

介紹完第一代 Tesla 架構 (G9x) 與後續的小幅修改版 (G9x) 之後,接下來我們要看的是第二代的 Tesla 架構 (GT2xx),雖然仍然是以 Tesla 架構為基礎,但實際上在架構安排與系列編成方面都與第一代的 Tesla 有明顯的不同,事實上在 NVIDIA 官方的分類當中是把 G8x 與 G9x 歸類為「第一代統一架構」,至於 GT2xx 則是自成一類稱之為「第二代統一架構」。
第 2 代 Tesla 架構:GT200 系列核心
- 推出日期:2008 年 06 月
- 所屬系列編成:GeForce 200 系列、GeForce 300 系列、GeForce 400 系列、GeForce 8 系列
- API 支援:DirectX 10.0、OpenGL 3.3
- Shader Model 支援:SM 4.0
好的,在經過讓人眼花撩亂的 G9x 大亂鬥時代之後,我們終於要進入 Tesla 架構最後的主題了-第二代 Tesla 架構,這代架構被改名的次數「比較少」,絕大多數情況以 GeForce 200 系列為主,而 GeForce 300 系列本來就是 200 系列改名給 OEM 廠商的版本因此不算複雜,而後來 GeForce 400 系列的入門卡也有一些繼續使用 Tesla 架購的產品 (這種情況 NVIDIA 接下來幾乎每代都有)。
在第一代 Tesla 架構奠定了未來 NVIDIA GPU 的基礎、第 1.5 代 Tesla 架構讓成本下降使得 NVIDIA 獲利成長之後,第二代的 Tesla 架構其實才是 NVIDIA 真正希望呈現的 Tesla 樣貌。
相同架構之下,塞進更多的運算單元
如果你覺得 G80、G92 已經很巨大的話,GT200 會讓你認為根本是另一個世界的產物。還記得我們剛剛談到 G92 是由 7 億個電晶體所組成嗎?GT200 直接翻了一倍,是的,14 億,若把它跟當時同期的 Intel 雙核心處理器排在一起,將是下圖這般德行。

直接翻倍成長這可不是甚麼小數目,在相同的架構基礎下要搞到電晶體成長一倍,這意味著 NVIDIA 其實一定修改了不少地方,讓我們回到第一代 Tesla 架構來思考,Tesla 架構最關鍵的部分是甚麼?顯然是 TPC 吧。
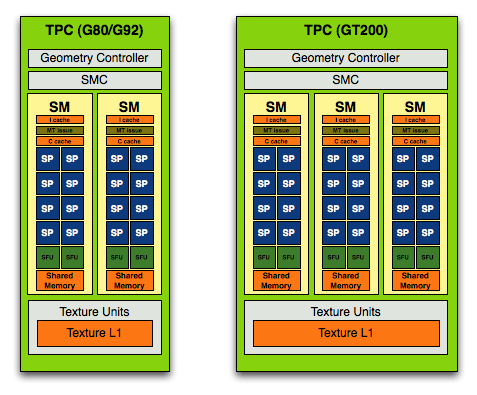
我想用看圖說故事的方式應該就能很容易理解 NVIDIA 在第二代 Tesla 架構當中改了甚麼,本來一組 TPC 當中應該只有 2 組 SM,包含了 16 個 SP 與 4 個 SFU,而在 GT200 當中,基本的架構設計不變,但 NVIDIA 把 SM 的數量從二提高到三,因此每組 TPC 當中現在有 24 個 SP 與 6 個 SFU。
「大、寬、多」是第二代 Tesla 架構的最大特色
不過第二代 Tesla 架構帶來的新特性遠遠不僅只是密度提高的 TPC,基本上與 GeForce 6 系列到 7 系列朝著加寬加廣的方向設計類似,在 GT200 當中你可以發現除了每組 TPC 當中所包含的 SM、SP、SFU 有了大幅度成長之外,甚至連 TPC 本身的數量都從 8 組增加到 10 組了。
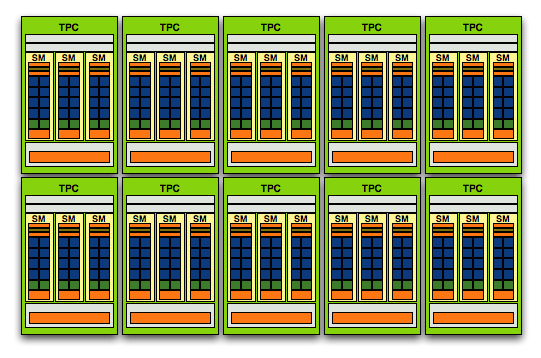
這意味著決定 NVIDIA GPU 性能的最主要因素-SP 的數量將從原先的 128 個一口氣增加到 240 個,幾乎成長了快要一倍,而且除了上面有畫出來的部分之外,實際上在第二代 Tesla 架構當中還首次加入了對雙精度浮點數 (FP64) 的處理能力,每組 SM 都能在每個周期內處理一組雙精度浮點數運算,因此 GT200 每個時脈周期內至多可以處理高達 30 個雙精度浮點數運算。
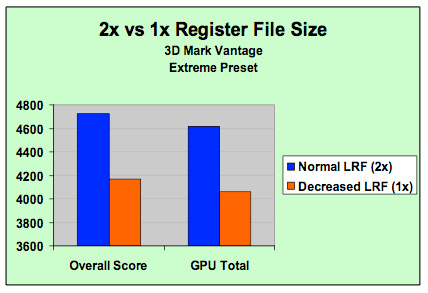
除此之外,儘管我們在 G80 架構當中就知道 Scheduler 在發現 SP 所執行的指令卡住或是陷入等待其他指令的僵局時會要求 SP 將指令丟到暫存器內並執行新的工作,但實務上由於我們使用的 Shader 程式越來越複雜,導致暫存器可能放不下執行中工作的機率提高,導致這項設計所帶來的性能提升無法發揮,因此在 GT200 當中 NVIDIA 將每個 SP 所能使用的暫存器區域大小直接提高了一倍。
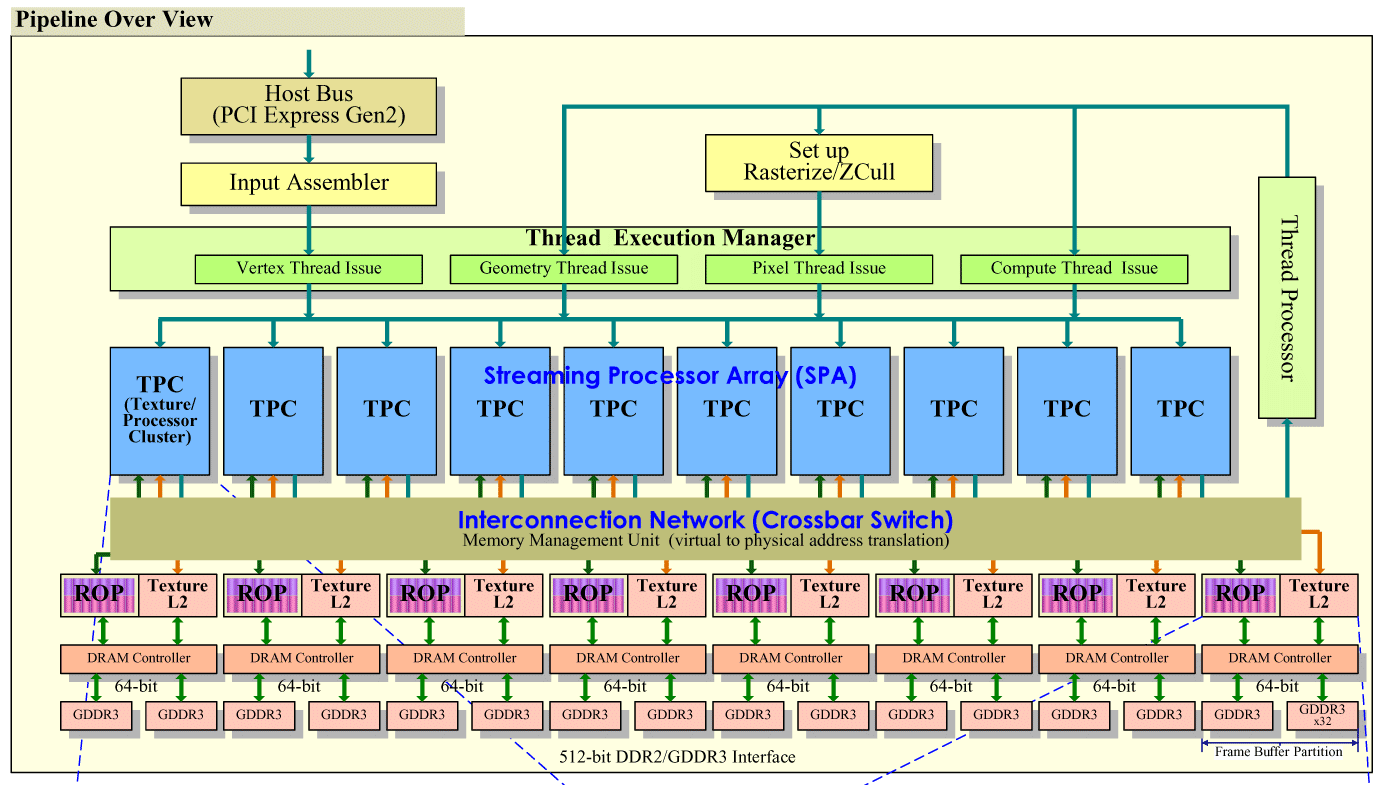
從上面這張較完整的架構圖上可以看到 GT200 的架構體系真的非常寬,特別是在記憶體控制器的部分,以往在 G80 的時候我們覺得 6 組 384-bit 應該就算很多了,但在 GT200 當中,又再次進一步加到八組,可以提供高達 512-bit 的驚人記憶體頻寬。
PhysX 物理運算引擎


除了電路配置上的改變之外第二代 Tesla 架構最主要的新特性應該就是 PhysX 物理運算引擎了,NVIDIA 曾經砸了不少重本來宣傳這項技術,不過這項技術其實本來不是 NVIDIA 的發明,而是來自於一家成立於 2002 年,名為 AGEIA Technologies 的公司,這間公司最主要發展的產品就是被稱為 PhysX 的物理處理器 (PPU,可以製成 PhysX 物理運算卡),顧名思義是專精於物理運算的處理器,如同過去我們所知道的,越「通才」的處理器往往電路複雜,效率提升不易;而「專精」於單一用途的處理器在電路上則會相對比較簡單,處理特定操作的效率也會更強大,在此前物理運算通常是由 CPU 負責的 (在進入統一渲染器架構時代前 GPU 沒有心力也沒有能力處理物理運算)。

AGEIA 這間公司本來生產的物理加速卡雖然在業界上曾經引來很多的注目,但實際上幾乎沒有一般使用者會去額外購買一張只能做物理運算的介面卡來處理遊戲中的物理操作,因此始終在市場上並沒有獲得太大的成功 (如果我手上的資料沒錯的話,似乎只有 ASUS 跟 BFG 有生產過),而在 2008 年 NVIDIA 收購了 AGEIA 之後,PhysX 技術才開始走入一般用戶的世界裡。

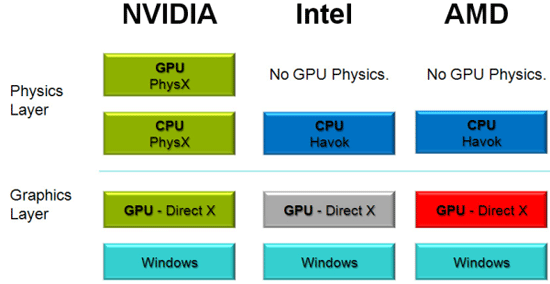
不過 PhysX 技術其實一直以來都存在著很多關於這項技術到底是否真的實用的爭論,特別是在成為 NVIDIA 的獨佔 API 之後只有 NVIDIA 自家的 GPU 能夠支援 (其實 NVIDIA 會去收購 AEGIA 的遠因很可能是 Intel 搶在 2007 年收購了另一家開發物理引擎的廠商 Havok),這意味著在通用度上就有很大的問題,而實際上遊戲也未必真的會去使用 PhysX 的技術規範來設計物理效果,不過 NVIDIA 的強項一直以來都在於吸引大量遊戲廠商提供支援 (對,就是 The way it’s meant to be played 綁標大作戰),又加上 Intel 收購 Havok 之後並沒有重視發展 Havok (畢竟 Intel 的本業是 CPU,太多工作被 GPU 搶去對 Intel 來說是警訊),甚至是陷入停滯,所以最後 PhysX 的採用率其實還是一直都不算低 (精確的說其實是通常都穩坐第一)。

隨著 Havok 在 2015 年又被微軟收購,或許我們很有機會在未來見到 Havok 成為 DirectX 的一部分,作為標準規範的物理引擎提供,若真如此的話 PhysX 的重要性應該會越來越低 (實際上近幾年 NVIDIA 也很少提起 PhysX 了),照常理來看最後應該會由微軟、NVIDIA、AMD、Intel 四方全數應該都能接受的 Havok 拿下最後的勝利 (實際上支援 Havok 的軟體本來就一直都比 PhysX 多,雖然 AMD 在 Havok 被 Intel 吃下來之後跑去擁抱 Bullet API 了),不過目前物理引擎其實討論熱度並不算高,未來會如何發展很難說。
不完整的 DirectX 10.1 支援
DirectX 10.1 是微軟在 2008、2009 年之間針對 DirectX 10.0 釋出的延伸版本,隨著 Windows Vista Service Pack 1 推出,由於架構的部分才剛剛經歷過一次大改版,因此 DirectX 10.1 在架構方面並沒有著墨太多,但也引入了一些新功能,像是小幅升級的 Shader Model 4.1、性能提升、全域光源支援之類的,並且需要新的 GPU 設計才能支援。

不過 NVIDIA 認為要讓 Tesla 架構完整支援 DirectX 10.1 要花額外的時間與成本,不如直接衝下一代的 DirectX 11,因此 NVIDIA 最後並沒有在前期的第二代 Tesla 架構核心當中納入對 DirectX 10.1 的支援能力,僅是透過驅動程式的方式引入一些 DirectX 10.1 新特性 (也就是透過軟體模擬實作的意思),至於 AMD 則沒有這個問題,因此 AMD 如期推出了可以支援 DirectX 10.1 的 GPU 硬體。

接下來的故事就如同以前我們談過 NVIDIA 與 Futuremark 之間的大戰一般了,NVIDIA 一樣都是一間很懂得利用媒體工具的公司,因此接下來就演變成 NVIDIA 大喊 DirectX 10.1 無用論、遊戲開發者對大部分新功能根本沒興趣、我們用軟體支援就算完整支援 DirectX 10.1 了之類的,而 AMD 則拼命誇大 DirectX 10.1 能帶來多大的畫質與性能提升的劇情了,後來 NVIDIA 還抓著 AMD 在給開發者的投影片當中也自己將 DirectX 10.1 稱為「DirectX 10 的增補更新」的小辮子不放想用來引證自己的 DirectX 10.1 無用論 (感覺還真像小孩子吵架)。

不過確實 DirectX 10.1 並不是一個重要的改版沒錯啦,真正的大改版 DirectX 11 距離 DirectX 10.1 的發布其實差距也不過短短幾個月的時間,因此實際上也沒甚麼廠商推出基於 DirectX 10.1 的遊戲,通常就直接跳到 DirectX 11 了,所以這次其實是 NVIDIA 的算盤打對了。
GT200 大核心
簡單介紹第二代 Tesla 架構的改進之後,接下來讓我們回到產品本身,首先登場的就是一口氣突破 NVIDIA 過去所有晶片電晶體數目與晶片面積紀錄的 GT200 (據說在當時台積電也是第一次生產面積這麼大、電晶體數量這麼多的晶片),對了,改名叫做 GT200 而不是 G100 的原因其實是反映了之後 NVIDIA 喜歡給架構取名字並且一個架構用兩代的慣例,GT 是 Graphics Tesla 的意思。

GT200 從代號上不難看出它是最完整的第二代 Tesla 架構核心,由 10 組 TPC 組成,每組 TPC 內有三組 SM,因此一共包含了 240 個串流處理器 (SP),加上新的雙精度浮點數運算單元與高達 512-bit 的記憶體控制器,因此 GT200 的電晶體數比起上一代已經相當驚人的 G92 來說再次翻了一倍,並且基於相同的 65 奈米製程 (GT200-A2)。
由於上一代 GeForce 已經用到 9 系列了,下一代必然得面臨進位的問題,因此 NVIDIA 從 2008 年開始使用新的產品命名法則,改為「英文前綴」加上三位數字的方式組成,其中第一位數字代表「系列別」,第二、三位數字則是「次等級」,而英文前綴的部分由高到低有 GTX、GTS、GT 與 G 或無印四種,一般來說中階以上產品全部都掛 GTX,中低階產品掛 GTS,低階與入門產品則掛 GT,掛 G 或無印的型號很少,通常是非常入門的 OEM 用途產品。

基於 GT200 核心的第一批產品是推出於 2008 年 06 月的 GTX 280 (602/1296/2214 MHz) 與 GTX 260 (576/1242/1998 MHz),前者是完整的 GT200 核心,後者則是有兩組 TPC 被屏蔽因此只剩下 192 個 SP,記憶體控制器也被刪掉一組因此記憶體頻寬的數值是挺特別的 448-bit。

這代產品在外觀上看起來其實與先前的 G92 顯示卡沒有太大差別 (NVIDIA 沒設計新的散熱器),PCB 的布局其實也很相似,但供電模組的部分似乎變得更複雜了,值得注意的是,如同 G80 一般,GT200 因為核心複雜度太高,因此 RAMDAC 的部分又被拉出來了,所以在左邊可以看到重出江湖的 NVIO 晶片。

而在 GTX 260 上市三個月之後,NVIDIA 突然無預警地重新推出了另一款「同樣叫做 GTX 260」的產品,但是使用了另一個版本的 GT200 核心,屏蔽的 TPC 從兩組變成一組,因此發生了同樣叫做 GTX 260,但前後期版本的 SP 數量與性能卻有著明顯不同的情況 (所以有些廠商稱升級後的 GTX 260 為 GTX 260+)。

之後在 2009 年 01 月 NVIDIA 循 G92b 的模式將 GT200 升級到新的 55 奈米製程,也就是上圖的 GT200-B3 (不過因為有鐵蓋而且腳位定義不變所以外表看不太出來),並且推出了新的一批產品,其中打頭陣的是 NVIDIA 的第四張單卡雙晶片顯示卡-GTX 295。

乍看之下長得其實跟 9800 GX2 很像,只是這回外殼真的變成金屬噴沙了,重量自然也跟著往上跳了一大步,由兩顆巨大的 GT200-B3 核心組成 (雖然是完整版的 GT200,但有一組記憶體控制器被關掉了所以只剩 448-bit,而且為了解決散熱與穩定問題,時脈調降為 576/1242/1998 MHz)。

設計安排上跟 9800 GX2 有點類似,同樣是使用兩塊 GPU 面對面中間夾著散熱器的設計,並且使用排線作為兩顆 GT200 之間的溝通橋樑 (不過似乎變成兩條了,可能數據量變大了吧)?但背面的部分就不太一樣了,這次 GTX 295 並沒有連同背面也包到殼裡 (可能是為了散熱考量或是改成金屬殼之後過重的問題)。

不過其實這還不是 GTX 295 的最終型態,NVIDIA 在後來居然成功把兩顆 GT200 放在同一片 PCB 上了,進一步降低了製造 GTX 295 的成本 (所以後來 GTX 295 在市場上流通的量其實是單層版比較多)。

都做到這份上了,除了壯觀之外還能說甚麼呢?不過 GTX 295 這一代的散熱情況似乎不是太理想,改成單 PCB 之後由一個風扇來服侍兩個這麼巨大的 GT200 核心顯然還是不太夠 (公版的設計是風扇放中間負責吸入冷空氣,再由兩側排出,但這樣風流難免在轉彎之前被減弱。

不過照例在推出單卡雙晶片的旗艦卡王之後,NVIDIA 還會用相同的硬體推出正常的單晶片旗艦,這次也不例外,NVIDIA 在 GTX 295 上市幾天之後就端出了單晶片版本的 GTX 285 與 GTX 275。

GTX 285 基本上是為了承接 GTX 280 的位置而設,因此在規格上與 GTX 280 幾乎是一樣的,只是得益於時脈提升因此可以把時脈拉高到 648/1476/2484 MHz,至於 GTX 275 則是從 GTX 295 直接簡化而來的版本,使用相同的記憶體控制器與 ROP 配置,不過由於僅有單一晶片因此時脈可以維持在 633/1404/2268 MHz 的較高水平,而最後一款基於 GT200-B3 和新的產品則是 GTX 260 的第三版,內部 Shader 時脈從 1242 MHz 小幅提升到 1350 MHz 而其他部分則沒有變化。
總體來說 GTX 285 的性能大約比 GTX 280 要來得高 5 ~ 10% 左右。
GT215/GT216/GT218 核心`
其實硬要說的話要把這三款核心稱為第 2.5 代的 Tesla 架構其實也可以,不過因為並沒有高階產品基於這個版本的架構因此我就把他們跟 GT200 合併在一起講了,這三款晶片之所以被稱之為 GT21x 實際上是因為相較於 GT200 來說他們增加了對 DirectX 10.1 硬體的支援以及提升到 40 奈米製程的緣故。

這幾款核心基本上都是針對低階與入門市場設計的,因此晶片的規模都很低,運作時脈也不高 (有一說是因為當時台積電的 40 奈米製程還有問題導致時脈拉不起來),在 GeForce 200 系列當中中階產品的角色則是將由 G92 繼續擔綱,首先看到的是三款核心當中規模最大的 GT215,也就是後來的 GT 240,是由 4 組 TPC (包含 96 個 SP) 所組成,記憶體控制器也僅留兩組 (128-bit 頻寬),同時是系列當中記憶體支援種類最多的一款晶片 (支援 DDR2、GDDR3、GDDR5 記憶體),時脈最高僅有 550/1340 MHz。

後來 NVIDIA 宣布 GeForce 300 系列將與 GeForce 100 系列一樣成為 OEM 專屬改名產品系列之後,採用不同種類記憶體的 GeForce GT 240 被改名為 GT 340 (550/1340/3400 MHz,GDDR5)、GT 330 (500/1250 MHz,GDDR3 或 DDR2)、GT 320 (540/1302 MHz,但只有 3 組 TPC) 三種型號。

至於規模更小的 GT216 核心則是最多只有 2 組 TPC (也就是 48 個 SP),其他參數則與 GT215 相同。

GT216 一開始只有一個型號-GeForce GT 220 (625/1360/1580 MHz),搭配 DDR3 或 DDR2 記憶體,不過後來幾經改名之後又做為 GeForce 315 (475/1100/1580 MHz,DDR3)、GeForce 405 (475/1100/800 MHz,DDR3) 推出。

至於最後一款核心則是結構最為簡單的 GT218,由於結構上砍到只剩下一組 TPC 而且記憶體控制器也只剩下一組 (64-bit),又加上使用了新的 40 奈米製程的關係,很有可能是截至當時為止 NVIDIA 所發布過面積最小的晶片。

基於 GT218 晶片的型號主要有 GeForce 210 (完整版 GT218,後來被改名 GeForce 310) 與 GeForce 205 (閹掉一半的 GT218),時脈設定均為 589/1402/1000 MHz,可選擇搭配 DDR2 或 DDR3 記憶體。

不過除了這三個型號之外還有另外兩個比較特別的型號有採用 GT218 的版本,其中之一是當時被稱為萬年裝機卡的 GeForce 8400 GS,其第三個版本就是以 GT218 為基礎,規格上類似 GeForce 210 但時脈較低 (450/900/800 MHz),而另一款則是由 GeForce 310 再次改名而來,作為 GeForce 400 系列的最入門產品發售,即 GeForce 405 (589/1402/790 MHz)。

不過有一點要特別留意的是,雖然 GT218 的晶片結構相對簡單很多,使用到的電晶體也少,並且用上了當時最先進的製程,不過實際上 GT218 的功耗表現與發熱量都不甚理想,這或許也就是為什麼 NVIDIA 沒有把 GT200 也升級到新製程的原因吧 (當然主因應該是預期 DirectX 11 很快就會出來所以懶得對現有產品做修改,畢竟大核心實在太複雜)。
Table of Contents
第二代 Tesla 架構的銷售表現差強人意
Tesla 架構在後期由於規模與複雜度比起上一代來說成長了太多,並且由於 NVIDIA 在 GeForce FX 失敗之後趨於保守因此沒有導入新的製程,最後造成的結果就是大核心的成本居高不下與良率、產量拉不起來,因此 Tesla 架構產品其實沒有獲得太大的成功 (這個問題在 GT200 上特別明顯,而且 GT200 其實在實際遊戲用途上沒比 G92 快太多),甚至反而在 AMD 推出單卡雙晶片產品之後面臨性能拉不起來的問題 (兩顆 GT200 實在太耗電也太熱,成本也太高,因此配置不得不砍,時脈設定也不得不降低)。
在 Tesla 架構後期與下一代的 Fermi 架構推出之間的 2008 ~ 2010 年對 NVIDIA 來說應該是頗為難熬的幾年吧,在這幾年之內 NVIDIA 除了因為 Intel 收緊晶片組授權政策而撤守晶片組市場之外,還因為 Intel 在 Nehalem 世代的 CPU 開始強化內建顯示扮演的角色因此失去了不少主流與入門層級的市場佔有率,除此之外剛剛我們才提過 Tesla 架構的複雜度太高使得成本與價格壓不下來、性能提升不如預期,但競爭對手 AMD 的 RV770 卻有著成本低上許多、良率高上許多、價格便宜許多性能卻差不多的優勢 (我會在之後的文章介紹 AMD 的策略),這更是讓 NVIDIA 的處境變得更加雪上加霜許多 (結果導致 GeForce 9800 GTX 只好一直降價)。
不過 Tesla 架構是未來十年 NVIDIA 用於發展 GPU 的基礎,後來的每一代 NVIDIA GPU 當中其實都還看得到 Tesla 的影子 (後來的 Fermi、Kepler、Maxwell 與最新的 Pascal 都是如此,即便改了名字,但 TPC、SM、SP、Unified Architecture 這些概念在後來其實都一直被反覆使用),同時也是讓 NVIDIA 在未來十年內能夠逐步吃下 AMD 原先佔據的市場份額,逐漸發展到今天這種幾乎立於不敗之地局面的重要功臣,並且也是確立了 NVIDIA 未來將朝向通用計算領域大舉進攻的標竿產品。
Intel 與 NVIDIA 之間的爭執
如果你對 NVIDIA 與其創辦人的認識夠深刻的話,應該會對 NVIDIA 的公關部門及其創辦人多次嘲諷 Intel 的言論有一點印象,其實這兩家公司之間結下的樑子是在 2008 年開始,並在 2009 年才正式爆發的,由於與 Tesla 架構的時代很接近,而且 NVIDIA 這間公司跟其他公司吵架的方式實在很「有趣」,所以我就在這裡一併談談。
關係生變的開始,命運多舛的 Intel Larrabee
NVIDIA 與 Intel 關係開始生變的歷史應該可以追溯到 Intel 在 2008 年揭示了它們正在發展一款稱為 Larrabee 晶片的計畫 (這是 NVIDIA 開始找 Intel 鬥嘴的開始 XD)。

如同上回介紹過的,G80 是 NVIDIA 開始搞 GPGPU 通用運算的開始,讓 GPU 開始支援處理一般的運算並且分攤更多 CPU 的工作,並且以逐步取代 CPU 為主要目標,這對以 CPU 為主要業務的 Intel 來說當然是個嚴重的威脅 (萬一哪天 GPU 真把 CPU 取代了,Intel 不就沒戲唱了嗎),而 Larrabee 就是 Intel 對 GPGPU 的反制,與 GPGPU 的發展方式相反,Larrabee 的目標是以現有的 CPU 與 x86 指令集架構為基礎,並透過 Many-Core 等設計強化在並行運算方面的能力以讓 CPU 變得能夠處理 GPU 的工作。
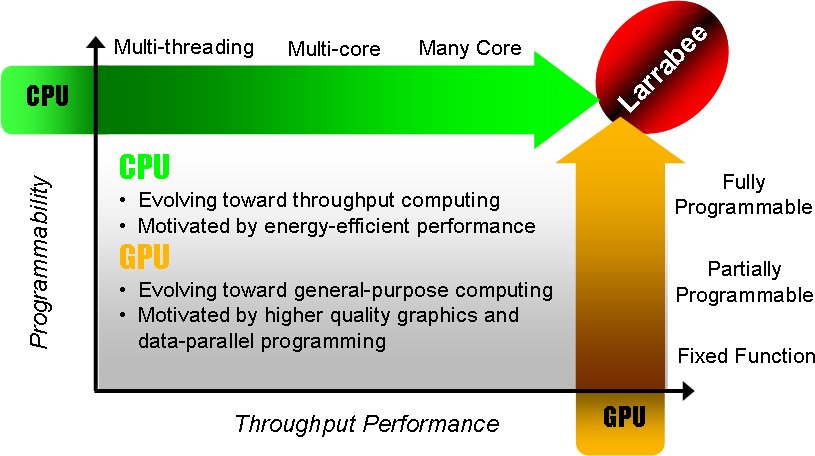
Larrabee 是 Intel 從 i740 起睽違十年首次回到獨立圖形運算晶片的領域,而 Intel 對 Larrabee 的期望與預期非常的高,甚至曾經在 2008 年的 IDF 上誇下海口說 Larrabee 的出現會讓傳統的 GPU 在未來三年之內「徹底消失」,並順勢提出了以「視覺運算」取代傳統的「繪圖管線」的概念,這等於是對當時 GPU 與 GPGPU 界的龍頭 NVIDIA 直接下了戰帖,這在當時確實引起了一陣軒然大波 (畢竟大家對 Intel 龐大的資金很有信心,而且其實一直以來都有希望 Intel 投入圖形市場以牽制 NVIDIA 和 AMD 的聲音)。

前面說過 Larrabee 的思維實際上是跟 GPGPU 正好顛倒的,所以 Intel 的目標實際上是要生產一種「圖形運算性能勝過 GPU」的 CPU,因此 Intel 理所當然選擇了自家發明的 x86 指令集體系作為發展的基礎,雖然 Intel 這樣的選擇很合理也很理所當然,但其實此話一出許多人都不禁開始懷疑 Intel 真能造出 Larrabee 了,畢竟相較於一般 GPU 所使用的指令集架構來說,x86 的複雜度高出許多,對於高度平行運算的圖形演算需求來說,可能會面臨需要大量核心才有足夠效能,但卻很難增加核心數目的窘境,就算好不容易加上去了,預期上在功耗方面也會是個很大的悲劇。
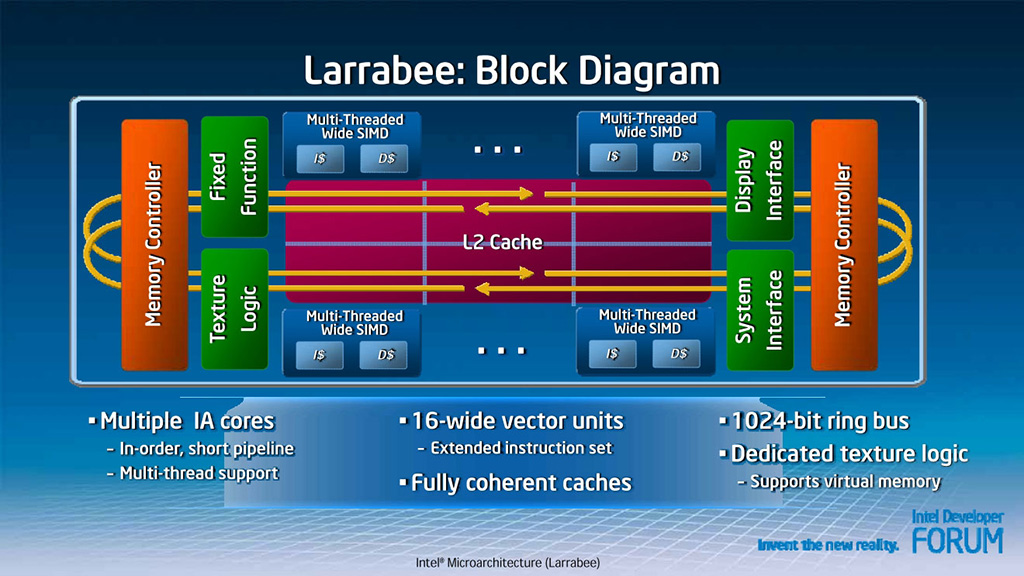
Larrabee 計畫的歷時很長,先後宣布過很多不同的架構規劃版本,上圖應該是屬於比較前期的規劃,當時 Intel 的計畫是把骨董級的 P54C 架構重新拿出來修改,透過並排至多 10 個順序執行 x86 處理器核心與 2 個亂序執行 x86 處理器核心搭配周圍的顯示介面與中央的共享 L2 快取搭配環形資料通道來設計這款繪圖晶片。
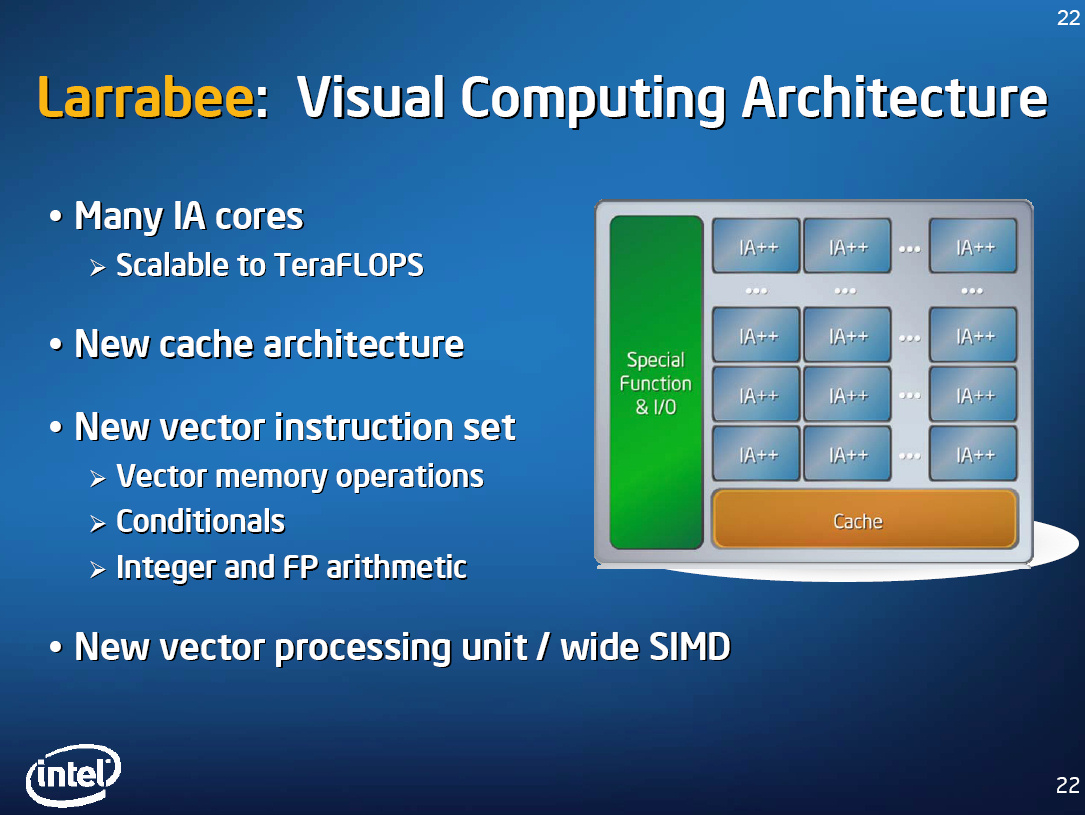
隔年 Intel 又把 Larrabee 的架構轉變成上面的形狀,由一堆 IA Core 堆疊組成,共用底下的一大塊快取記憶體,但取消了環狀通道的設計,而與此同時外界也越來越看不懂 Intel 的 Larrabee 葫蘆裡到底要賣的是甚麼藥了。


不過後來 Larrabee 計畫的下場大家都知道了,隨著日子一天一天過去 Larrabee 成為 Intel 歷史上少數公開之後卻未能完成的研發計畫 (甚至連架構解說都已經做了,但最後沒有產品出來),從 2008 年 Larrabee 這個出現在公眾面前之後,很長一段時間 Larrabee 的身影始終只在 Intel 發佈的投影片上出現,從來沒有實際進行過實務的公開測試,在 Sandy Bridge 出台之後大家也就漸漸淡忘 Larrabee 的存在了。
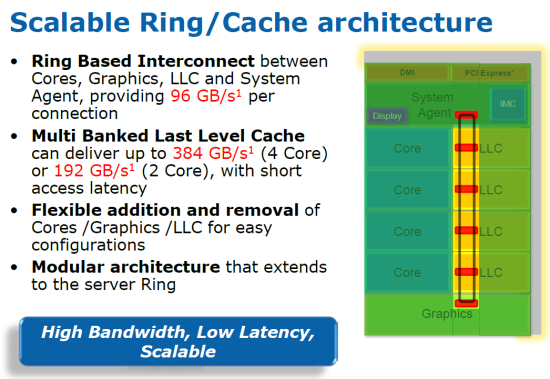

而後來公眾再次想起 Larrabee 則已經是 2009 年底 Intel 宣布 Larrabee 計畫將不會作為獨立 GPU 推出的事情了 (不過直到 2011 年 Intel 都還是一直嘴硬不肯承認 Larrabee 失敗,堅稱 Larrabee 只是還不是時候推出而已),不過我們確實可以在很多後來 Intel 的產品當中看到 Larrabee 的影子,例如 Sandy Bridge 使用環狀資料通道來連結運算核心與共用 L2 快取就是原先 Larrabee 中有用到的設計 (上圖),而下圖中的 Larrabee 運算架構規劃其實根本與 Nehalem-EX 沒甚麼兩樣。
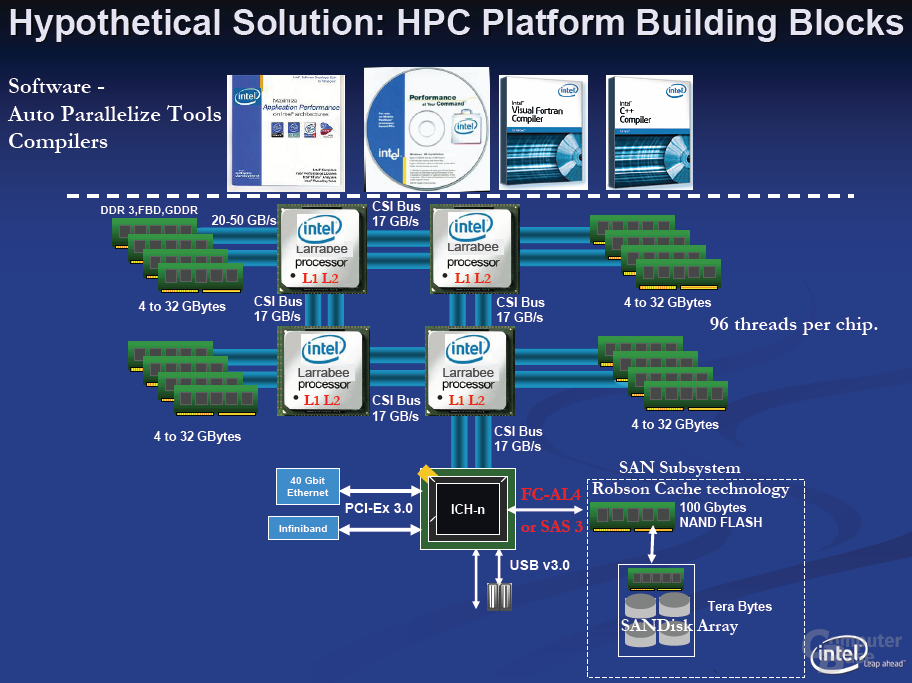
至於 Larrabee 晶片本身後來則是在拿掉圖形功能與圖形介面之後成為了 Xeon Phi 協同運算處理器的前身,迄今已經推出三代的產品了 (從圖中可以得知其實 Larrabee 早在 2005 年就開始發展了)。
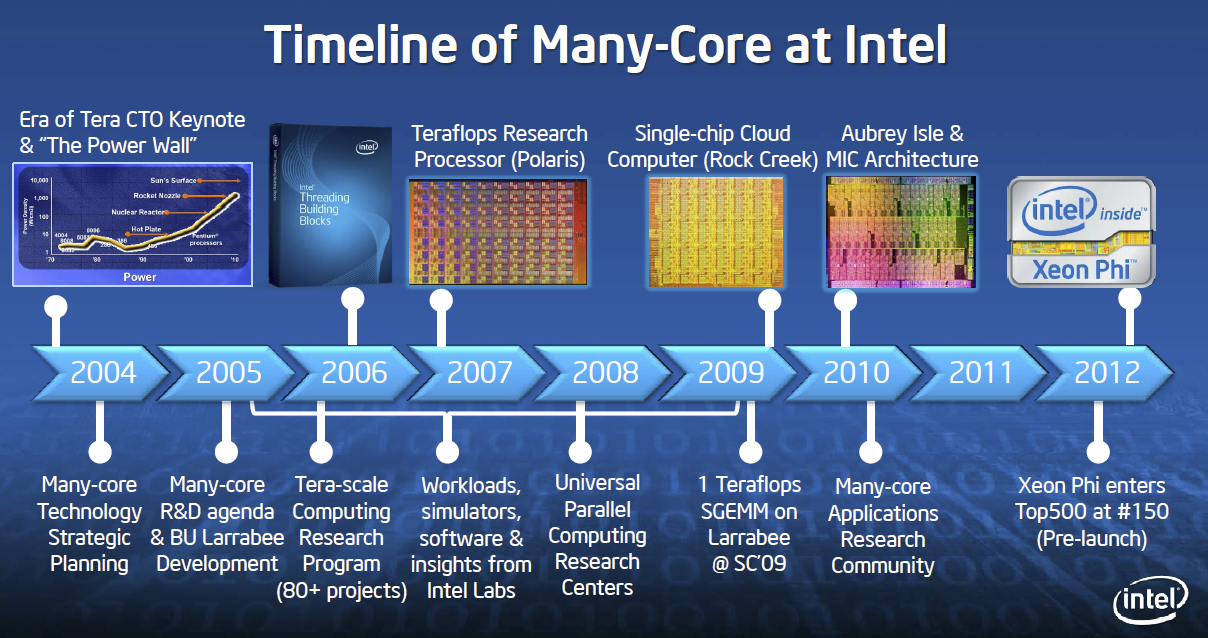
而且實際上在後來 NVIDIA 與 AMD 提出的新圖形晶片架構當中,也引入了不少 Larrabee 所發想的策略,因此即便 Larrabee 本身沒有成功,但卻一定程度上影響了後來幾年個人電腦的發展方向。
晶片組授權爭議
如果你還記得的話,我在介紹晶片組的章節當中其實介紹了不少款由 NVIDIA 發展的晶片組,而且 AMD 與 Intel 平台的款式都有,所以在早年其實 NVIDIA 與 Intel 之間的關係並不壞,一方面也因為 Intel 當時內建顯示的性能很差無法對 NVIDIA 的 GPU 造成威脅,所以 NVIDIA 與 Intel 之間其實沒有甚麼吵架的理由,反而是相當長期的合作夥伴,即便有 Larrabee 與 NVIDIA 的 GPGPU 路線之間發生競爭的情況,也沒有造成太多實質關係上的變化。
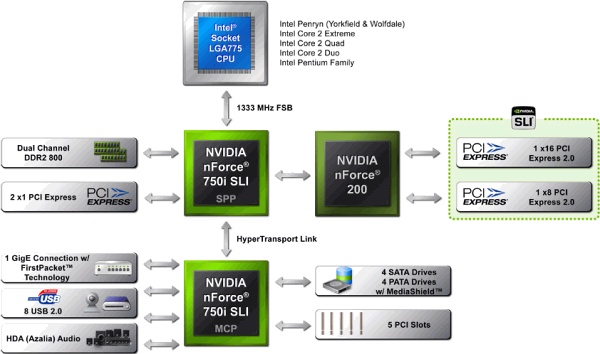
不過這樣的情況卻在 Nehalem 與 X58 上市的時候改變了 (也就是 Core i 系列開始取代 Core 2 系列的時候),還記得我曾經在處理器篇談過的 FSB、QPI、DMI 這三個名詞嗎?我們知道 Intel 從很早開始一路到 Core 2 系列為止都是使用 FSB 作為 CPU 與晶片組之間溝通的管道,而從 Nehalem 開始則分為高階 HEDT 平台使用 QPI、一般主流平台使用 DMI 兩種作法,共同的地方是都捨棄了傳統的 FSB。
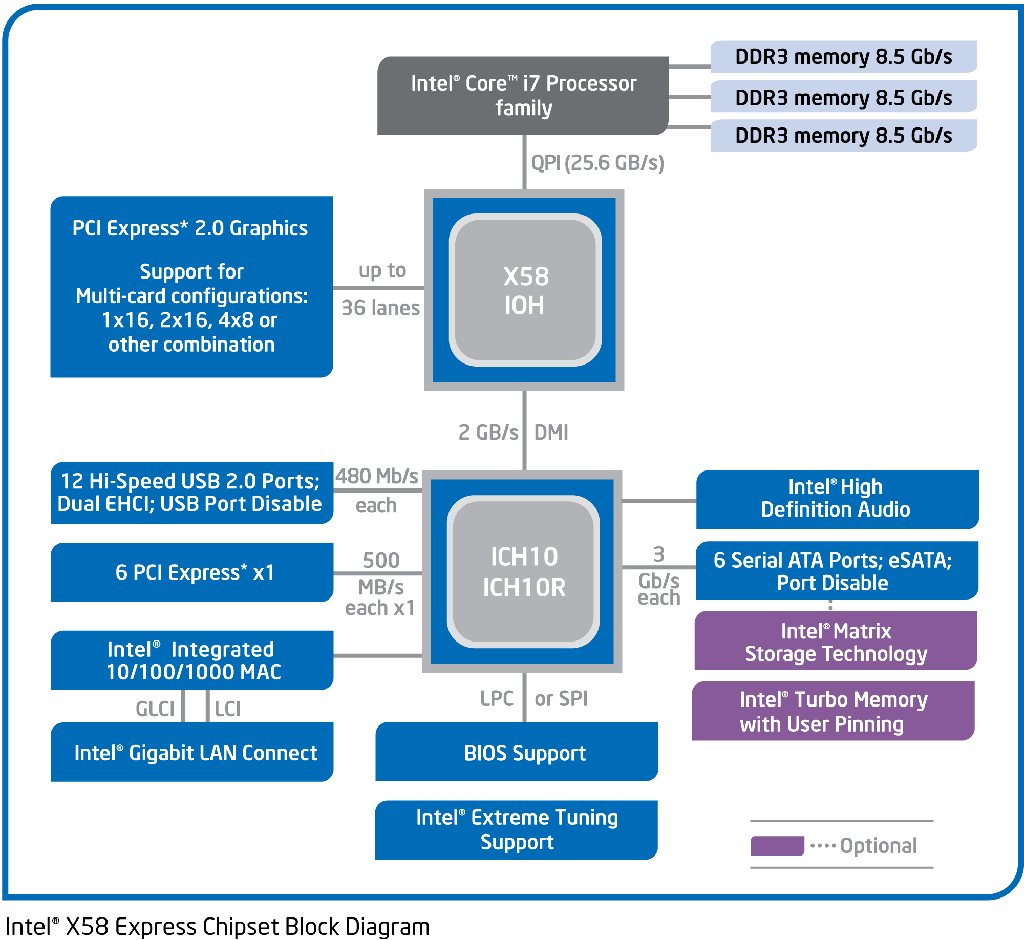
實際上當年 Intel 為了吸引廠商設計相容 Intel 平台的晶片組,因此授權了數家廠商使用 Intel 持有專利技術以設計並生產相容的晶片組,而為了避免每次出新 CPU 或新架構就要重新跑一次麻煩的法律授權程序,所以 Intel 當時在與第三方晶片組廠商之間的協議是以「允許廠商在 Intel 推出新 CPU 或新平台的時候,使用 Intel 的匯流排總線技術」為範圍。
說了這麼多那真正的爭議到底在哪裡呢?其實是 NVIDIA 與 Intel 雙方對合約內文字意義的見解不同才真正引爆這場紛爭的。NVIDIA 認為根據在 2004 年簽訂的授權合約,Intel 必須允許 NVIDIA 生產基於 QPI 與 DMI 技術的新款晶片組,但 Intel 方面卻認為「授權的範圍僅止於基於 FSB 與 AGTL+ 技術的平台」,因此要求 NVIDIA 不准生產與「整合記憶體控制器的 Intel CPU」相容之晶片組產品,這就是雙方關係急轉直下的開始 (其實主要是 Intel 的問題,因為 Intel 看見晶片組的市場與利潤了,加上想推自家的整合圖形晶片組與後續的處理器內建顯示,所以希望把晶片組的授權收回來才找了這理由,因此從 X58 開始 Intel 平台的晶片組就只剩下 Intel 自家產品了,實際上 AMD 也採用了類似的策略,因此現在已經沒有 AMD 與 Intel 之外的晶片組廠商了)。
正式決裂
最終 NVIDIA 與 Intel 的正式決裂是發生在 2009 年 02 月,Intel 正式向法院遞狀控告 NVIDIA 侵犯它們的處理器專利的時候,Intel 方面的聲明與訴狀是指出在 2007 年 Intel 就通知 NVIDIA 它們將在 2008 年推出 Nehalem 架構的處理器,並且多次通知 NVIDIA 它們的晶片授權並不包含 Nehalem 架構產品,但 NVIDIA 仍執意要生產與發佈基於 DMI 架構的晶片組產品。
NVIDIA 在獲悉被 Intel 控告之後不久就發了一篇措辭相當強硬的新聞稿回應 Intel,當中直接稱「未來 PC 的靈魂將是 GPU 而不是 CPU,Intel 此舉是為了保護其所在的黃昏產業」,還直接在新聞稿裡面寫到搭配 GeForce 9300 晶片組的電腦,在 3DMark 2006 測試當中的性能是 Intel 945GC 方案的十倍,並且暗示當時能有這麼多家廠商使用 Intel 的 CPU,其實是 nForce 晶片組的功勞,Intel 現在提起訴訟根本是眼紅 nForce 晶片組的成功與防範 NVIDIA 改變 Intel 主宰 PC 平台的現況,哇,這嗆得可真夠大力了。
NVIDIA 的反擊
後來在經過一個月的準備之後 NVIDIA 則向法院遞狀反控 Intel 違反授權合約並且透過媒體放話傷害 NVIDIA 的商譽,CPU 與 GPU 的龍頭之間的法律大戰就此揭開序幕,Intel 以緊咬 NVIDIA 不開放 QPI 與 DMI 授權讓 NVIDIA 無法生產新一代晶片組為主要目標,而 NVIDIA 則用消極不提供 SLI 技術授權與放話加速推動與 VIA 結盟推出支援 VIA 處理器的晶片組給 Intel 晶片組的方式進行反擊。
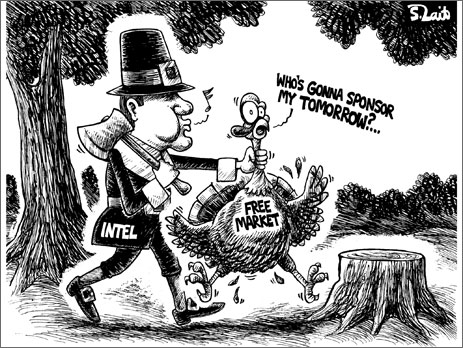
不過相較於這些手段來說,比較有趣的是 NVIDIA 居然建了一個叫做 Intel’s Insides 的網站,從 2009 年 09 月開始發表了 20 多張嘲諷 Intel 的漫畫,還直接在右下角蓋上自家的 Logo XD。
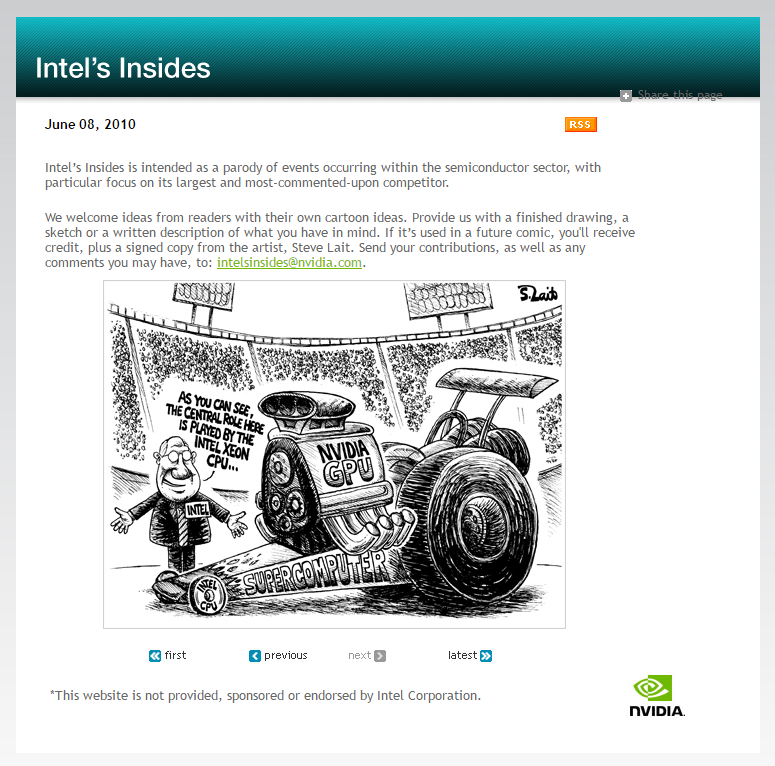
其中有一些漫畫還蠻有趣的,以上面這張來說講得是 Intel 口口聲聲說他們 CPU 是電腦高性能的關鍵,但其實在 NVIDIA 眼中真正推動這部「跑車」的「引擎」其實是他們的 GPU,Intel CPU 只是微不足道的小輪子罷了,而下面這張則是在嘲諷他們的 Tick-tock 戰略與難產多時的 Larabee。

下面這張則是把 Intel 畫成運鈔車以暗諷 Intel 的財大氣粗,在輾過 AMD 這道障礙起伏的時候掉了一堆鈔票卻毫無感覺。

NVIDIA 也對 Intel 壟斷市場的行為多所指責,認為 Intel 使用綁樁與傭金的方式來掐住自由市場的脖子 (不過老實說 NVIDIA 的 The way it’s meant to be played 計畫好像也不遑多讓?)。
Larrabee 持續的難產與打高空的目標更是 NVIDIA 與其 CEO 最主要的嘲諷目標,Intel 甚至曾經反諷 NVIDIA 的 CEO 其實根本就是 Larrabee 的最佳代言人,而且還不領薪水。

並且認為 Intel 其實根本已經轉型成「律師公司」了,公司的研發進度不斷落後,主軸卻移轉到如何控告 NVIDIA 等公司身上之類的。

接下來這張圖其實跟台灣的「無薪假該得諾貝爾獎」差不多,暗諷 Intel 應該可以得到史上最佳違反反壟斷法導演奧斯卡獎。

最後這張站長個人覺得挺貼切的,Intel 一直想拓增自己在行動運算市場的領土,甚至想跳下去嘗試 ARM 架構的 RISC 產品,但腳邊的 x86 架構 CISC 腳鐐總是讓 Intel 在行動市場方面的策略顯得紊亂無比。

達成和解
不過後來 Intel 與 NVIDIA 還是在訴訟宣判之前達成和解了,大致上是以 Intel 花錢消災而除此之外啥都沒改變做結,在 2011 年初 Intel 與 NVIDIA 無預警宣布了下列的協議:
- NVIDIA 與 Intel 之間的晶片組授權協定 (FSB/AGTL+) 延長六年。
- NVIDIA 無法取得 Intel 的 DMI/QPI 授權 (不過 NVIDIA 也宣布不做晶片組了)。
- Intel 分六年支付 15 億美元給 NVIDIA (今年是最後一期,付了兩億美元)。
- NVIDIA 可以使用部分 Intel 的專利,但不包含 x86 架構的授權。
- Intel 可以使用 NVIDIA 的部分圖形專利。
- NVIDIA 授權 X58 平台支援 SLI 技術。
不過此後 NVIDIA 與 Intel 的關係基本上已經由合作轉為競爭,NVIDIA 與 Intel 多次在發表會上的唇槍舌戰大家應該也都有目共睹了,Intel 主張內建顯示的性能相較於早期已經提升了近百倍,足以滿足「絕大多數遊戲玩家的需求」,而 NVIDIA 則主張不如把購買 Core i7 處理器的錢拿去購買入門級的 GPU,對於遊戲性能的提升反而有用很多。