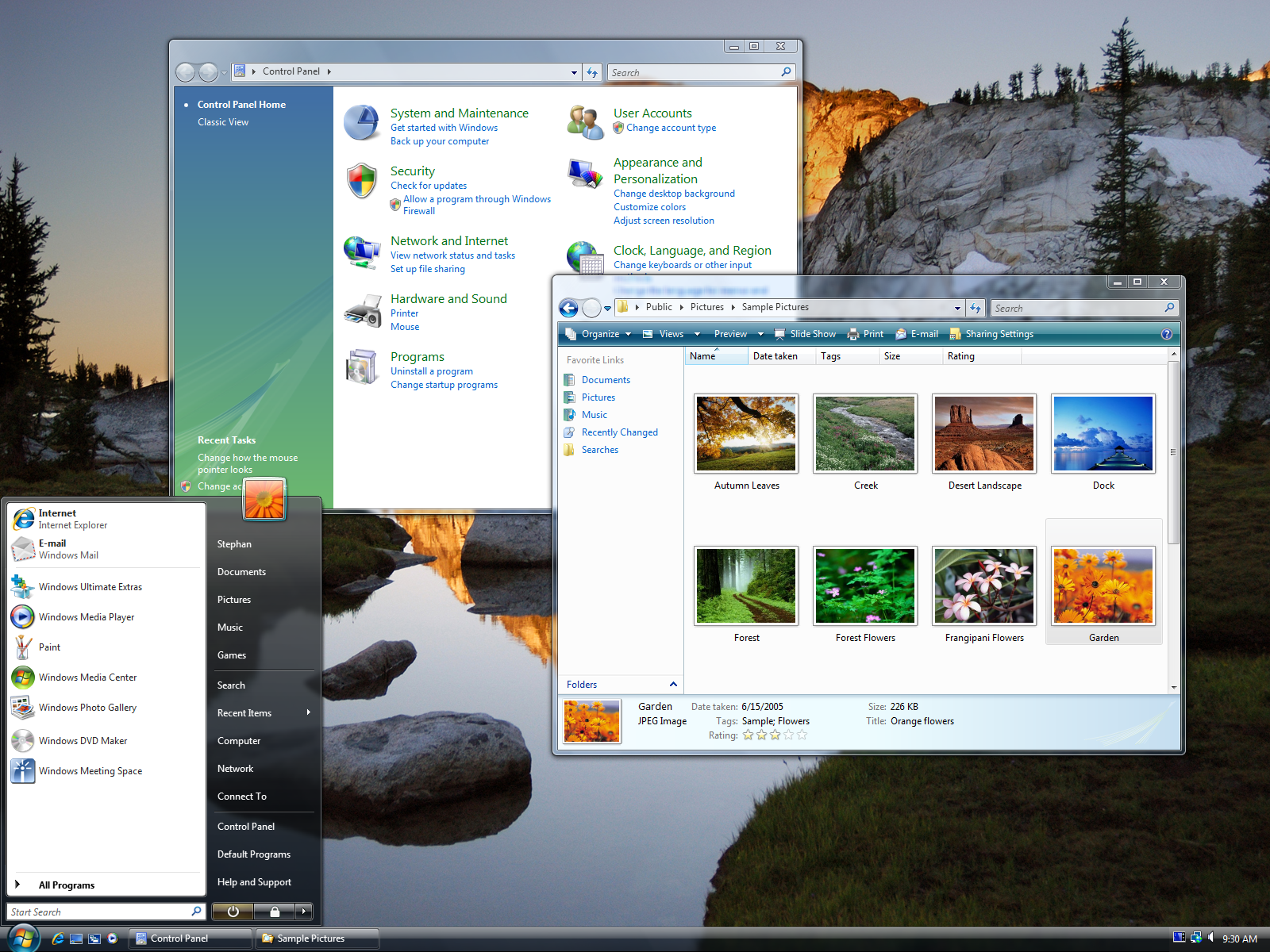
最鮮明的例子應該就是 Aero Glass 處理視窗重疊的做法了,注意上圖當中的兩個視窗,上層視窗的標題列有微微透出下層控制台視窗中的文字,在以往的 GDI 架構當中這是不可能出現的情況,理由很簡單,傳統 GDI 在這種情況下根本不會去渲染下層視窗被蓋住的部分,因此根本也無從得知下層視窗長甚麼樣子,更別說缺乏對 Direct3D API 的支援因此實際上根本也沒辦法即時算出玻璃的高斯模糊特效這件事情了。
上圖當中的 3D Flip 應該是 Vista 當時宣傳上最具代表性的畫面吧?儘管被認為非常雞肋,但實際上這個功能可以說是 DWM 最好的技術展示,同時展現了 DWM 的預渲染畫面即時映射能力與桌面環境 3D 化並將 DirectX 帶入桌面環境中的設計精神。
Windows Display Driver Model (WDDM)
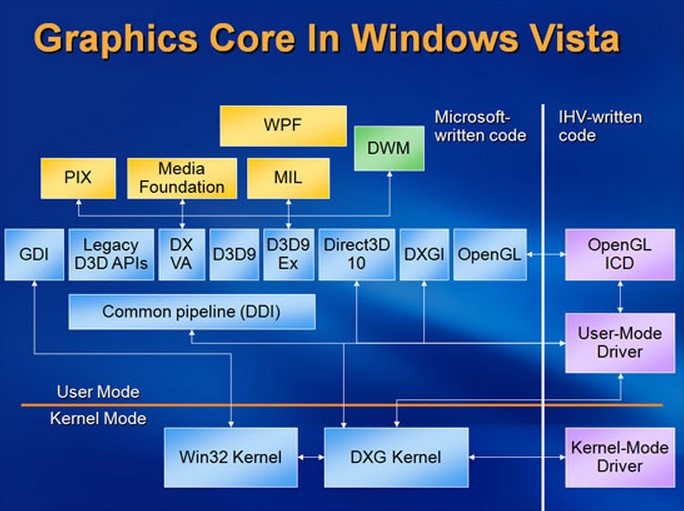
如同 GDI 在 Windows Vista 以前扮演了在 User Mode 執行的應用程式與嵌入 Kernel Mode 的驅動程式之間溝通橋樑的角色 (下圖) 一般,這個角色由 DWM 接手之後自然在驅動程式的架構方面也得迎來一次大翻新才行,Windows 顯示驅動模型 (WDDM) 就是為此而設計的。
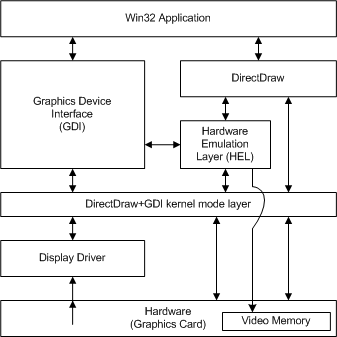
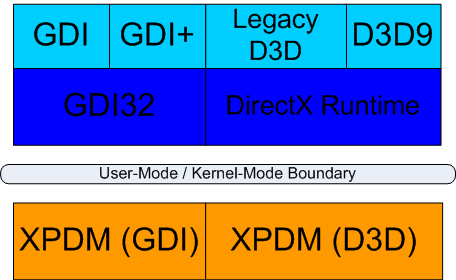
在開始看 WDDM 的設計之前我們得先從 Windows XP 時代或更早以前的 Windows 顯示驅動程式架構開始看起 (微軟將其稱之為 Windows XP Display Driver Model, XPDM),從架構上可以很明顯看出來負責 2D 桌面環境的 GDI 與負責 3D 圖形程式的 Direct3D 實際上是完全被拆分成兩個部分處理的,彼此之間井水不犯河水 (實際上微軟也不是沒有想過把他們硬是融合起來,不過後來發現落差實在太大而始終沒辦法達成),而且全部都在 Kernel Mode 中。
而在進入 Windows Vista 之後,由於桌面環境在升級到 DWM 架構之後實際上也變成 (廣義上的) 3D 應用程式了 (甚至新式程式的圖形介面使用 Windows Presentation Framework, WPF 本來就是 Direct3D 程式),因此全部通通交給 DirectX Runtime 負責處理就行 (但為了繼續支援傳統程式還是得顧慮到傳統 GDI 的部分,作法上是透過 WMF 包裝之後由 DWM 來繼續提供相容性,有點像是把每個 GDI 程式獨立隔開變成數個執行個體來轉換處理,之後與其他 Direct3D 程式一樣把渲染的結果扔給 DWM 做合成,當然這麼做的代價就是在 Vista 上 GDI 是沒有支援硬體加速的,這導致 Vista 在處理傳統 GDI 程式的性能受到了不小的影響,這某種程度上是 Vista 的 WDDM 一開始為人所詬病的主要原因之一,因為在這種狀況下 Vista 的表現反而會比 XP 糟糕,而偏偏在 Vista 誕生的時間點基於 GDI 的程式遠比支援 WPF 的來得多,於是災難就無可避免的發生了,但這點之後在 Windows 7 上這點有被修正,也許之後有機會會提到)。
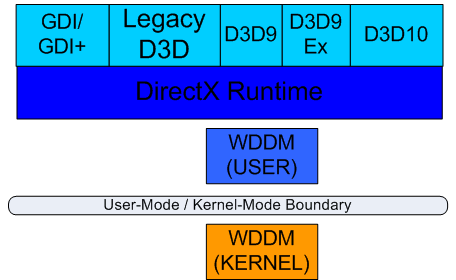
除此之外 WDDM 還有兩項很重要的特性是特別需要提及的,首先是下圖當中的 GPU Scheduler 這項功能,在以往基本上我們最多只會同時開一個 Direct3D 程式 (還記得嗎?當年要搞遊戲雙開幾乎是不可能任務),因此並沒有非常迫切的需要去設計 GPU 專用的排程器來解決多工的問題,但是進入 Vista 時代之後,等於桌面環境本身就至少是一個常駐的 Direct3D 程式了,若是沒有 Scheduler 的幫助那豈不是根本開不了 3D 圖形程式了嗎?微軟當然不會幹這麼白癡的事情,因此 WDDM 引入了 GPU Scheduler 的功能,讓動態分配 GPU 運算資源成為可能。
另一項重要的特性則是在 WDDM 時代以後,不同的處理程序 (Process) 之間可以共享相同的資源 (稱為 Cross Process Resource Sharing),而不必像以前一樣得經過記憶體繞一大圈重新回到 GPU 當中處理才能達到類似效果。
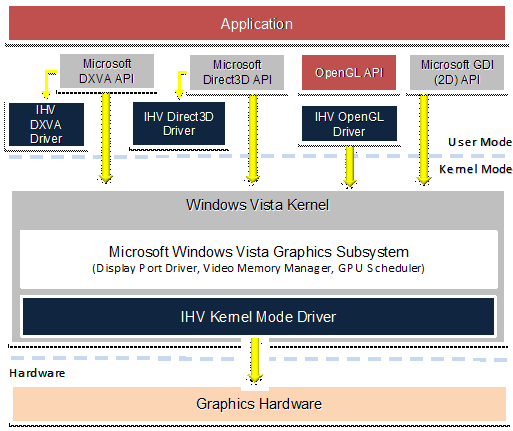
而從剛剛的架構圖也可以注意到 WDDM 有一部分是出現在 User Mode 的,這樣的改變主要是為了穩定性方面的問題,在進入 WDDM 世代之後 Windows 可以在顯示卡出錯的時候透過系統來指示重設顯示驅動程式的方式來讓系統恢復正常運作並提示使用者顯示卡驅動程式發生過問題 (以往是由 GPU 廠商自行設計相關的復原機制,因此有些廠商會設計重設有些廠商則是直接噴錯誤訊息),並且可以避免 Kernel-Mode 當中的驅動程式出問題就將整台電腦拖下水的狀況,除此之外還有讓使用者得以在不重新開機的狀況下載入新版顯示驅動程式的附加價值。
DirectX 10
寫了這麼多之後終於要談到本篇真正的第一個主角-DirectX 10 了,過去幾代 DirectX 大版號發生改變的時候基本上就意味的繪圖管線有了重大的變革,像是 DirectX 7.0 帶來的硬體 T&L、DirectX 8.0 首次引入的可程式化管線與 DirectX 9.0 帶來的高階渲染器語言,而距離上一代推出足足間隔了四年的 DirectX 10 也不例外。

根據微軟官方的說法,DirectX 10 雖然沿用了 DirectX 的名稱,但實際上幾乎是整組砍掉重練的結果了,不過由於這邊談的是電腦圖形所以我們只看 Direct3D 10.0 的部分,而 Direct3D 10.0 當中最重要的變革依舊是出現在 Shader Model 的部分。
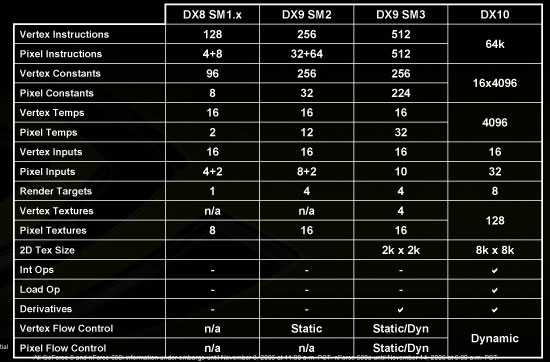
DirectX 10 引入的 Shader Model 4.0 基本上可以視為 Shader Model 3.0 的超集 (但有例外,Shader Model 4.0 不再向下相容 Shader Model 1.0 了,不過這並不是大問題,反而對 ATI 來說比較頭痛的是其大量採用的 FP24 半精度浮點數支援也被取消了,從 DirectX 10.0 開始只支援 FP32),並且延續過去的慣例,繼續減少對 Shader 程式的限制,而且是歷來放寬幅度最大的一次 (指令數從 512 直接狂飆到 65,536,暫存器從 16 ~ 32 直接跳到 4,096 個等),也因為這樣讓 GPU 可以分攤更多 CPU 的工作,從此 CPU 不再經常成為拖慢遊戲性能的瓶頸。
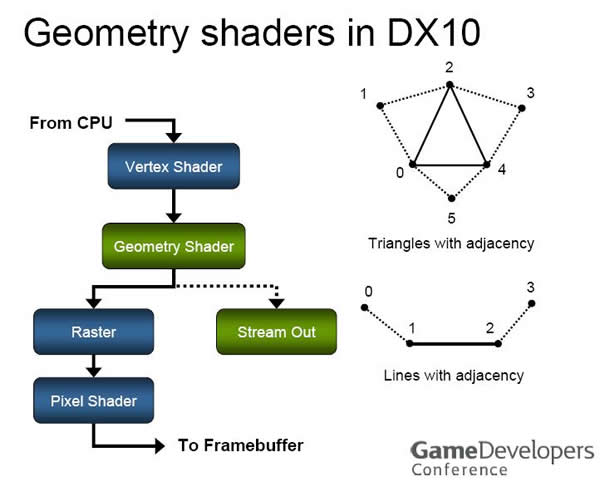
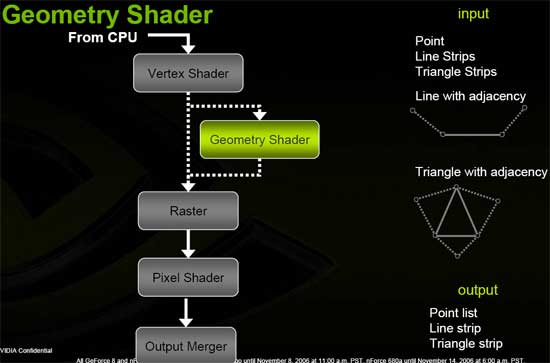
不過這並不是 Shader Model 4.0 最大的改進,實際上 SM 4.0 的核心特色有兩個,首先是除了 Vertex Shader 與 Pixel Shader 之外,我們現在有了第三種 Shader-Geometry Shader (幾何渲染器),顧名思義這種渲染器是用來處理幾何圖形的,位置在原本的 VS 與 PS 之間。
Geometry Shader (幾何渲染器)
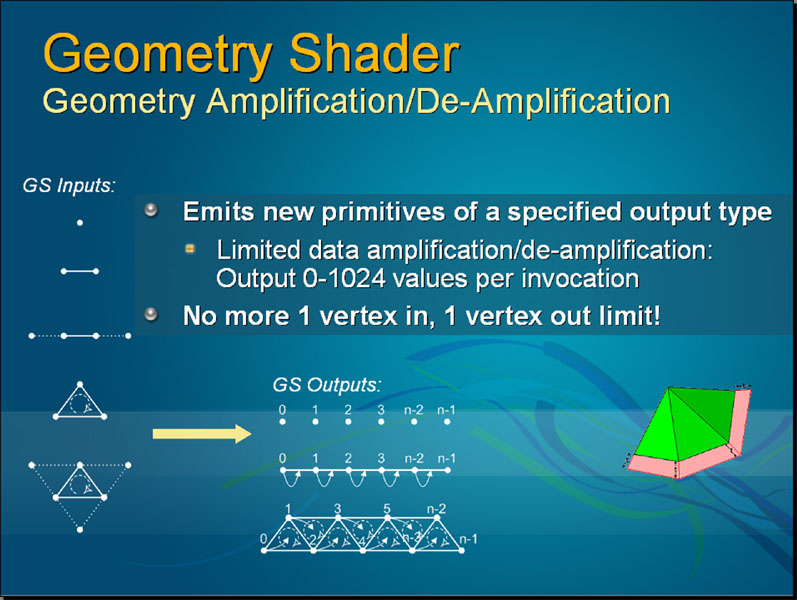
以往的繪圖管線規劃中,Vertex Shader 是以頂點為單位進行處理,之後將產生的頂點資訊用於組成多邊形 (Primitive Assembly),再經過一系列的視角、轉換處理之後才交給 Pixel Shader 進行各像素的運算,而在這中間的過程當中,在多邊形生成這步之後是無法「無中生有」出新的多邊形的 (正常來說管線是不能倒退的),在一般情況下來說確實沒甚麼問題,但是在要處理物件表面即時變換 (舉例來說,巫師施法將主角變成大理石雕像的效果之類的) 時就顯得不敷使用,而 Geometry Shader 的出現解決了這個問題。
Geometry Shader 的運作基本上是將上個步驟-多邊形生成中產生的多邊形拿來使用,透過 Geometry Shader 的幫助可以用原先已經固定下來的多邊形產生新的或是更多的多邊形來改變物件表面的形狀與樣貌 (讓程式有進行「第二次多邊形生成」的機會)。

雖然乍看之下 Geometry Shader 似乎沒有甚麼太重要的角色,但實際上 GS 的出現讓電腦遊戲的畫面真實度又再次提升了一個檔次 (特別是在處理水面、金屬表面反射與變形的時候),以上圖為例,海面的波濤洶湧在以往沒有 Geometry Shader 的時候是無法想像的 (上為 DirectX 9.0,下為 DirectX 10,同樣都是執行微軟的模擬飛行 X)。
Table of Contents
統一渲染器架構 (Unified Shader Architecture)
而另一項重要改變則是大家耳熟能詳的 Unified Shader Architecture (統一渲染器架構),顧名思義就是從 DirectX 10 開始,GPU 內的電路設計將不再有 Pixel Shader、Geometry Shader 與 Vertex Shader 之分,取而代之的則是「一堆完全一樣的 Shader 單元」,這同時也是 DirectX 10 世代當中顯示卡架構變化最大的部分。
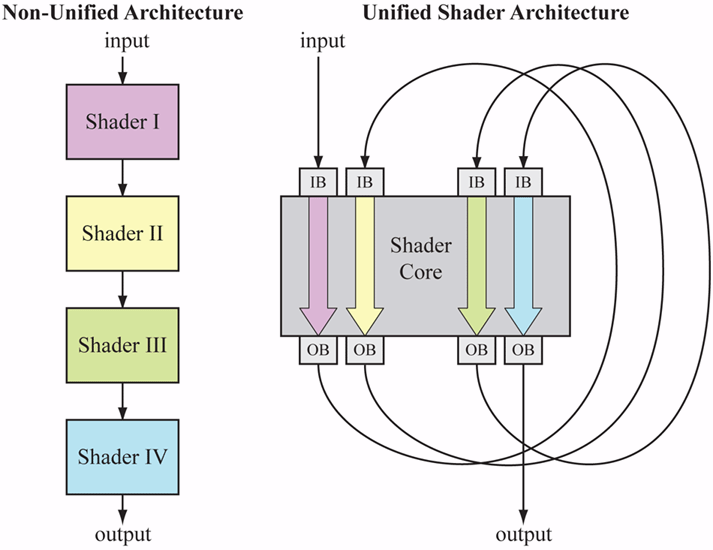
至於為什麼要這樣做呢?可以從生產與應用兩個角度來看,首先是應用的部分,下圖是 GPU 在處理遊戲的過程當中,VS 與 PS 使用率的即時記錄。
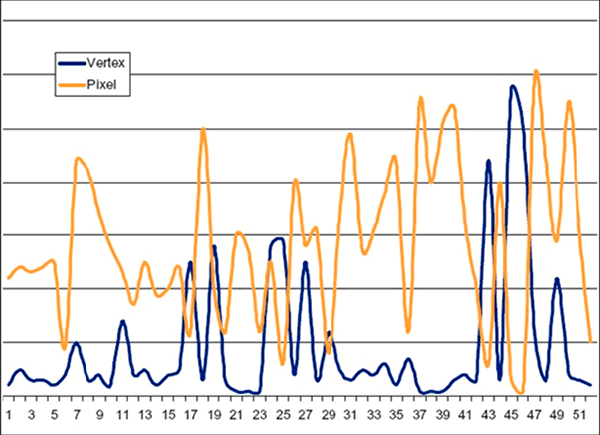
從上圖當中可以發現 VS 與 PS 的使用率變化波動是非常劇烈的,有些時候 VS 很忙但 PS 根本沒事可做,也有些時候反過來是 VS 在納涼,這樣不是很浪費嗎?我們花錢買了 GPU 電路也花了電費可不是要讓電腦有某些部分閒在那邊沒事的吧,但因為 VS 沒辦法做 PS 的工作、PS 也沒辦法做 VS 的工作,於是這樣的資源浪費便變得無法避免。

要解決這個問題的話,最直覺的方式就是打破 VS 與 PS 的分別,讓 GPU 得以自行根據安排隨機調用 Shader 資源,讓每個 Shader 都有事做,這就是人們開始思考採用統一渲染器架構的原因之一。

而採用統一著色器架構的另一個重要因素則是出現在生產方面,當著色器被統一之後,意味著 GPU 電路當中會有大量的「重複單元」(每個渲染器長得都一樣,而且數量很多),這對生產良率上的提升與開發過程中問題的發現與解決其實是大有幫助的,我們知道晶圓廠基本上升級製程之後第一個試產的就是記憶體晶片,其實原因就是記憶體晶片的電路重複度非常的高,而且相對而言非常單純因此容易發現與解決問題的關係。
同時這也讓 GPU 廠商可以更容易透過使用屏蔽統一著色器數量的方式來製作針對高階、中階與入門市場等不同等級的產品,並且可以更加動態的將受制於良率而產生輕微瑕疵無法作為高階型號出售的晶片運用於生產中低階的產品 (其實就是高度模組化的概念,後來 CPU 也幾乎都走這個方向)。
GPGPU (通用用途圖形處理單元)
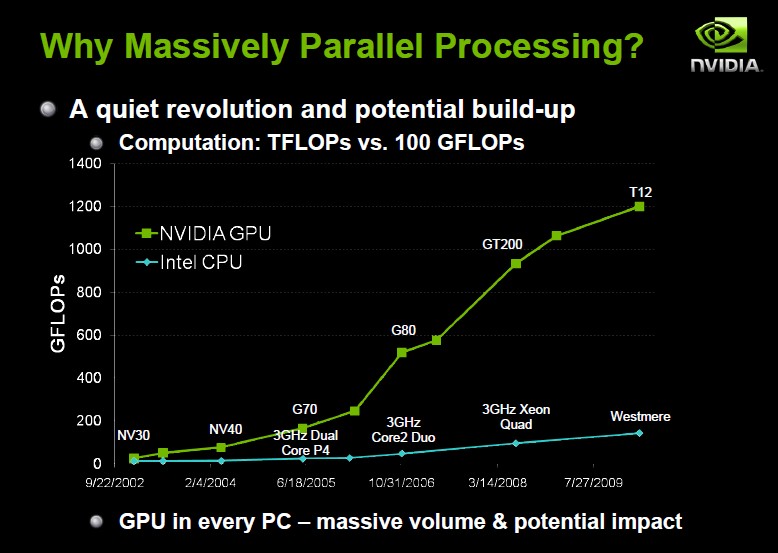
GPU 在發展到 Shader Model 4.0 的統一著色器架構之後有著架構易於延伸的特性,加上大量相同的著色器運算單元非常適合處理平行度高的運算,加上 GPU 的性能在過去幾年始終維持著相當高的成長率,而 CPU 由於本身複雜度很高,在架構上反而沒有太大的長進 (下圖中的綠線是 GPU 的浮點運算能力成長曲線,藍線則是 CPU 的),因此人們開始思考是不是能夠讓 GPU 開始分攤一些圖形運算處理以外的工作 (比較激進的想法甚至認為 GPU 在未來有朝一日可能可以取代現有的 CPU,不過現階段看起來其實不太可能,但超級電腦市場的採購金額基本上已經翻轉為 GPU 大於 CPU 了,實際負責運算的主力也是 GPU 為主,CPU 則退居為控制與輔助的角色),在這樣的思維底下 General Purpose Graphics Processing Unit (GPGPU) 的概念就浮出水面了。
最早提出 GPGPU 概念的是 ATI,當年 ATI 曾經運用 Radeon R500 架構來投入 Folding@Home 計畫協助運用 GPU 來模擬蛋白質的合成,透過大規模的分散式運算技術來讓全世界無數的一般電腦得以共同合作創造出類似超級電腦的運算能力以協助科學研究的進行,當時使用的 ATI Radeon X1900 GPU 可以提供將近當時同期 CPU 70 倍的運算性能 (因為這類科學研究的運算平行化程度很高,特別適合用 GPU 處理)。
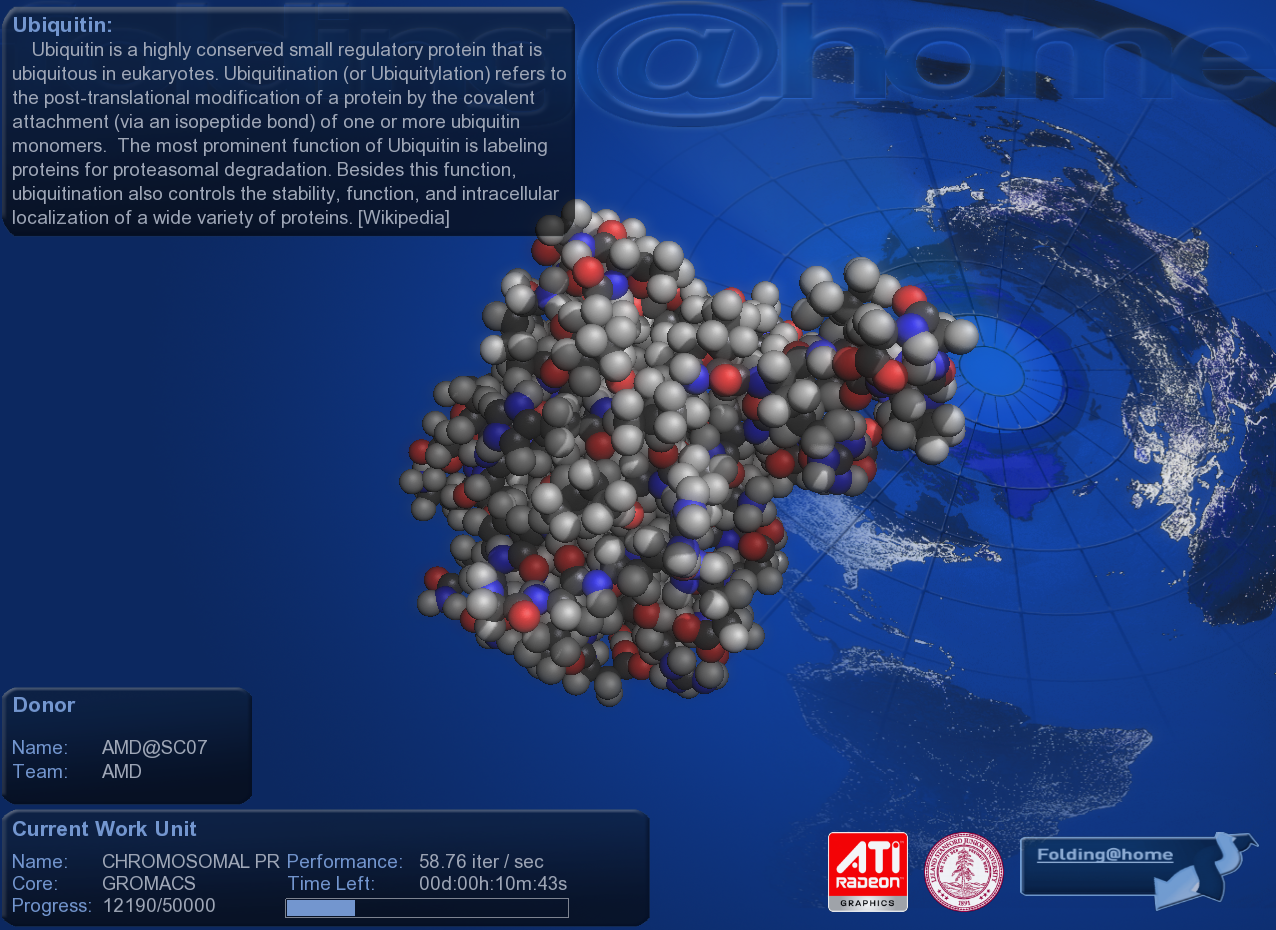

不過 ATI 當時使用的方式是運用原有的 DirectX API 來呼叫 GPU 處理相關的工作,並沒有真正自己發展一套用於 GPU 的通用計算介面,因此實際上還無法完整發揮性能,真正第一個將通用計算技術應用到自家 GPU 的則是 NVIDIA 提出的 CUDA (Compute Unified Device Architecture,統一計算架構) 運算標準。
NVIDIA CUDA

由於 NVIDIA 本身在宣傳產品的時候經常使用 CUDA 這個字眼,因此因該絕大多數人對 CUDA 這四個字並不陌生,但由於 NVIDIA 把運算技術取名叫 CUDA 的同時,也把 NVIDIA 自家的通用運算程式語言稱為 CUDA C Code,後來更把運算核心也改名叫 CUDA Core,又把 GPU 的架構稱為 CUDA Architecture,但在宣傳物與文件上卻常常忘記後面的後綴而經常造成嚴重的混淆,在開始之前我想先強調接下來我所談的是以「整組 CUDA」為主的觀點 (提及個別單位的時候我會加後綴)。
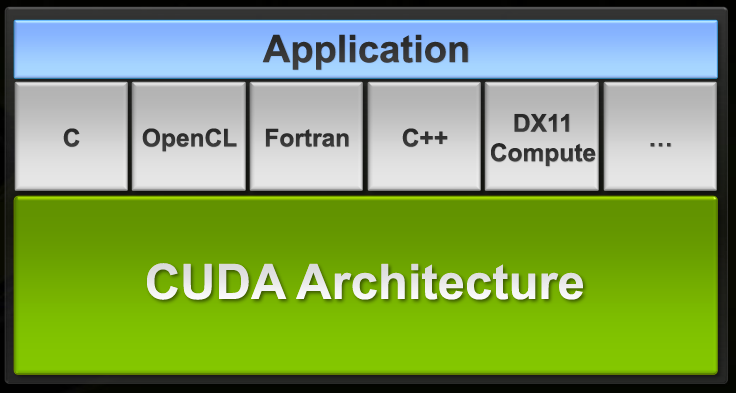
整體來說「CUDA 運算技術」這個概念實際上是由上層的開發者撰寫的 CUDA 程式、程式語言與 API (包含 CUDA C Code 與等一下會介紹的 OpenCL、DirectCompute)、基於 CUDA Architecture 設計的 NVIDIA GPU 三層結構所組成,由於最初的 CUDA 1.0 主要是使用 NVIDIA 自家發展的 C 語言延伸版本實作,因此才會有「CUDA C Code」這個名詞的出現。

為了能在不同的 NVIDIA GPU 上運作,CUDA 的執行架構實際上分為通用 (Generic) 與分化 (Specialized) 兩層,開發者撰寫好程式之後使用 NVIDIA C Compiler (NVCC) 產生供 CPU 執行的可執行檔與被稱之為 PTX (Parallel Thread Execution) 的語言檔案 (採用一種只有 NVIDIA GPU 能夠支援的組合語言),之後再由 PTX to Target Compiler 將 PTX 語言檔案編譯成各款 NVIDIA GPU 能夠執行的檔案 (目的是為了充分發揮不同 GPU 所具備的特性與功能)。
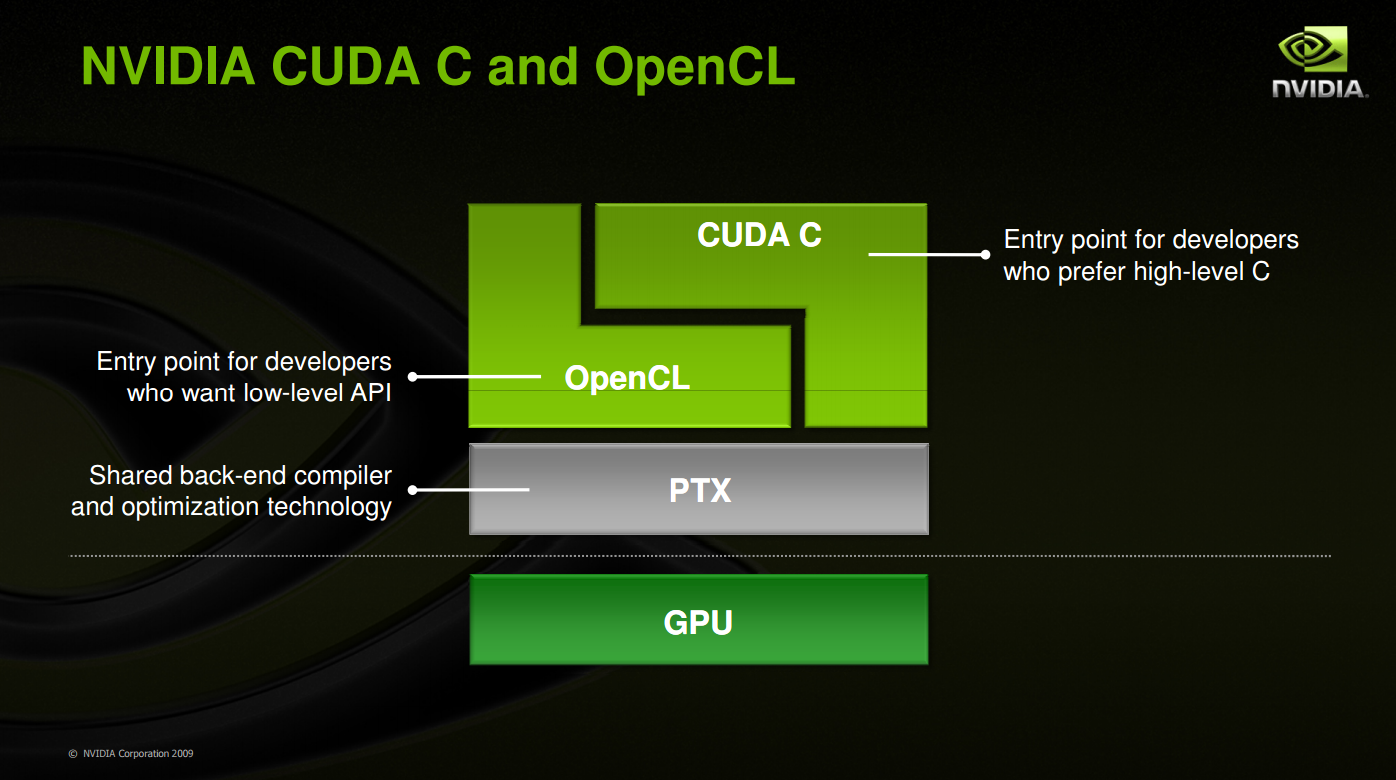
同時 PTX 這層共通介面的設計 (概念上跟 CPU 的指令集架構很像) 也是 CUDA 架構可以同時支援 CUDA C、DirectCompute、OpenCL 等 API 的主要功臣,當 NVIDIA 要加入對新種類 API 的支援的時候,實際上就是在 PTX 這層當中加入對該種 API 的優化與轉換機能。
ATI Stream Technology

而 AMD 陣營當然也有與 CUDA 運算技術相當的技術 (不過可能知道的人比較少,AMD 一直都沒有很勤於宣傳這項技術),被稱之為 ATI Stream Technology,雖然 AMD 早在 2006 年就首創用 GPU 來跑 Folding@Home,但卻一直沒有很認真發展這項技術,因此直到 2009 年之前大多數人都認為 CUDA 沒有任何競爭對手。
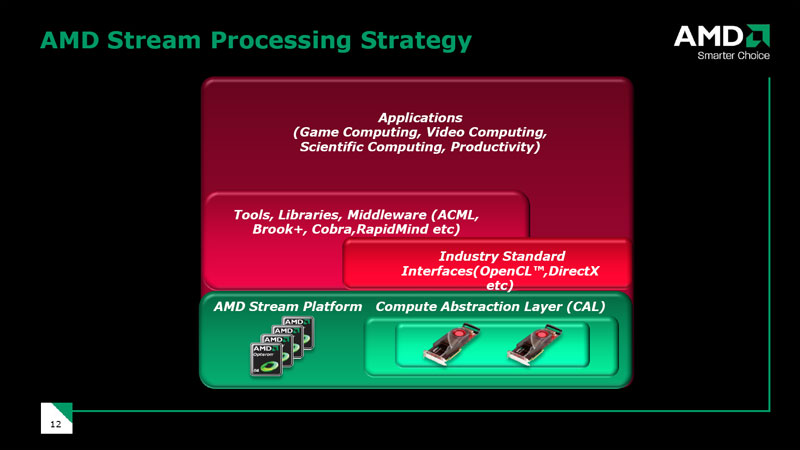
ATI Stream Technology 的架構設計其實跟早期的 CUDA 很類似,同樣有著自家的程式語言與 API (稱之為 Brook,不過跟 NVIDIA 的 CUDA C Code 不同,Brook 是組合語言,很難寫,後來的 Brook+ 才改成高階語言) 與負責在程式與 GPU 之間中介的轉換層 (ATI 將其稱之為 Compute Abstraction Layer,計算抽象層) 等,不過由於知道的人太少,甚至後來 AMD 也不怎麼用 Stream Technology 這品牌,所以就不深入介紹了。
通用計算 API 的統一
不過在 CUDA 與 Stream 技術都出現之後,人們很快發現有個很嚴重的問題重演了,那就是各廠商之間的 API 竟又回到各自為政的情況 (甚至曾經出現一家用組合語言,另一家用高階語言的慘況),從過去經驗我們幾乎可以很直接的論定 API 不整合這技術基本上在未來只有死路一條,因此勢必得要有人出面推出大家共同遵守的 API 規範才行。
OpenCL
第一個跳出來主導開放 GPGPU API 的是由蘋果公司主導的 OpenCL (Open Computing Language,開放計算語言),在 2007 年開始發展,並且在 2008 年 06 月 16 日由 Apple、NVIDIA、Intel、QUALCOMM、AMD 等廠商共同組成了一個新的非營利組織-Khronos Group 以將 OpenCL 發展為一款開放的 API。

後來 OpenCL 1.0 在 2008 年被正式提交到 Khronos Group 並在當年年底通過該組織的審查正式成為了各廠商共同支援的標準,之後 2009 年 Mac OS X Snow Leopard 成為了第一個原生完整支援 OpenCL API 的作業系統,隨後 NVIDIA 與 AMD 也陸續透過驅動程式來在 Windows 下提供對 OpenCL 的支援 (嗯,沒錯,微軟沒有參加,原因等下就會提到了)。
OpenCL 與 CUDA C Code 之間最大的不同點有二,首先是 CUDA C Code 基本上比較著眼於 GPU 運算的部分,在 CPU 與 GPU 同步運用的異質運算 (Heterogeneous Computing) 部分著墨甚少,但 OpenGL 則是從發展之初就很強調異質運算的部分,因此在處理異質運算的部分 OpenCL 的技術會比較成熟,另一個主要不同則是 OpenCL 不論在 NVIDIA、AMD、Intel 內建顯示甚至行動裝置上都能夠使用,是主流通用運算 API 當中唯一可以跨這麼多平台與設備的 API。
至於 AMD 的部分呢,後來 AMD 在 OpenCL 出現之後幾乎就放棄自家的 Brook 了,從 2009 年後的 AMD Stream Technology (後來改名為 AMD-APP) 都以 OpenCL 為主。
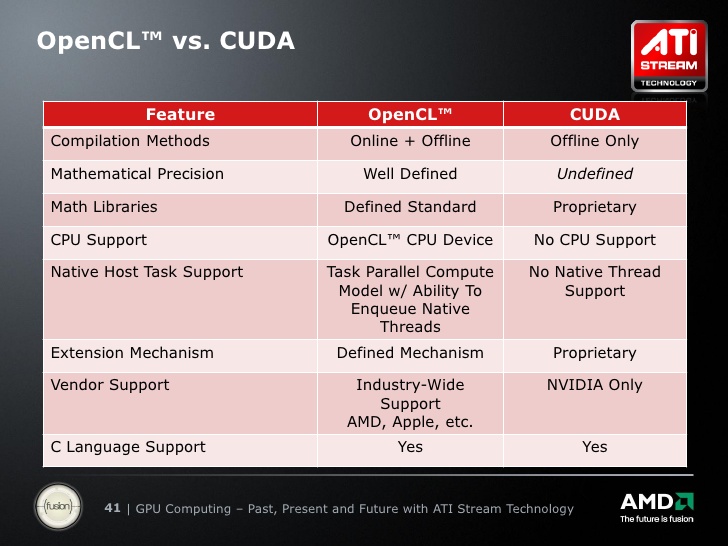
至於 CUDA C Code 為什麼沒有隨著 OpenCL 的出現而逐漸凋零,反而演變成 CUDA C Code 這類私有 API 持續與 OpenCL 等通用 API 並存的局面,大概是因為 AMD 在轉用 OpenCL 之前一直沒端出能與 NVIDIA 抗衡的產品,使得有通用運算需求的廠商或人們幾乎都以 NVIDIA 產品為主,累積到 2010 年其實有不少較早導入通用運算技術的廠商或開發者已經用 CUDA C Code 寫好程式了,又加上 NVIDIA 的 GPU 處理 OpenCL 的速度較慢,不及使用 CUDA C Code 的狀況,因此使用 CUDA C Code 的比例一直以來都不低,所以並沒有在 OpenCL 出現之後迅速滅絕,OpenCL 的普及速度也沒有想像中快。
DirectCompute
基本上從參與的廠商名單同時包含了 NVIDIA 與 AMD 兩大廠,甚至還有 Intel 也參了一腳來看就注定了 OpenCL 在未來將會成為通用計算界的主流,在這樣的狀況底下,已經透過 DirectX 與 Direct3D 繪圖 API 主宰 GPU 與遊戲界無數年的微軟當然很不是滋味。
因此微軟成為主要廠商當中唯一缺席 Khronos Group 的廠商,並且自己發展了一套稱之為 DirectCompute 的通用運算 API 與之抗衡 (在 DirectX 11.0 當中首次出現),或許是為了掩飾自家比較晚跟上通用運算熱潮吧?DirectCompute 的第一個版本就直接跳到 5.0 版了 (又或許是對應到 Shader Model 5.0 的意思,因為微軟為此還特別創設了一個稱為 Compute Shader 的名詞),除此之外也將部分特性下放回 DirectX 10 作為 DirectCompute 4.0 (不過由於是用 DirectX 10 的原有功能下去拼湊與模擬,因此在很多部分並不能完整支援)。

這個 API 的後續發展其實蠻有趣的,AMD 與 NVIDIA 或許都基於不敢得罪微軟的立場,或是受到 WHQL 驗證的強制要求,因此在各自推出支援 DirectX 11.0 的 GPU 之後都提供了對 DirectCompute 的支援,並且在許多簡報當中給 DirectCompute 大肆吹捧了一番 (NVIDIA 甚至還說過 DirectCompute 會引領個人電腦通用運算的革命之類的話),不過實際上市占率最高的仍然是 CUDA,而次之的則是 OpenCL,至於 DirectCompute?還看不到車尾燈呢,很有可能是所有通用計算 API 當中支援裝置數最多但使用率最低的一款。
通用計算的現況與未來
從 2006 年開始有 GPGPU 的構想,到 2007 年開始真正有規範出台,2008 年透過新型號的 GPU 正式飛入尋常百姓家,2009 年兩大開放 API 的出現到現在,GPGPU 的發展已經有了將近十年的歷史,在許多影像處理軟體加入對 CUDA 的支援,有些遊戲開始用到 CUDA 與 OpenCL,開始有 TOP500 排行前幾名的超級電腦使用 Intel x86 + NVIDIA CUDA 的異質運算架構,加上 Intel 也開始急著發展 Xeon Phi 之後,通用計算確實成功成為一項重要的技術了沒錯,但也有很多與預期不同的地方。

2016 年的今天,DirectCompute 與 OpenCL 並沒有一如預期的將半私有的 CUDA API 取代 (實際上時至今日你仍然可以看到許多影音編輯、轉檔軟體有著只在使用 NVIDIA GPU 時才會出現的 CUDA 加速選項),DirectCompute 也沒有如同當年 DirectX 逐步打敗 OpenGL 一般的成為主流,反而是 NVIDIA 在通用計算領域不斷坐大,也始終不熱衷於推廣 OpenCL (OpenCL 早在去年就已經發展到 2.1 版了,今年的 GTX 1080 仍然只支援到 2011 年推出的 1.2 版,從 2011 年開始就未有提升),CUDA API 目前似乎也沒有衰敗的跡象,甚至 AMD 在去年還搞了一個 Boltzmann Initiative (其中的 Heterogeneous-compute Interface for Portability,可移植異質運算介面,可以將 CUDA C Code 快速轉換為可以編譯後在 AMD 硬體上執行的 HIP 程式碼),看起來未來很長一段時間會是 CUDA API 與 OpenCL 繼續共同主宰這個市場,至於現任爐主 DirectCompute 是否有望翻身,還得寄望於明年可能推出的 Shader Model 6.0 而定。


比較諷刺的是 OpenCL 在過去幾年內最多的運用並不是用於學術或是遊戲方面的異質運算,反而是在 2011 到 2013 年間使用 GPU 進行 Bitcoin 或 Litecoin 挖礦上,由於先天設計與軟體完善度上的差異導致在 NVIDIA GPU 上使用 CUDA 挖礦的效果與速度並不理想,反而引發 OpenCL 性能較強的 AMD GPU 熱賣,連帶拉高了 OpenCL 的使用率與挽救了當時 AMD GPU 的市占率,不過我還是想說,Bitcoin 這類靠電腦大量運算無意義資料來「產製」貨幣的方式,造就了大量的能量浪費與許多成為電子垃圾的 ASIC 晶片甚至 GPU,這是不是好現象,我個人是存疑的。