

接下來我打算接續上一篇的主題繼續介紹 Terascale 架構的後續衍伸型 (從 2007 年開始一路到在 2012 年推出 GCN 架構之前 AMD/ATI 的所有顯示晶片都是從 Terascale 架構發展出來的)。
Terascale 1.5
- 推出日期:2008 年 06 月 (R700)
- 所屬系列編成:Radeon HD 4000 系列
- API 支援:DirectX 10.1、OpenGL 3.3、OpenCL 1.0
- Shader Model 支援:SM 4.1
當功耗變成問題的時候…
還記得在上一篇談到 RV670 的時候,我曾經說過 RV670 是 AMD 接下來在產品開發策略上大幅轉變的預告嗎?從 R700 系列核心開始有許多方向上的轉變會開始很明顯地體現在 AMD 的圖形產品規劃上,為了瞭解這一點,我們得先回到 AMD 開始構想 RV670 的時候才行。
以往這些晶片廠商在設計新的晶片時思考的問題其實很單純,「怎麼樣的設計可以壓榨出更多的性能?」如同電腦玩家們經常抱持的性能至上論一般,設計晶片架構的人其實也是這麼想的 (畢竟這是營利事業不是慈善企業,本來企業在發展產品的時候想法與思維就不該偏離消費者太遠,除非你是蘋果有大把到花不完的資金跟足夠的「Courage」可以讓你挑戰消費者的耐性與腦波強度),NVIDIA 如此、Intel 亦如此,ATI 當然也不例外,因此過去這些年它們基本上都致力於發展「更複雜的架構」、「更龐大的晶片規模」、「塞入更多的電晶體」,這樣的狀況在高度平行化的 GPU 領域又尤其明顯,有很長一段時間 GPU 的性能提升其實是奠基於「把架構裡面的東西多複製幾組上去」。


在這樣的思維底下,有很長一段時間 GPU 廠商設計產品的方式稱之為 Top-down Approach,也就是先設計出一款當下技術極限所能造出規模最大、最極致的產品,之後再用閹割的方式來設計出較低階的款式。
但是在 2006 年的時候,半導體產業的藍色巨人 Intel 第一個踢到鐵板了,Netburst 架構在不考慮功耗成長的情況下追尋性能不斷持續成長的目標,不顧架構效率只一味追求時脈數字的成長與管線深度的增加最終使得當初的 10 GHz 目標在 2006 年瞬間化為泡影,Intel 度過了公司創立以來數一數二艱難的一年,在這樣的背景之下 AMD 向另一個方向轉彎其實也不是甚麼奇怪的事情了。
當然從現在的角度來看可能會覺得當年人們設計晶片從不考慮功率問題是一件很 Ridiculous 的事情,不過實際上在物理的角度來看這樣的作法並不奇怪,在散熱器能解決的功耗範圍內不去考慮功耗其實是很自然也很符合人性的結果,畢竟在這種情況下直觀看起來就是溫度一樣壓得住而性能卻提升了,但一旦跨過了那道門檻之後,無法解決的功耗就會變成持續提升性能不得不突破的嚴重障礙了。
AMD 的新策略
在規劃 R700 系產品的時候 ATI 正好面臨了這個問題,R600 嚴重的延期與各種難解的問題都再再顯示了設計更大的晶片、更複雜的電路會造成許多更嚴重的問題與耗費更多的時間,但對 ATI 來說更大的問題是如果在與 NVIDIA 之間性能王座的爭奪戰上落敗,拱手把光環讓給對方會不會是一種自殺行為?這樣交迫的處境使得 ATI 走到了這個十字路口上:
- A:堅持現有的發展策略
努力造出比 NVIDIA 更強大的晶片、比 R600 規模更大、速度更快、塞入更多且更複雜的電路,力求搶回被 NVIDIA 奪走的性能王座,就像過去十年那樣。 - B:既然硬拚沒用,就走自己的路吧
放棄與 NVIDIA 之間的性能王座之爭,以將公司獲利最大化為目標,集中精力搞好市場規模最大、最多消費者可能購買的中階產品。
如果是你會選擇哪條道路呢?選 A 的話,ATI 當時的技術能力與手上的現金真的足夠支撐比 R600 規模更加激進的 R700 嗎?從 R500 以降的無限延期災難若持續到 R700 上,ATI 還有那麼多的體力可以消耗嗎?就算被 AMD 收購了,有那麼多錢可以燒嗎?
選 B 的話呢?NVIDIA 取得了性能王座的光環效應,在媒體上獲得了大量的曝光很有可能導致落敗的 ATI 被邊緣化而在銷售方面面臨困境,而且一旦脫離了戰場,很有可能 ATI 最後下場會是被邊緣化並且永遠沒有機會重返龍頭寶座。
當時 ATI 的管理階層就是面臨這樣的兩難,儘管現在看來當時選擇走了 B 路線的主管是做了明智的抉擇,才使得 AMD 的圖形部門得以繼續存活至今並且繼續維繫著 NVIDIA 與 AMD 兩強爭霸的局面,但對於過去十年都在致力於創造比 NVIDIA 產品更快、更先進、更龐大、更複雜的競爭產品的工程師來說,第一個想法大概是公司想投降,再來就是覺得主管腦袋壞掉了吧。
吹響反攻號角
相對於當年被寄予厚望但卻面臨漫長延期、實際性能遠不及理論性能而徹底失敗的 R600 來說,RV670 算是成功的一款產品,不過並沒有辦法從 NVIDIA 手中搶回過去幾年失去的市佔率,因此 R700 系列是否能夠創造更大的成功對於後來 AMD 圖形部門的命運來說至關重要,但要發展龐大的 R700 還是較小的 RV770?這是個很重要的問題,也曾經在 AMD 的開發團隊中引起熱烈的討論。
由於 R600 的失敗與 RV670 相對而言的成功,因此當時 AMD 圖形部門的主管拍板定案全力發展 RV670 的後續產品做為次世代 GPU 的藍本,也就是後來的 RV770 (所以後來 R700 這核心並沒有出現),在市場上 AMD 決定放棄在頂級玩家市場中與 NVIDIA 正面衝突 (頂多用雙晶片的方式填補一下市場空缺),轉而以發展中高階市場的產品為主 (實際上絕大多數顯示卡消費都是落在這級距)。

實際上 AMD 希望 NVIDIA 繼續往更大、更複雜的方向前進,並暗自期待 NVIDIA 踢到鐵板的瞬間 (確實 NVIDIA 也真的這麼做了,所以 GT200 成效不彰),不過說起來也不知道 NVIDIA 與 AMD 是賭氣還是怎麼樣的,NVIDIA 此後還真的就一直繼續往超大核心邁進並且不斷突破極限 (看那精美的 GP100),而 AMD 還真的也就不太碰頂級消費群了。
回到架構本身
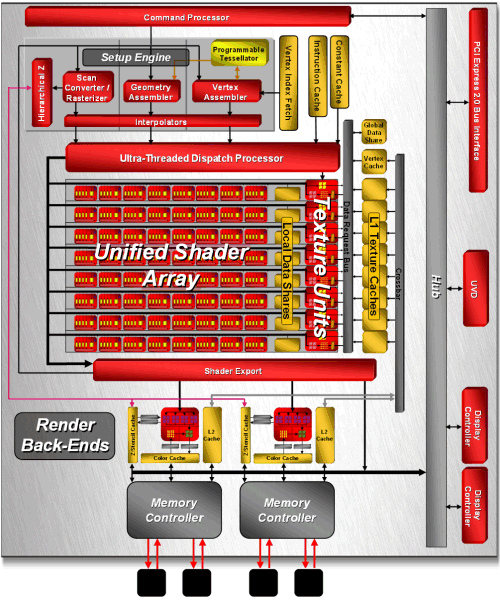
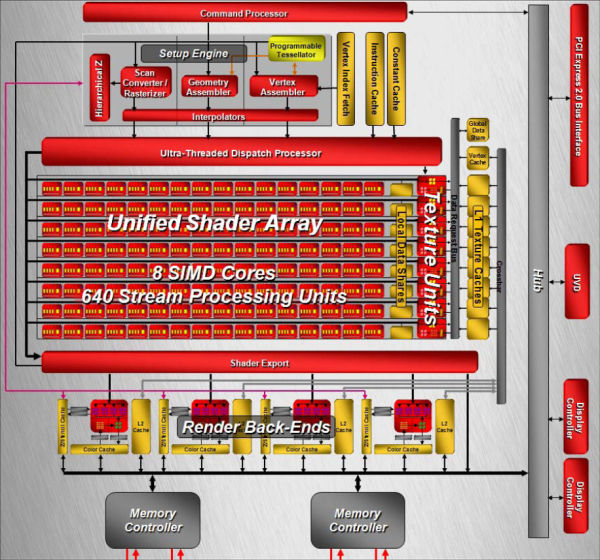
看了 AMD 在發展策略上的轉變之後,接下來讓我們回到架構本身來看看 RV770 的技術特性吧,下面這張圖就是 RV770 的架構。
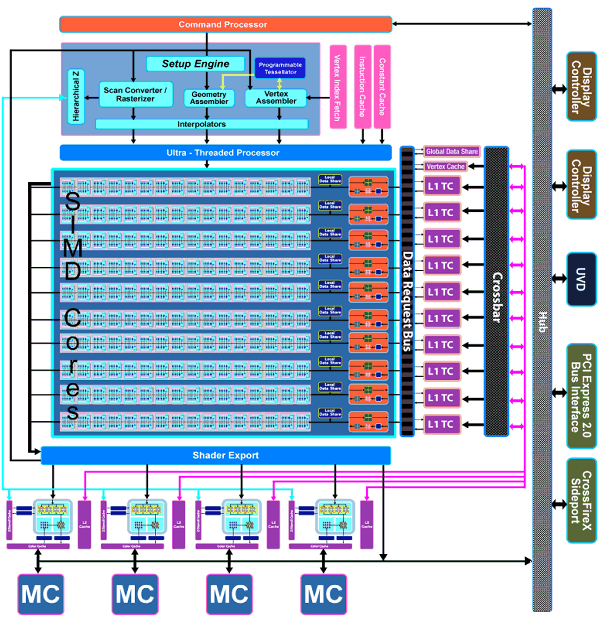
單看上面這張架構圖大概會覺得相較於 RV670 來說 RV770 的架構很壯觀吧?不過其實把方向稍微轉一下就會發現整體的架構其實沒有很大的改變,主要出現的差異是落在數量與編排方面,首先上半部的 Command Processor、Setup Engine 與 Ultra-Threaded Dispatch Processor 基本上沒有太大的變更,仍然不脫 R520、R580、R600、RV670 一路傳承下來的影子。
SIMD Array 大擴編
看到 RV770 的架構第一眼發現的不同應該就是不論數量或寬度都有著大幅成長的 SIMD Array 吧?還記得 R600 與 RV670 當中的編制是每個 SIMD Array 當中有 16 組運算單元,而每個運算單元中各有 5 個 ALU 電路 (被 AMD 命名為 SMU),因此 RV670 與 R600 有高達 320 個 SMU。

然而在 RV770 當中,原本至多只有四組的 SIMD Array 一口氣被擴編到了十組之多,而且每組當中的運算單元數量也從原來的 16 組翻倍變成高達 32 組,因此 RV770 的 SMU 數量一舉提高到了驚人的 800 個,但在電晶體數方面的成長並沒有想像中來得明顯 (實際上這正是上篇我提及 ATI 選擇此種作法的優勢,在 SIMD Array 數量擴編之後就變得很明顯了,可以在不需要大量增加電晶體數量與大幅提高電路複雜度的狀況增加大量的 SMU,而 SMU 又直接影響了運算性能,因此對於 Terascale 架構來說提昇 SMU 的數量是增進效能最直接的路徑。
新的材質單元
RV770 當中材質單元的規劃也有調整,在 RV670 當中 ATI 是採用一組 SIMD Array 對上一組材質單元的配置,而在 RV770 當中也依然如此,因此 RV770 的材質單元數量同樣從六組大幅增加為十組,但最主要的差異其實出現在快取的部分。

以往在 RV670 當中,材質單元之間是沒辦法互相溝通的,每組材質單元對應到一個 SIMD Array,彼此之間並沒有任何管道互聯,但在 RV770 當中除了原先每個 SIMD Array 自有的本地儲存區之外,還增加了一個共用的全域儲存區,SIMD Array 與材質單元可以在那裏交換資料。
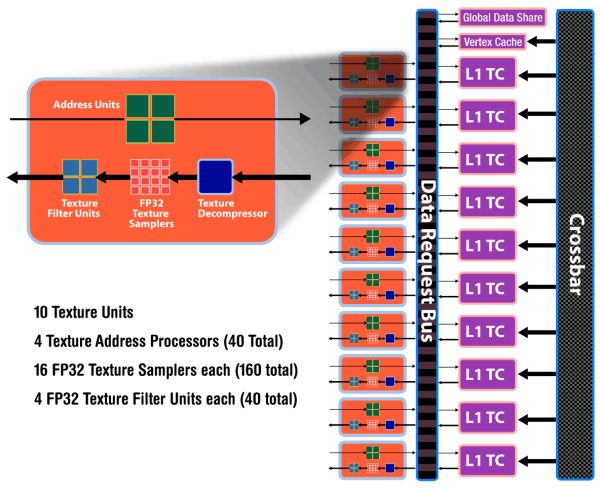
不過值得注意的是在 RV770 當中材質單元的內容被簡化了 (上圖),並且取消了原先的第二層大型共用快取設計 (下圖),改為使用 Crossbar 的方式將每個材質單元的快取記憶體高速相連,這使得新的架構看起來反而跟 NVIDIA 的做法比較相似,儘管在新設計下的單一材質單元本身功能被弱化,但由於數量大幅成長且運作時脈亦有提高,最終的結果反而是性能比前作好上許多。
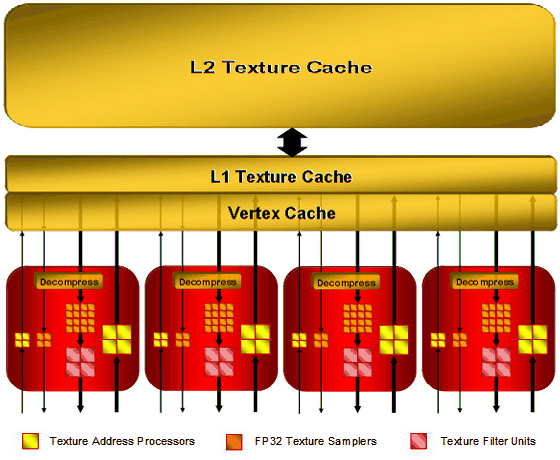
此外,在 RV770 當中材質單元與材質快取之間的連接頻寬也增加了一倍之多。
砍掉重練的記憶體架構
從架構觀點來看 RV770 這一世代改變最大的地方應該就是記憶體階層的規劃方式了,從 R520 開始一路用到 RV670 的環狀記憶體通道整個被砍掉重練,回頭採用了過去比較常用的 Crossbar 架構,將記憶體、L2 快取與 L1 材質快取全部運用中央的 Crossbar 連接在一起,並將原先與 L1 材質快取放在一起的頂點快取整個分離開來,運算單元的部分則使用 Data Request Bus 來與這些記憶體溝通。
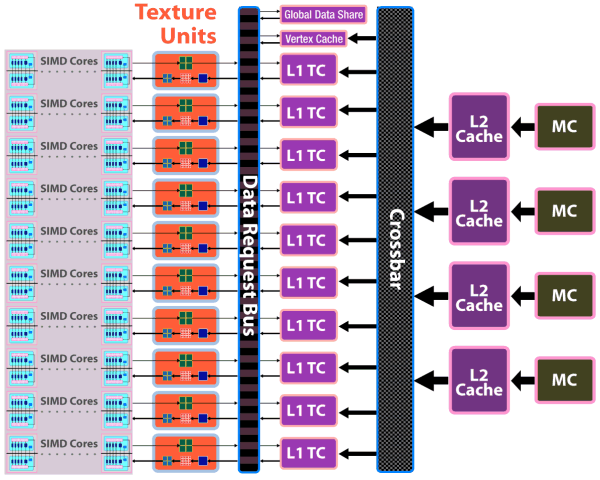
這樣的做法解決了環狀記憶體通道線路過於複雜的問題,讓 AMD 得以把更多空間用於增加更多的 SMU 上,而且 Crossbar 技術也比較成熟。
渲染輸出單元 (ROP)
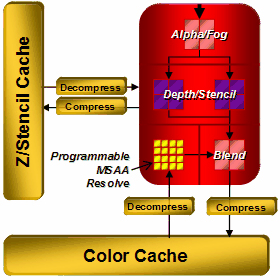
RV770 的 ROP 也獲得了大幅度的性能改進,儘管數量上並沒有增加,但卻透過架構與內部規劃的改進 (負責處理深度與 Stencil 的電路數量加倍,見下圖) 使得在大多數模式下 RV770 的 ROP 性能比起前作要高出兩倍之多,並且可以在不需要 SIMD Array 分擔運算的情況下處理 MSAA 反鋸齒。
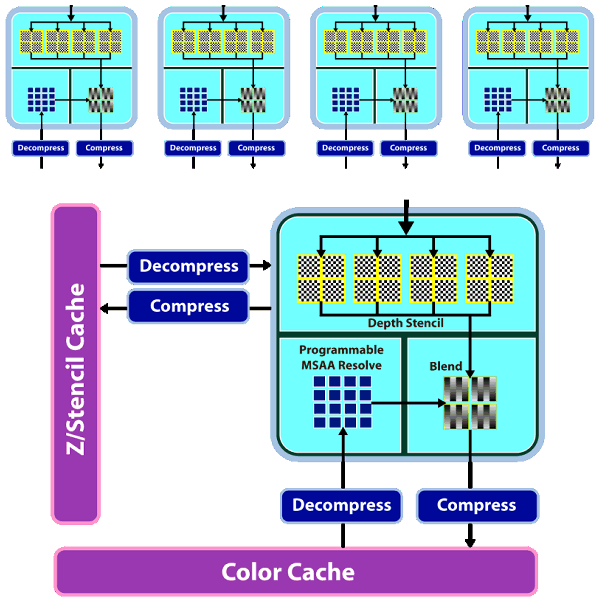
不過新的編制看起來跟 NVIDIA 的做法越來越相似了就是。
搶先導入 GDDR5 支援
關於 RV770 還有一項很重要的改變是加入對 GDDR5 記憶體的支援,實際上這不只是噱頭,也是不得不做的改進。我們剛剛提到 RV770 捨棄了環狀記憶體通道設計與超寬的記憶體頻寬設定 (只剩下 256-bit 了),因此 RV770 在與 RV670 使用相同類型記憶體的狀況下會發生很嚴重的悲劇-記憶體頻寬大幅衰退導致晶片性能無法發輝。
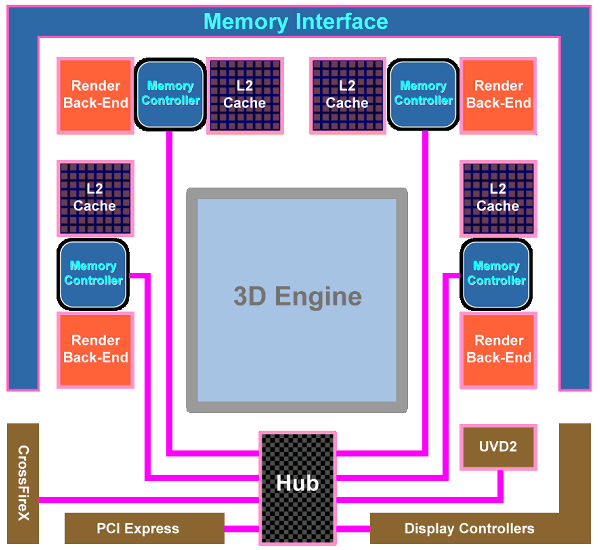
其實這樣的改變並不難理解,當年 R500 靠著環狀記憶體通道與 Ring Stop 大幅提升了理論記憶體頻寬,在 RV770 當中拿掉了這項設計並改回傳統的 Crossbar 設計自然就被打回原形了,但是這對 RV770 來說是一項很大的問題,當時只有還不成熟的 GDDR5 記憶體得以解決這樣的難題, 因此 AMD 下了一次豪賭,幸好在 GDDR4 悲劇之後,功耗更低、時脈與密度卻更高的 GDDR5 最後獲得了巨大的成功。
RV770 核心
由於 R700 系列核心當中並沒有設計大核心 (R700),因此 R700 架構中最為完整的核心就是 RV770 了,包含了 9.6 億個電晶體,與 R600 的 7.2 億來說僅有小幅的成長 (主要的增長來自於大幅增加的 SPU 與 SIMD Array 及材質單元,但在記憶體介面的部分使用的電晶體有大幅度的減少),但由於製程從 80 奈米提高為 55 奈米,因此 RV770 的晶片面積與成本相較於 R600 來說都有了明顯的下降。

RV770 主要面向的是中高階市場,也就是大名鼎鼎的 Radeon HD 4800 系列 (這代當時在追求性價比的玩家市場維持了好一陣子的熱門地位),可分為較高規格的 HD 4870 (這數字相信對買過 AMD 顯示卡的人來說都不陌生)、HD 4850、HD 4830、HD 4810 四款,其中 HD 4870 的運作時脈為 750/900 MHz (搭配 GDDR5 記憶體),HD 4850 則稍降為 625/993 MHz (搭配 GDDR3 或 GDDR4 記憶體),這兩款都具備完整的 800 個 SPU。

至於較低價的 HD 4830 與 HD 4810 則是在隔年才追加的型號,前者的 SPU 數量下降為 640 個 (少了兩排),連帶使得材質單元也跟著少了兩組,運作時脈設定在 575/900 MHz,可支援 GDDR3 或 GDDR4 記憶體;後者則是進一步將渲染輸出單元 (ROP) 與記憶體頻寬的部分砍半,時脈設定則略高一些 (625/900 MHz),可以支援 GDDR5 記憶體。

值得注意的是在隔年 AMD 推出了一款稱為 HD 4730 的中階產品,使用的也是這款 RV770 核心,規格上與 HD 4810 很類似,時脈設定為 700-750 / 900 MHz。

就結果論而言 AMD 在 Radeon HD 4800 系列這一世代獲得了極大的成功,發表當下就迫使 NVIDIA 瞬間大幅下調 GeForce GTX 200 系列產品的售價 (當時 HD 4870 上市的售價為 299 美元,NVIDIA 的 GTX 260 硬是貴上 100 美元,但在性能上卻沒多少優勢可言)。
高階市場的空缺-延續單卡雙晶片策略
因為 R700 這一世代放棄了追逐 NVIDIA 大核心的策略,因此 R700 架構下並沒有真正大規模的核心出現,最強的核心就是 RV770 了,但 AMD 也不可能就這樣完全放棄頂級玩家市場,因此與 RV600 系相仿,AMD 推出了基於兩顆 RV770 核心的雙晶片顯示卡-HD 4870 X2 與 HD 4850 X2。

從 PCB 的規畫可以看到其實 HD 4870 X2 與 HD 4850 X2 的組成模式跟上一世代的 HD 3870 X2、HD 3850 X2 很類似,同樣都是使用單卡雙晶片,並且由中央的 PLX 橋接晶片負責串起這兩顆 GPU,而在規格的部分則是完全照搬原本 HD 4870 與 HD 4850 的設定,沒有像上一代出現雙晶片版本反而比單晶片版本高的情況。

從 HD 4870 X2 與 HD 4850 X2 上我們可以很容易觀察到傳統大核心策略與 AMD 的雙晶片策略有甚麼樣的優缺點與得失,舉例來說採用雙晶片的優點有下面這些:
- 小核心相對於大核心而言可以大幅降低開發的困難度 (NVIDIA 也說過造大核心很難)
- 相對於大核心來說小核心的良率提高容易很多
- 開發難度下降意味著準時上市的機率提高 (AMD 應該受夠延期了)
- 良率提高意味著生產成本的降低 (兩顆 RV770 的生產成本很可能還不及一顆 GT200)
但是這樣做法的缺點其實也很明顯 (這可能是 NVIDIA 繼續堅守大核心戰略的考量):
- CrossFire 與 SLI 等多顯示卡技術都未必能夠在所有遊戲發揮作用了,甚至在某些時候性能比單卡還差,儘管對於單卡雙晶片來說距離較短因此延遲的狀況好很多,但要讓兩顆 GPU 能後相輔相成仍然是很大的挑戰,未必會比設計大核心簡單。
- 單卡雙晶片意味著龐大的供電需求,供電模組方面的成本也會因此提高。
- 單卡雙晶片電路設計複雜,可靠度也可能會是個問題。
Table of Contents
RV790 核心
接下來要講的是與 RV770 核心非常類似的 RV790 核心,基本上是為了因應 NVIDIA 推出性能介於 GTX 260 與 GTX 280 之間的 GTX 275 而設計的,定位上比 RV770 還要略高一點,是 R700 架構的終極產品。

RV790 的規格參數與 RV770 幾乎是一模一樣的,不過 AMD 為了讓 RV790 得以在比 RV770 更高的時脈穩定運作,因此對電路進行了不少的優化,並且加入許多用於降低雜訊與電路干擾影響的電容器,這使得 RV790 的電晶體數量比起 RV770 來說多了三百萬個。

從上表當中也可以看出 RV790 的性能提升基本上來自於時脈大幅提升了 100 MHz,由於僅是基於策略而設計的產品,且良率及成本都偏高,因此採用 RV790 核心的型號僅有 HD 4890 (850/975 MHz) 與 HD 4860 (700/750 MHz) 兩款,值得注意的是後者的核心配置和 HD 4830 一樣被大幅閹割過,因此配置上是輸給 HD 4850 的。
RV730 核心
在中階產品的部分 AMD 則是推出了 RV730 核心,也就是大名鼎鼎的 HD 4600 系列,僅包含 320 個 SPU,不過值得慶幸的是 AMD 選擇的砍法是把 SIMD Array 的長度砍半而不是數量砍半,因此材質單元的部分沒有被砍太多,仍然有八組之多,但渲染輸出單元的數量則是直接減半,記憶體頻寬的部分也只有 128-bit。

即便相較於 RV770 來說可說是砍了超級大的一刀,但低廉的價格與可接受的性能使得這系列 GPU 在當時的裝機界可說是叱吒風雲。

HD 4600 系列有兩個成員,分別是較高階的 HD 4670 (如果玩電腦的資歷夠久應該對這型號多少會有些印象) 與 HD 4650,前者時脈設定為 750 MHz,可以搭配 GDDR4、GDDR3 與 DDR2 三種記憶體使用 (所以其實當時市場蠻亂的,也出現不少店家刻意誤導消費者的情況),後者的時脈則是僅有 600 ~ 650 MHz,同樣有 GDDR4、GDDR3 與 DDR2 三種版本在市面上流通,但 HD 4850 魚目混珠的情況更嚴重,因為較差的 HD 4850 記憶體頻寬進一步被砍到只剩下 64-bit。

RV740 核心
AMD 後來在 RV730 與 RV770 之間追加推出了這款同樣定位於中階市場的 RV740 核心,相較於 RV770 來說,RV740 主要是 SIMD Array 的部分被閹割為只留下 640 個 SP,材質單元的部分也只剩下 8 組,不過渲染輸出單元則沒有調整,值得注意的是 RV740 是 AMD 第一款基於 40 奈米製造工藝的圖形處理器。
RV740 同樣有兩個型號 HD 4770 與 HD 4750,均屬於 HD 4700 系列,不過這系列比較不像 HD 4600 與 HD 4800 系列那麼為人所知,這兩個型號僅有時脈差異 (前者 750/800 MHz,後者 730/800 MHz)。

RV710 核心
在低階入門市場的部分 AMD 則是準備了 RV710 核心應戰,不過由於砍得過於徹底因此在性能表現上不甚良好,在市面上也沒有引發太大的迴響 (要我說的話,其實已經砍到看不太出 RV770 的形狀了)。
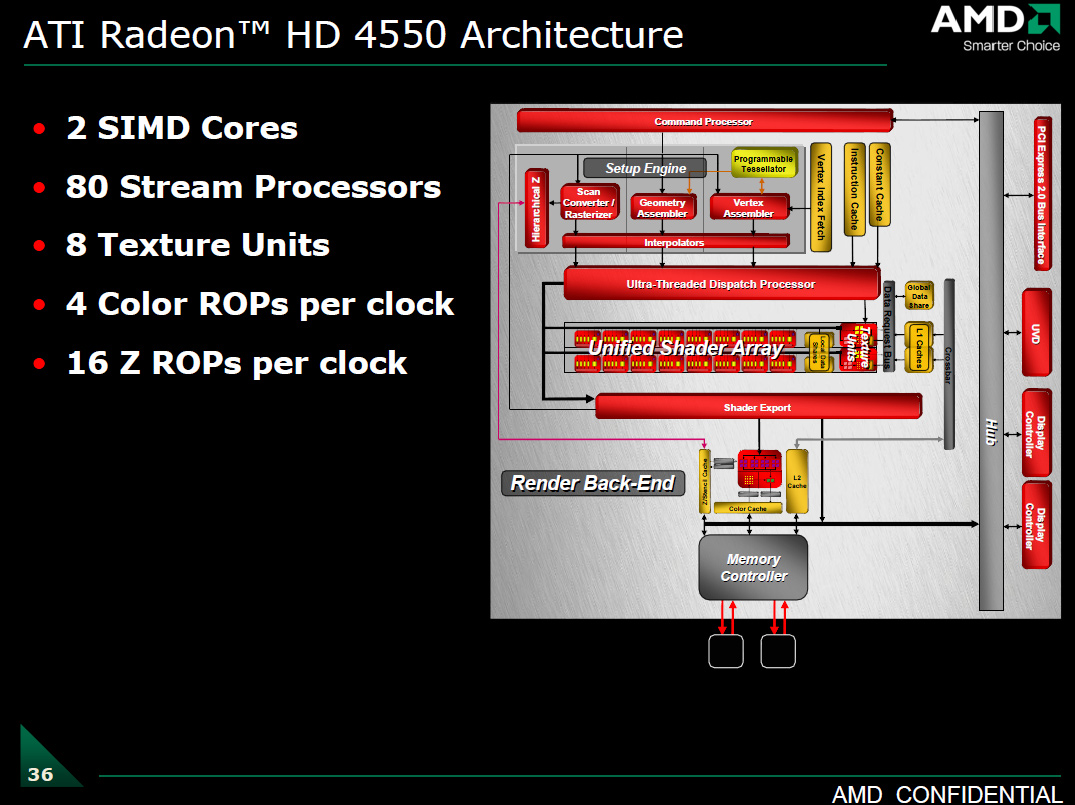
如同上面這張慘烈的架構圖所顯示的,RV710 的記憶體控制器只剩一組 (因此只有 64-bit 頻寬),渲染輸出單元也只有一組,負責主要運算的 SIMD Array 只剩兩條減半長度的版本 (所以連帶的材質處理單元也只剩兩組了),頂點快取記憶體也被取消。

基於 RV710 和新的產品一共有 HD 4570 (650/500 MHz + DDR2)、HD 4550 (600/655 MHz + DDR2 或 600/800 MHz + GDDR3)、HD 4530 (600/400 MHz + DDR2) 三款,均有 Low Profile 版本與 AGP 版本推出,適合小型主機安裝。