

NVIDIA 陣營在 Kepler 架構之後負責接檔的是 Maxwell 架構,由於 Maxwell 架構本身的改進方向與架構設計跟 Kepler 架構的相似度其實還蠻高的,所以接下來我打算就直接接著講 Maxwell 架構。
或許你會好奇為什麼我不像之前那樣先講 DirectX 12.0,其實是因為 DirectX 12.0 基本上沒有帶來太多架構上的改變,相較於 DirectX 11.x 來說其實 DirectX 12.0 主要的改進內容只是針對多執行緒運算方面進行大量的優化工作,因此原有的 DirectX 11.x GPU 只需要更新驅動程式與應用程式就可以支援 DirectX 12.0 帶來的絕大多數新特性,所以沒有太多值得額外介紹的內容 (當然這不代表 DirectX 12.0 沒甚麼重要改進,只是大多數是演算法優化,跟硬體沒甚麼關係而已),而且 NVIDIA 也沒有在 Maxwell 架構硬體中實作那些功能,因此不會在本篇提及。
NVIDIA Maxwell Microarchitecture (第一代)
- 推出日期:2014 年 02 月 (GM107)
- 所屬系列編成:GeForce 700 系列、GeForce 900 系列
- API 支援:DirectX 12.0、OpenGL 4.5、OpenCL 1.2、Vulkan 1.0
- Shader Model 支援:SM 5.0
上回我們提到 Kepler 架構是 NVIDIA 由一味追求規模、性能提升轉為強調效率提升為主要策略的開始,而 Maxwell 這一世代實質上就是以 Kepler 架構為基礎繼續往這個方向發展之下的產物,因此在架構本質上與 Kepler 架構之間的差異其實並不是很大,反而最明顯的差異只有內部元件組織被打散重新排列組合而已。
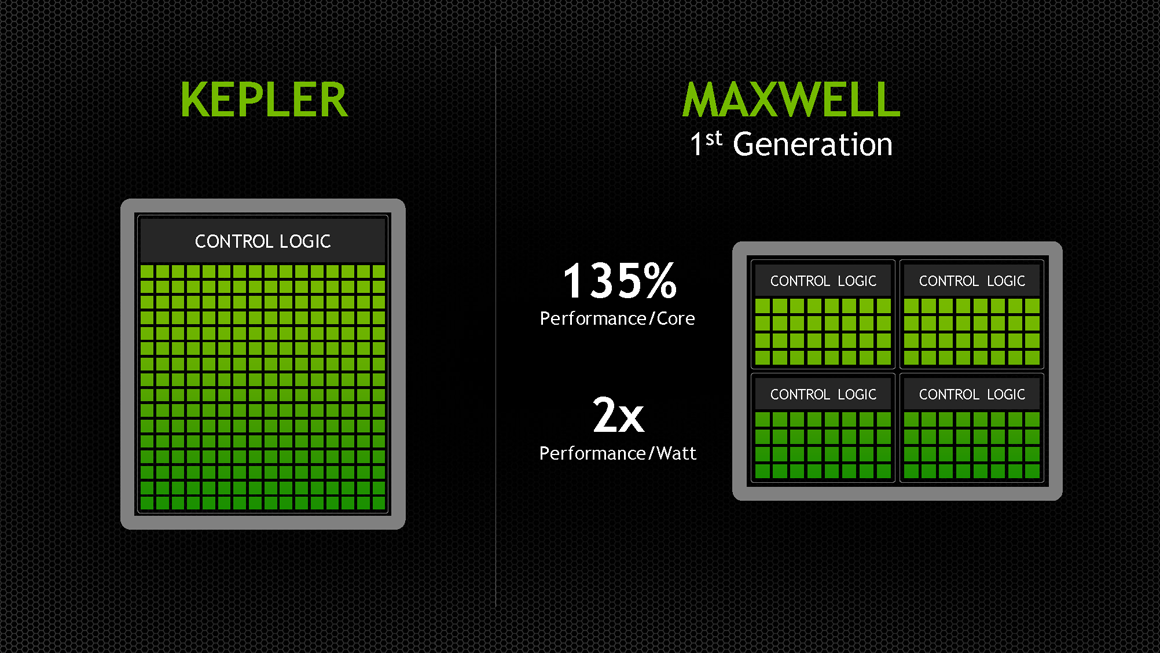
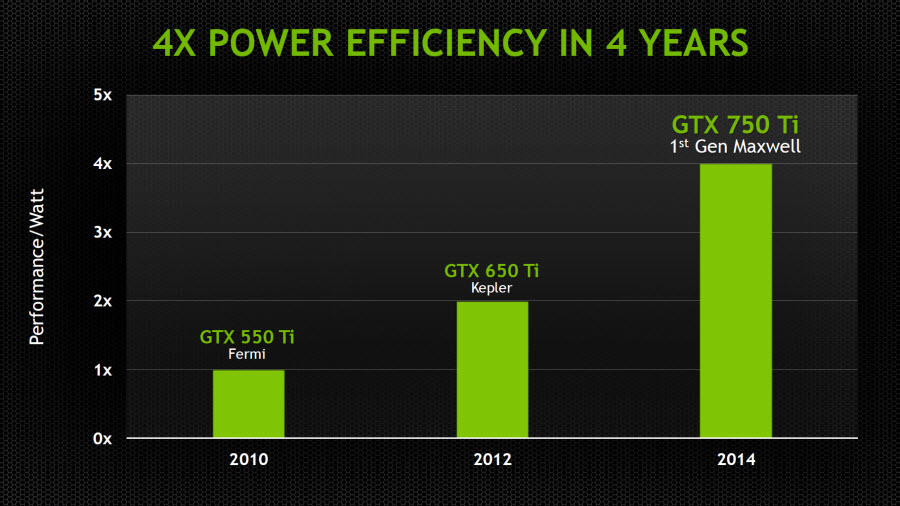
然而這正是 Maxwell 架構最有意思的地方,只是重新排列組合而已居然能讓每瓦效率直接翻倍 (Maxwell 與 Kepler 一樣都是基於 28 奈米製程,所以效率提升並不是來自於製程改進,而是 100% 純正的架構效率提升)。
打散重排的 SMX 配置
聽起來好像不太科學,究竟 NVIDIA 到底是怎麼做到的?要深入探討之前我們得從上一代 Kepler 架構的排列方式開始談起,下圖就是 Kepler 架構核心中的分組單位-SMX 的組成圖:
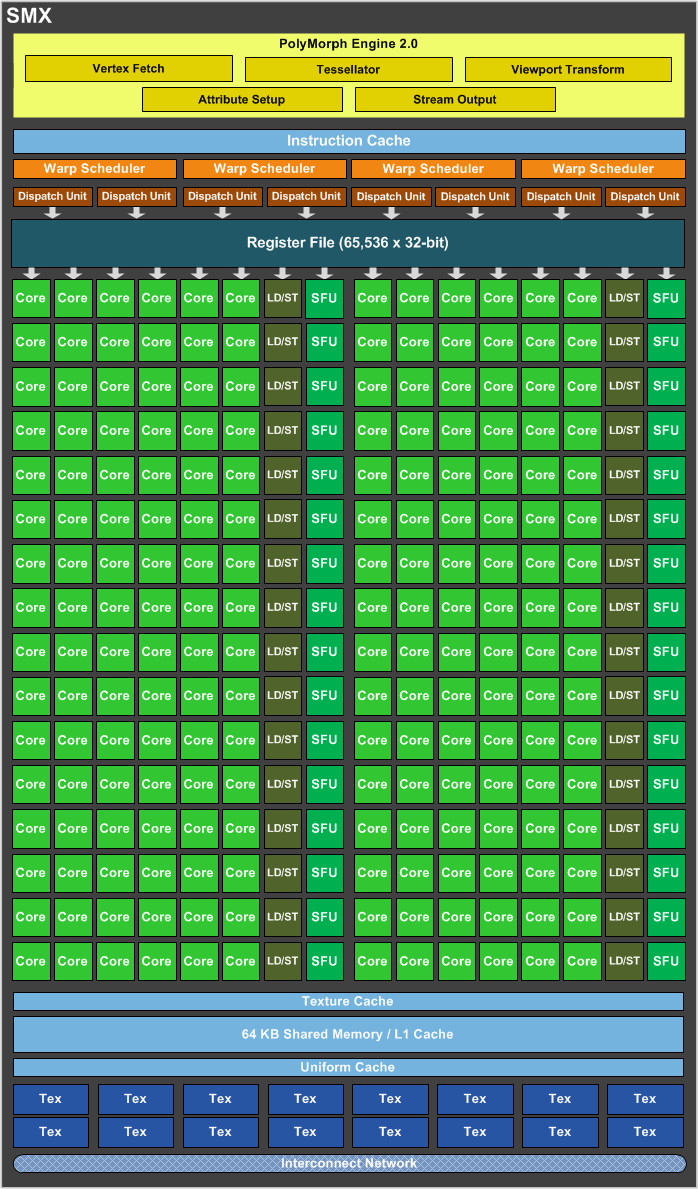
基本上 NVIDIA GPU 架構內的基本組成-SMM (或是 Tesla / Fermi 時代的 SM) 大抵上可分為三個組成部分:控制電路 (指令快取、Warp Scheduler 等)、運算單元 (CUDA Core、FP Unit、SFU、LD/ST) 與材質渲染 (底下的 Tex 材質單元)。先前曾經談過 Kepler 架構的性能提升主要來自於 CUDA Core 的配置數量大幅提升 (從每組 SM 32 或 48 個大幅提高到每組 SMM 192 個),但是單一 SMM 模組內的 CUDA Core 數量大幅提升就意味著每個 CUDA Core 所能分配到的控制電路與材質渲染資源也就相對大幅減少了,沒錯吧?
然而除了平均分配的資源減少之外,在實際運作中軟體也不一定能很理想的餵飽共用的控制電路,讓控制電路得以讓所有 CUDA Core 同時都有工作可以處理 (畢竟每個指令被丟進控制電路內的時間不一定剛好對上,而指令被分配到 CUDA Core 上的情形也很難預測),且在共用控制電路設計中,很難讓控制電路根據 GPU 使用率進行高效率的動態啟閉,這兩個問題很大程度的影響了 Kepler 架構在實際運作下的效率,因此解決這三個問題就成為 Maxwell 架構發展上最重要的課題了。
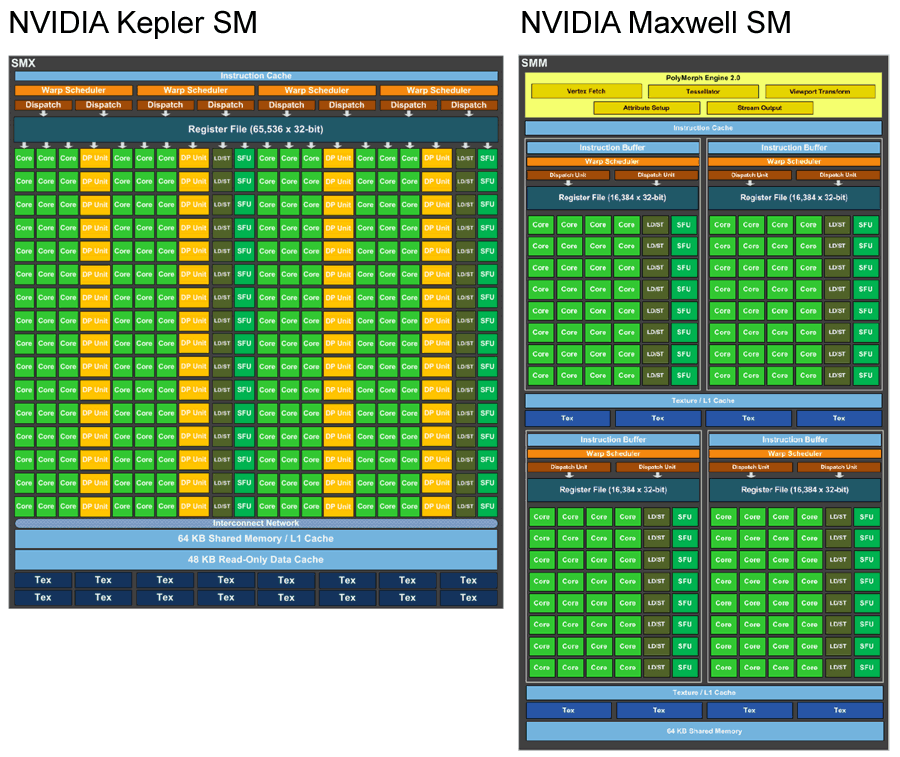
而實際上 NVIDIA 是怎麼做的呢?基本的思維是將 Kepler 的 SMM 內部再切割為 4 小塊,每一小塊各自擁有自己的指令緩衝區、排程器、Register File 等控制電路 (每小塊各自擁有 1/4,總規模實際上與 Kepler 是一樣的),並以 2 小塊為一組享有各自獨立的 L1 與材質快取、材質單元,最後這 4 小塊再以 64 KB 的共享記憶體作為彼此溝通的管道。

在這樣的設計之下四小塊各自擁有的控制電路得以不互相影響獨立運作,因此可以大幅提升 CUDA Core 資源的利用率,L1 與材質快取合併之後快取命中率也得以提高,共享記憶體所承擔的工作也變得更加單純,總和下來帶來的改善就是非滿載情形下的資料吞吐量與運算核心利用效率的大幅提高,當然性能與效率也就隨之提升了。
不過這樣的設計當然也有缺點,那就是在滿載情況底下的性能會略為減損,不過實務上會滿載的情況並不是那麼多,而減損的性能其實也並不是非常多,但卻能得到大幅簡化連結指令分派單元與運算單元之間的 Crossbar 電路來達到省電與降低控制電路所需晶片面積的效果,因此整體換算下來還是划算的 (而根據 NVIDIA 的官方說法,NVIDIA 也有做一些改進來提升每個 CUDA Core 的效率,因此一來一往最後性能還是提升了不少)。
除此之外要特別提及的是 Maxwell 內的 SMX (即相當於 Kepler 當中 SMM) 當中的雙精度浮點運算單元只有 4 個 (即 Kepler 的一半,因此 Maxwell 架構的雙精度浮點性能只有單精度浮點性能的 1/32),CUDA Core 的數量也從 192 個調降為 128 個。
快取大幅提高,記憶體頻寬縮減
另一項 Maxwell 架構的改進重點則是出現在記憶體佈局上,NVIDIA 在 Maxwell 架構當中把 L2 快取的容量從原來的 256 KB 大幅提高到 2 MB (以 GK107 與 GM107 比較的情形),讓快取可以容納更多的資料從而減少需要存取記憶體的頻率,最終達到降低記憶體頻寬需求的效果。
在記憶體頻寬需求下降之後 NVIDIA 便得以減少 Maxwell 架構當中配置的記憶體控制器數量,從而達到降低晶片面積與耗電量的效果。
That’s all…?
實質上第一代 Maxwell 在架構上的修改真的就只有 SMX 打散重排、快取增加跟記憶體通道寬度縮減 (本來我想用改進這詞,不過記憶體通道縮減好像不算改進 XD) 而已,除此之外就是一些 H.264 部分支援之類的小東西,不要懷疑,真的就只有這樣,實際上 Maxwell 架構大部分的特色 (像是動態超級解析度、第三代色彩差異壓縮等) 都要等到後續的第二代 Maxwell 架構才會出現,而當年 NVIDIA 在 Roadmap 上標註 Maxwell 架構將有的主要特色-Unified Virtual Memory 實質上後來也沒有加入第二代 Maxwell 之中,而是要等到 Pascal 才會出現。
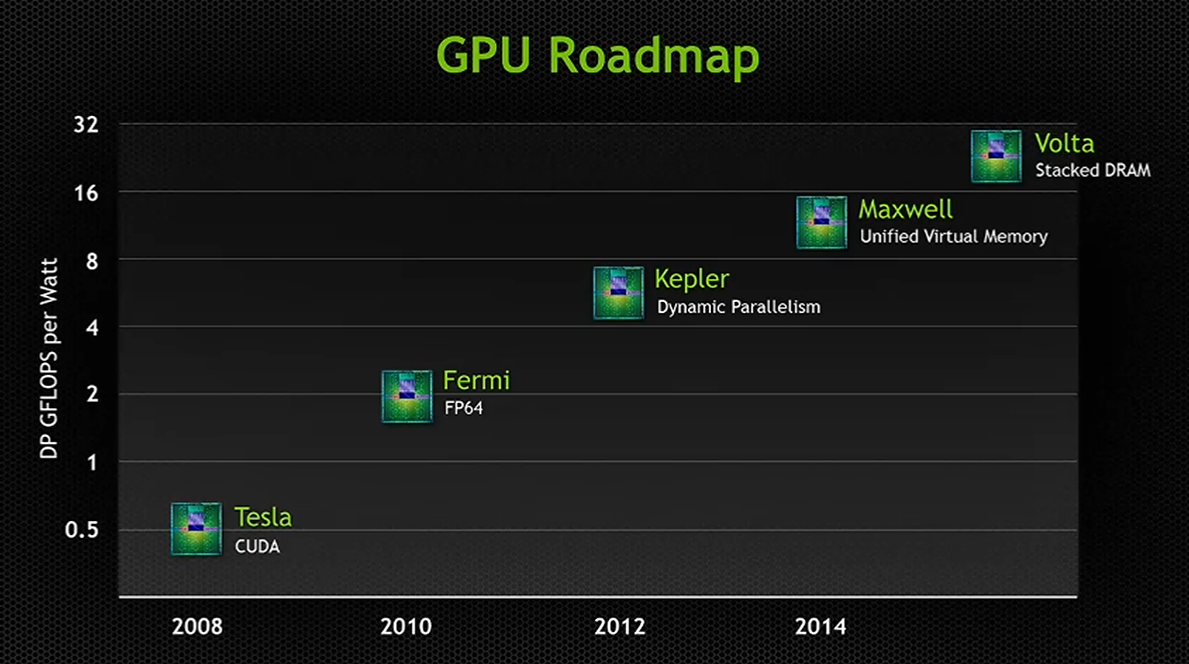
Table of Contents
GM107 核心
使用第一代 Maxwell 架構的核心種類很少,只有 GM107 與 GM108 (主要用於筆記型電腦) 兩種而已,從代號當中可以很明顯的看出來這兩款顯然都不會是高階產品,更不可能是頂級的大核心系列,實際上也確實是這樣,這兩款正好是 Maxwell 家族當中核心規模最小的兩款。

以 NVIDIA 過去的歷史來說,全新一代的架構居然是用最小的核心起頭看起來的確很奇怪,而且改進內容又這麼少,這在當年也確實引起不少媒體紛紛議論 NVIDIA 到底葫蘆裡在賣甚麼藥 (其實說穿了就是大核心版本的 Maxwell 跟當年 Kepler 一樣又難產了,頂級產品一年一改的慣例差點生不出來,最後只好出個基於完整版 GK110 的 GTX TITAN Black 跟 GTX TITAN Z 來撐場,而且當時 Kepler 也還沒在低階入門產品出現,最終造就了只有中階是 Maxwell,其他各價格帶的新產品都是 Kepler 的情況)。
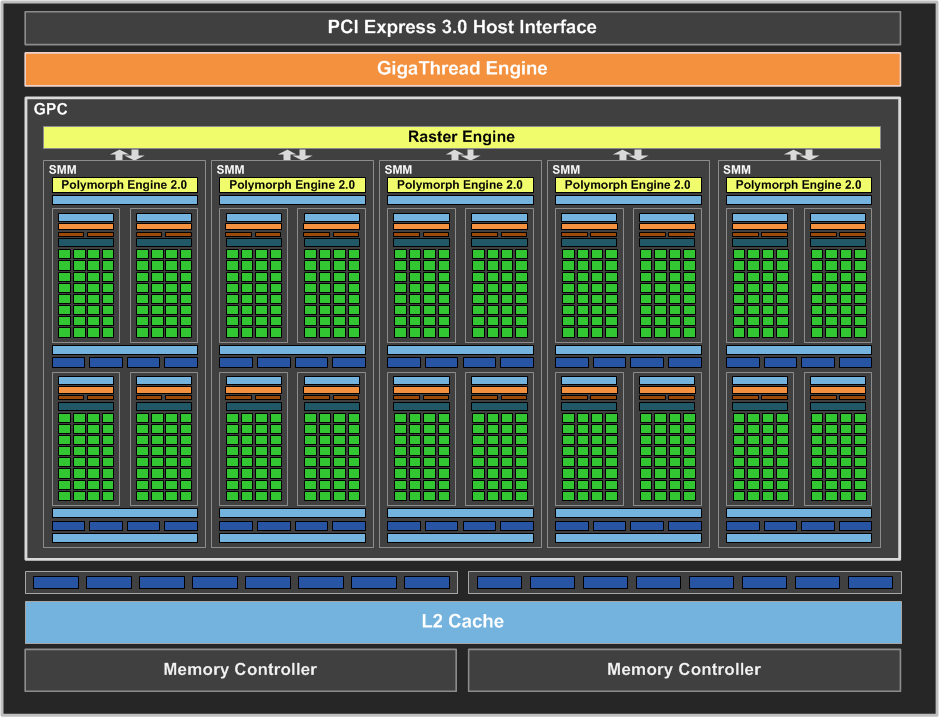
由於屬於中低階產品,所以 GM107 的結構相對而言簡單許多,只有兩組記憶體控制器 (128-bit 頻寬) 與一組 GPC,其中包含了 5 組 SMM (即 640 個 CUDA Core、40 個 TMU、16 個 ROP),而使用 GM107 核心的產品則只有三款。

其中定位最高的為 GTX 750 Ti (1020 MHz / 5400 MHz),是系列當中唯一使用完整版 GM107 核心的型號,次一級的 GTX 750 (1020 MHz / 5000 MHz) 則是刪減了一組 SMM,因此僅具備 512 個 CUDA Core、32 組 TMU,而僅用於 OEM 市場的 GTX 745 (1033 MHz / 1800 MHz) 則是只包含 3 組 SMM (384 個 CUDA Core、24 組 TMU),並且只能搭配 DDR3 記憶體使用。
GM108 核心
至於 GM108 核心則是 Maxwell 架構當中規模最小的,在 GM107 的基礎上進一步刪除了一組記憶體控制器,並且最多只包含 3 組 SMM,主要只用於筆記型電腦上,因此在此就不多贅述。
NVIDIA Maxwell Microarchitecture (第二代)
- 推出日期:2014 年 09 月 (GM204)
- 所屬系列編成:GeForce 900 系列
- API 支援:DirectX 12.0、OpenGL 4.5、OpenCL 1.2、Vulkan 1.0
- Shader Model 支援:SM 5.0
在首款 Maxwell 架構核心推出之後半年,NVIDIA 才終於揭開 Maxwell 架構的真實面目,實際上有不少 Maxwell 架構的新特性都要在第二代 Maxwell 架構當中才看得到 (不過這次跟 Kepler 時期一樣,仍然是從中核心開始首發,完整版大核心還要再等一陣子)。
跳過 GeForce 800 系列的理由
在開始談第二代 Maxwell 架構之前,應該有些人有這個疑問吧?照例作為 GeForce 700 系列接班人的產品線應該叫做 GeForce 800 系列才是,但最後卻直接跳到 GeForce 900 系列了,實際上這是 NVIDIA 考慮到過去幾代產品線當中「架構跨越系列」的情況越來越嚴重 (舉例來說 700 系列當中同時有 Fermi、Kepler 一代、Kepler 二代甚至 Maxwell 一代的產品,而 Kepler 一代的產品散見於 GeForce 600 系列與 GeForce 700 系列) 而做出的改變。
不過真正讓 NVIDIA 下定決心做此改變的理由倒不是桌上型電腦用 GPU 這邊的混亂,其實是筆記型電腦的部分才讓 NVIDIA 下此決定,主因為當時 GeForce 800M 系列已經先推出,而當中採用 Maxwell架構的核心全都比 Kepler 架構核心低階,或許是為了避免讓人以為 Maxwell 是低價版 Kepler 才做此決定。
第三代色彩差異壓縮技術
前面提過 Maxwell 架構為了降低對記憶體頻寬的需求 (目的是減少記憶體控制器配置來節省面積與功耗),所以把快取加大了許多,然而這在放大規模之後的第二代 Maxwell 架構當中仍然是不夠的 (而且第二代 Maxwell 架構當中渲染輸出單元對比記憶體控制器的數量變得更加懸殊了,因此頻寬不足的問題會變得明顯許多,Tesla 時代每個記憶體控制器平均只需要負責 4 個 ROP,發展到第二代 Maxwell 的時候每個記憶體控制器得負責 16 個,這是第一代 Maxwell 的兩倍),因此 NVIDIA 在第二代 Maxwell 架構當中把已經許久沒有更新的色彩差異壓縮技術提升到第三代。

最早的色彩壓縮可以追溯到 GeForce FX 時期 (對,就是惡名昭彰的 FX),而 Maxwell 當中的第三代色彩差異壓縮則是演化自 Fermi 架構當中首次提出的色彩差異壓縮技術 (Fermi 架構是 NVIDIA 第一款把 ROP 與記憶體控制器比值拉到 8:1 的產品)。
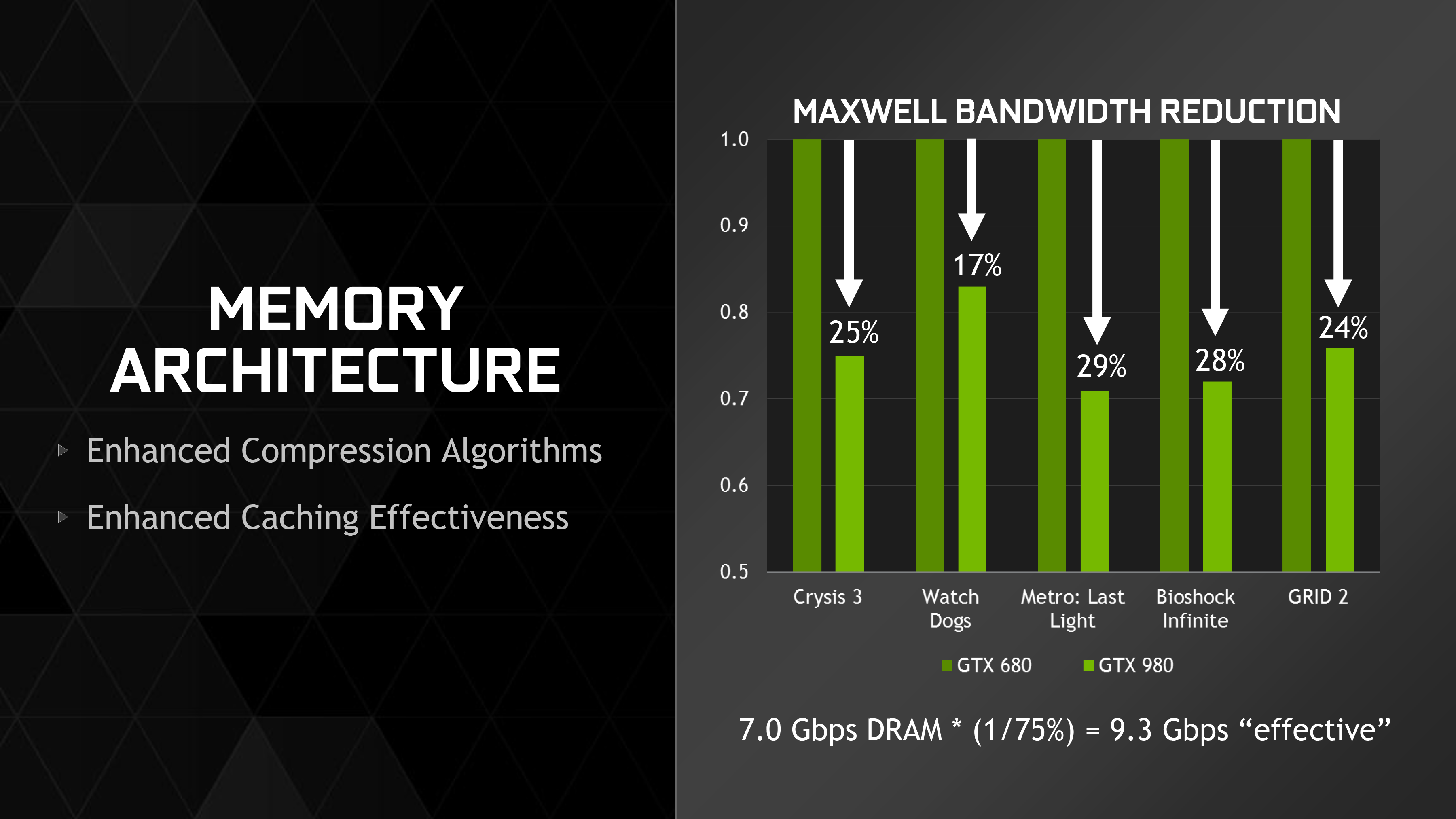
畢竟本系列文章的主軸不在於深入探究原理,而是在介紹歷代發展與各種技術,因此色彩壓縮方面的細節我就不多談了。就結果而言,得益於色彩壓縮技術的提升與擴大 L2 快取之後,NVIDIA 官方聲稱平均而言能夠降低 25% 的記憶體頻寬需求。
HDMI 2.0 與第三代 NVENC
相較於第一代 Maxwell 架構而言,基於第二代 Maxwell 架構的系列產品全數支援 HDMI 2.0 輸出 (可以完整支援 60 Hz 畫面更新頻率下的 4K 解析度輸出),內建硬體編碼器 NVENC 則改進了 H.264 編碼的性能與增加對 H.265 HEVC 編碼的支援。
Polymorph Engine 3.0
除此之外第二代 Maxwell 也補上了第三代的 Polymorph Engine,與先前版本的主要差別是一些架構上的優化。

如同先前提過的,這部分主要影響的是進行曲面細分 (Tessellation) 的性能,因此第二代 Maxwell 架構在這方面也有一些提升。
Dynamic Super Resoultion (DSR)
另一項第二代 Maxwell 架構的重點特色則是動態超級解析度技術 (這項功能在不少 GeForce 900 系列顯示卡的外盒上都有印圖案,不過並沒有特別說明是甚麼用途)。

這項功能的原理基本上是讓顯示卡渲染比實際螢幕所支援的解析度還要高解析度的畫面,之後再運用 13 階高斯濾鏡重新取樣回螢幕所能支援的解析度進行輸出,最終可以達到減少鋸齒與提升畫面清晰度的效果。

如果你有用過前幾年流行過一陣的數位相機的話 (雖說幾乎要被智慧型手機取代了),概念上有一點像數位相機當中的插補點技術反過來用的情況 (當年數位相機經常明明只用上 300 萬畫素鏡頭卻宣稱可以拍出 500 萬畫素的照片,多出來那 200 萬畫素其實就是以軟體用「猜相近顏色」的方式補出來的。

Real-Time-Voxel-Global Illumination (VXGI)
對於 3D 圖形來說,最根本的組成就是像素、材質貼圖與照明這三件事情了,而即時立體像素全域照明 (VXGI) 的存在目的就是為了進一步提高目前 GPU 在做照明 (對立體物件打光) 時候的逼真程度而發展的 (主要是針對場景內的反射光、漫射光、鏡射光三種間接光源的模擬能力進行強化)。

不過這項技術並非只能在第二代 Maxwell 架構當中取用,但在第二代 Maxwell 架構的核心上會額外具備硬體加速的能力。

GM204 核心
看完第二代 Maxwell 架構的主要特性之後,接下來要介紹的是第一款基於第二代 Maxwell 架構的核心-GM204,從代號上我們可以很容易得知這並不是完整版本的大核心,而是與 Kepler 時期首發產品類似的中型核心。

GM204 核心本身由 4 組 GPC 組成,不同於第一代 Maxwell 架構當中每組 GPC 內可以有五組 SMM 的設置,在第二代 Maxwell 架構當中每組 GPC 內至多只能包含 4 組 SMM (即 512 個 CUDA Core),至於記憶體頻寬的部分,即便 GM204 宣稱有兩倍於 GK104 的性能,GM204 的記憶體控制器規格仍維持與 GK104 相同 (即 4 組合計 256-bit 通道寬度),主要靠記憶體壓縮改良與快取提昇來彌補額外的頻寬需求。
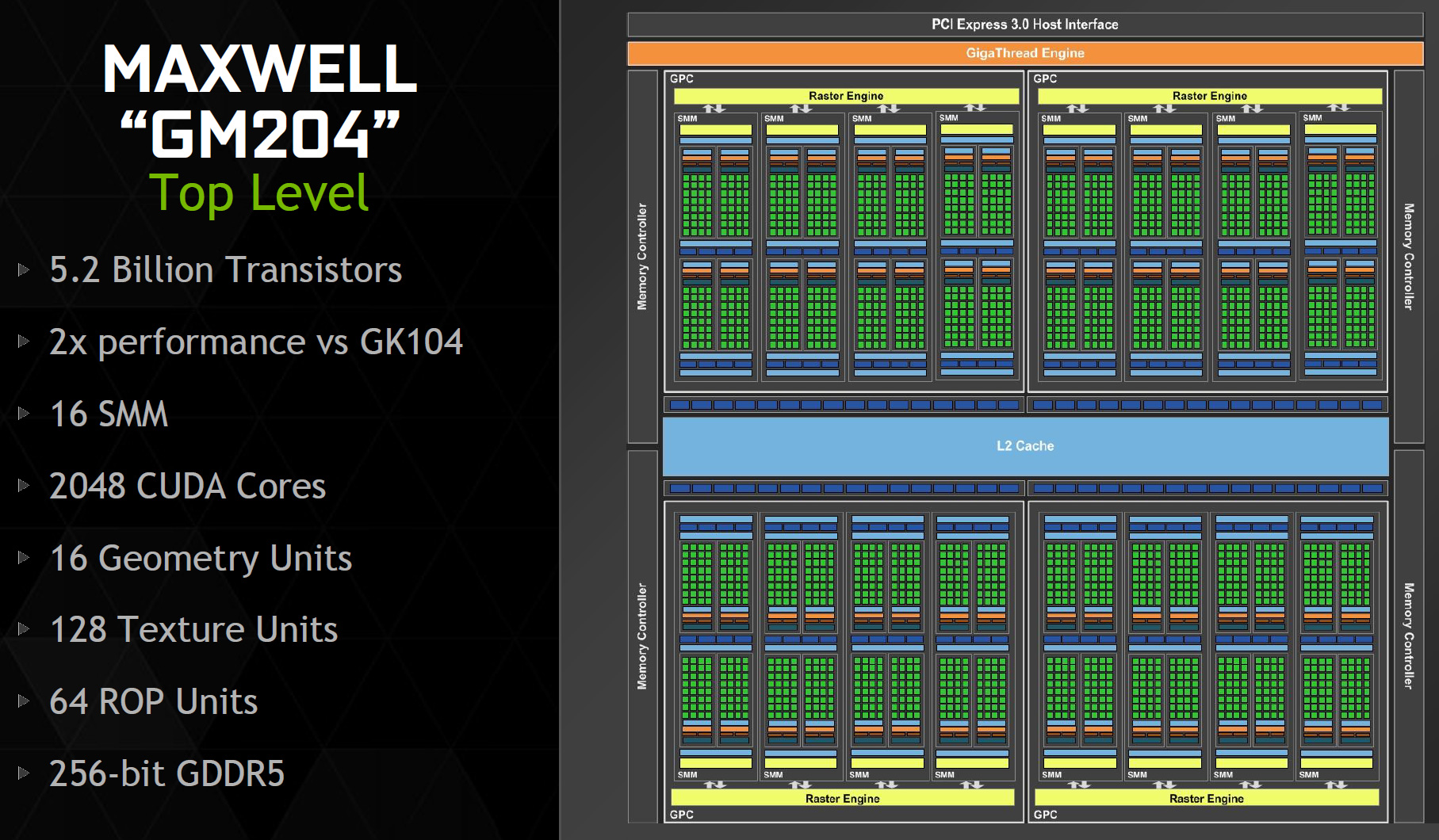
基於 GM204 核心的產品主要有兩款,其中定位較高的是 GTX 980 (1126 MHz / 7010 MHz),採用完整版 GM204 核心,具備 2,048 個 CUDA Core、128 組 TMU、64 組 ROP 與 4 組記憶體控制器 (合計頻寬 256-bit)。

而定位較低的則是 GTX 970 (1050 MHz / 7010 MHz),相較於 GTX 980 而言被砍了 3 組 SMM,因此 CUDA Core 數量只剩下 1,664 個,TMU 與 ROP 的數量也分別減少為 104 組、56 組,而這兩款顯示卡的記憶體標配都是 4 GB。
GTX 970 記憶體頻寬事件
而談到 GTX 970 就不得不提先前曾經在網路上引發喧然大波的 3.5 GB 事件與快取、ROP 規格錯標事件 (特別是在美國引起了非常大的討論熱潮,甚至有使用者聯合控告 NVIDIA 謊報規格,台灣也有一些連署要求 NVIDIA 接受退貨、拒買的運動出現)。
據 NVIDIA 官方的說法,這是它們公司內部研發部門與行銷部門之間溝通出了問題導致的結果,依照 NVIDIA 的聲明是他們本來設計 GTX 970 的時候照規格應該只給 3 GB 的記憶體,然而站長個人認為最大的問題是出在 NVIDIA 當初在提供 GTX 970 規格表的時候把 ROP 的數量與 L2 快取的大小都給寫錯了。
一開始 NVIDIA 給的規格表是表示 GTX 970 並沒有刪減 ROP 與 L2 快取,而且當時 NVIDIA 並沒有針對 GTX 970 提出符合的配置圖 (你所能找到的 GM204 配置圖都是 GTX 980 的),又加上 GTX 970 也配了 4 GB 的記憶體,而且以往要砍 ROP、記憶體控制器與 L2 快取時這兩邊會有連動關係,所以大家預期 GTX 970 與 GTX 980 在記憶體階層的部分應該是一模一樣的。
不過後來陸續有用戶在使用 GTX 970 時發現,當執行大量消耗顯示卡記憶體的工作時,GTX 970 只能使用約 3.5 GB 的記憶體,後來陸續執行測試軟體也發現特意只存取最後 512 MB 記憶體時的記憶體頻寬大約只有 GTX 980 的 1/7 (其他部分也只有 GTX 980 的 7/8),並把結果貼上網路之後才引爆了整個討論。
眼看事情越演越烈,最後 NVIDIA 不得不回應表示它們提供給媒體的規格表出了一點差錯,實際上 GTX 970 的 L2 快取只有 1.75 MB,ROP 也只有 56 組,這一切其實是肇因於 Maxwell 架構當中引入的一項新特性,使得 NVIDIA 得以「部分關閉」ROP 與記憶體控制器分區 (GM204 有四個 ROP 與記憶體控制器分區,對應到四個 GPC,而 GTX 970 上有「半組」被關閉了),而不再像以前只能成對關閉。
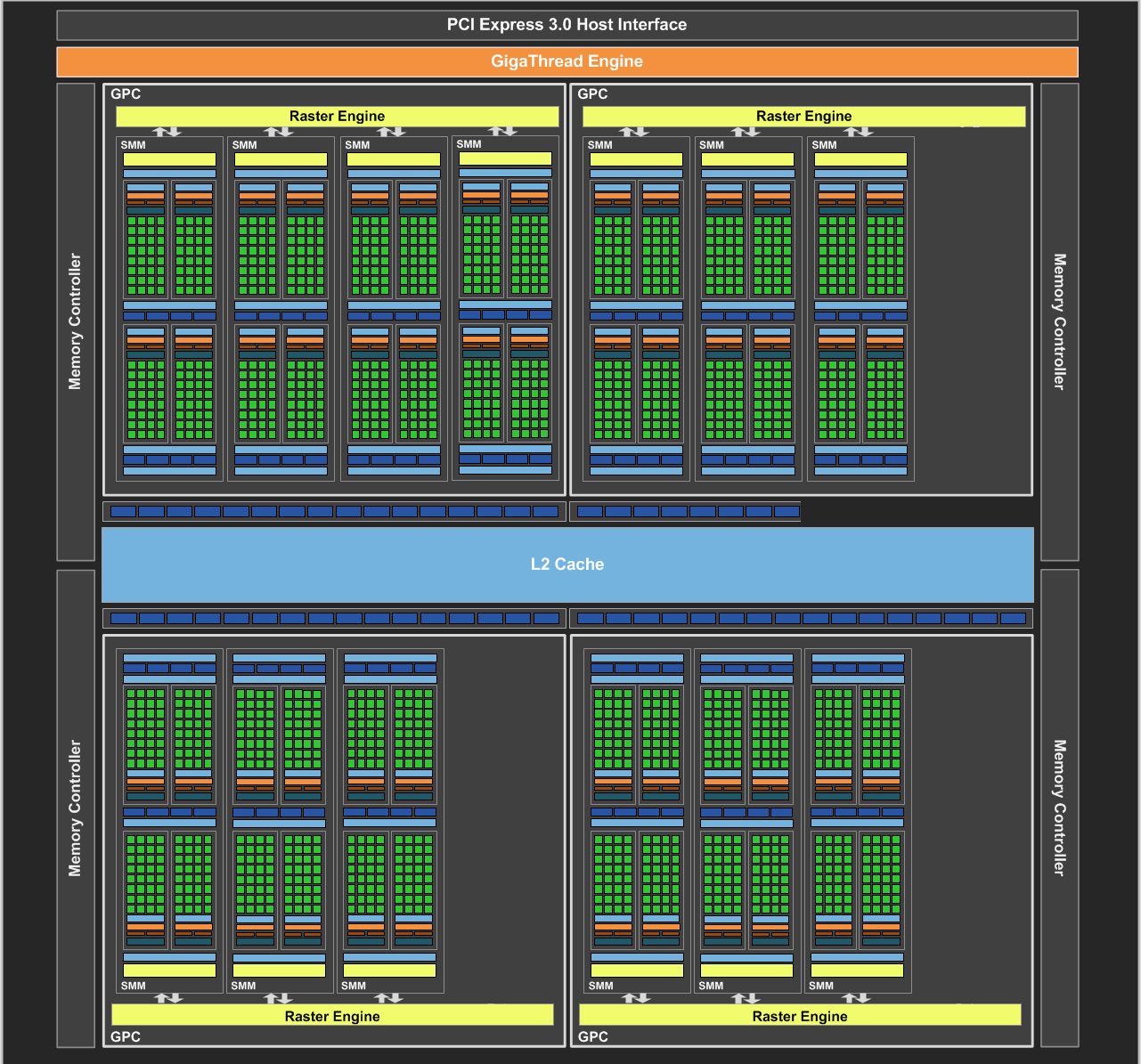
這解釋了為什麼 GTX 970 會出現這種奇怪的現象,其實和當年 GTX 660 與 GTX 660 Ti 的狀況很相似,這問題是肇因於 ROP 與記憶體控制器之間數量上沒有完全平衡對應的結果,導致記憶體被迫分割為兩塊 (以 GTX 970 的情況來說就是 3.5 GB + 0.5 GB),而且這兩塊不能同時存取,至於詳細的情況,使用下面這張圖說明會比較易懂。
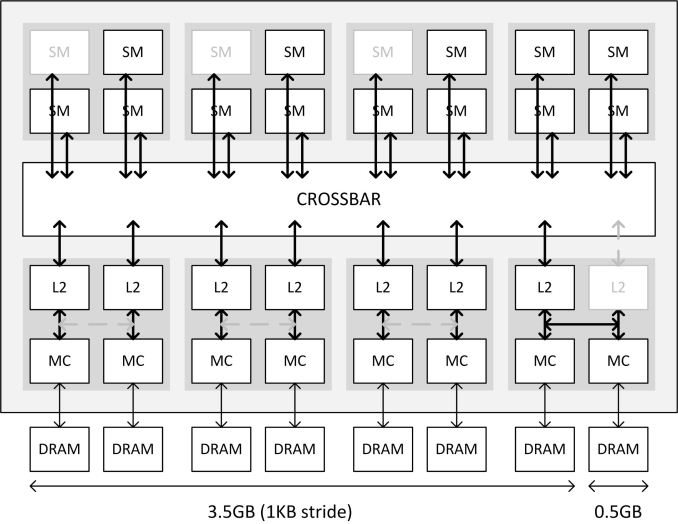
從上圖中我們可以看到四組 GPC (其中每個 GPC 當中有四個 SMM,但有部分被屏蔽)、四個 L2 快取 (ROP 包含在其中) 與記憶體控制器分區以及和 L2 快取與記憶體控制器分區相連的記憶體晶片們,在 Maxwell 架構以前,NVIDIA 若想縮減記憶體控制器的佈局,就得一次砍掉一個 (或是半個,但應該是沒發生過) L2 快取與記憶體控制器分區。
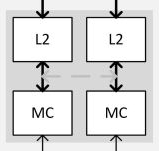
但在 Maxwell 架構當中 NVIDIA 在 L2 快取與記憶體控制器內的兩組記憶體控制器與兩塊 L2 快取分區中間新增了一條備用連線 (也就是上圖中間虛線的地方),這使得部分屏蔽 L2 快取與記憶體控制器分區成為可能 (這四小塊當中有一塊斷掉還可以透過中間的備用連線來維持其他三塊正常運作),但是問題就來了,這代表 L2 快取與記憶體控制器與中央匯流排 (Crossbar) 之間最多只有 7 個 32-bit 寬的通道可用 (其中一個隨著一塊 L2 與 ROP 區塊被滅而失效了),而且若要達成多通道記憶體使頻寬倍增的效果得要所有記憶體通道同步且連貫才行,這就是為什麼前面 3.5 GB 的部分最高速度只有 GTX 980 的 7/8 的原因。
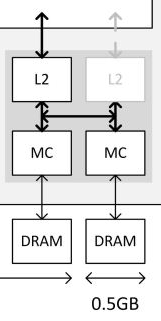
而使用備用連線的這組 L2 快取與記憶體控制器分區當中出現的情況是兩個記憶體控制器可能得共用一個 Crossbar 入口,然而這種情況當然是不被允許的,因此最多只能擇一使用,加上剛剛提到要達成多通道記憶體使頻寬倍增的效果得要所有記憶體通道同步且連貫才行,所以勢必只能分成七個連貫與單獨一個兩種情況,這就是為什麼前面 3.5 GB (7/8 容量,連接於前七個記憶體控制器) 可以有 GTX 980 的 7/8 頻寬、後面 512 MB (1/8 容量,連接於最後一個記憶體控制器) 只能有 GTX 980 的 1/8 的原因。
GM200 核心
接下來要介紹的就是 Maxwell 架構的完整版大核心-GM200 了,從命名上可以得知 GM200 的特色與剛剛介紹的 GM204 相去不遠,基本上就是規模擴大很多的 GM204。
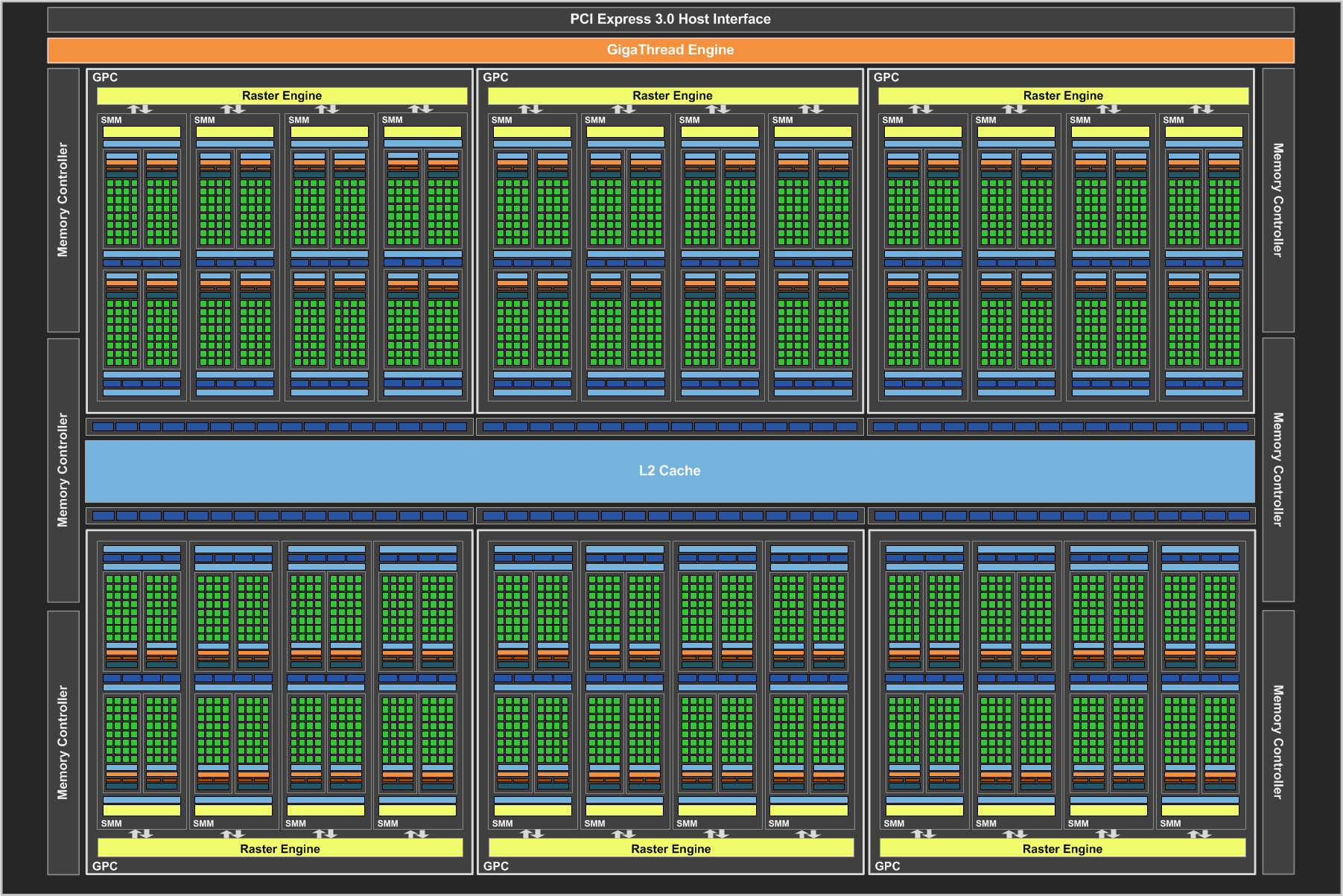
相較於 GM204 而言,GM200 進一步將 GPC 的數量從 4 組提高到 6 組,這意味著 SMM 也跟著多了 4 組 (所以 GM200 有高達 3,072 個 CUDA Core),至於電路規模的部分,GM200 所包含的電晶體數高達 80 億,面積更是高達 601 平方公分,是歷來 NVIDIA 晶片之最。
但是 GM200 與上一代的 GK110 有一點很大的不同,還記得我們介紹 GK110 的時候特別提到 GK110 本來是用於 Tesla K20/K20X 運算卡上,主要針對科學研究而設計因此特別強化了雙精度浮點運算性能,透過在 SMX 內部增加數量多達 GK104 8 倍之多的雙精度浮點單元來使雙精度浮點運算性能從單精度浮點運算的 1/24 提高為 1/3,但在 GM200 上卻不是這樣。

GM200 將原先在 GK110 當中耗費在雙精度浮點運算單元的電路複雜度與面積通通挪用給對於遊戲影響比較明顯的單精度浮點運算單元與 Maxwell 架構當中額外增加的控制電路了,因此 GM200 與 GM204 一樣在處理雙精度浮點運算時的性能都只有單精度浮點運算的 1/32。

至於採用 GM200 核心的產品則只有兩款,分別是採用完整版 GM200 核心的 GTX TITAN X (1000 MHz / 7010 MHz) 與屏蔽了兩組 SMM,定位略低一些的 GTX 980 Ti (1000 MHz / 7010 MHz),說來挺奇怪的,還記得 Kepler 時代的卡王有一張叫做 GTX TITAN Black 嗎?結果 GTX TITAN Black 是銀色的,GTX TITAN X 反而整張都是黑色的。

不過也是從這一世代開始讓大家認識到從 TITAN 誕生以來幾乎 x80 Ti 就會是當世代 NVIDIA 顯示卡當中 C/P 值最高的型號,因為 x80 Ti 會是 TITAN 系列小砍之後的產物,而近幾代 NVIDIA 顯示卡 TITAN 系列與 x80/x70 之間的性能差異之大讓人實在難以忽視,而 TITAN 系列又往往貴得讓人無法直視,相較之下價格比較貼近 x80 的 x80 Ti 就親民多了,但在性能表現上卻與 TITAN 系列相差不多。
GM206 核心
最後一款基於 Maxwell 架構的核心則是 GM206,從名字上可以得知這是一款針對中階主流市場推出的產品,實際上差不多就等於是「半顆」GM204,由 2 組 GPC (合計 8 組 SMM,包含 1,024 個 CUDA Core、64 組 TMU、32 組 ROP) 所組成。
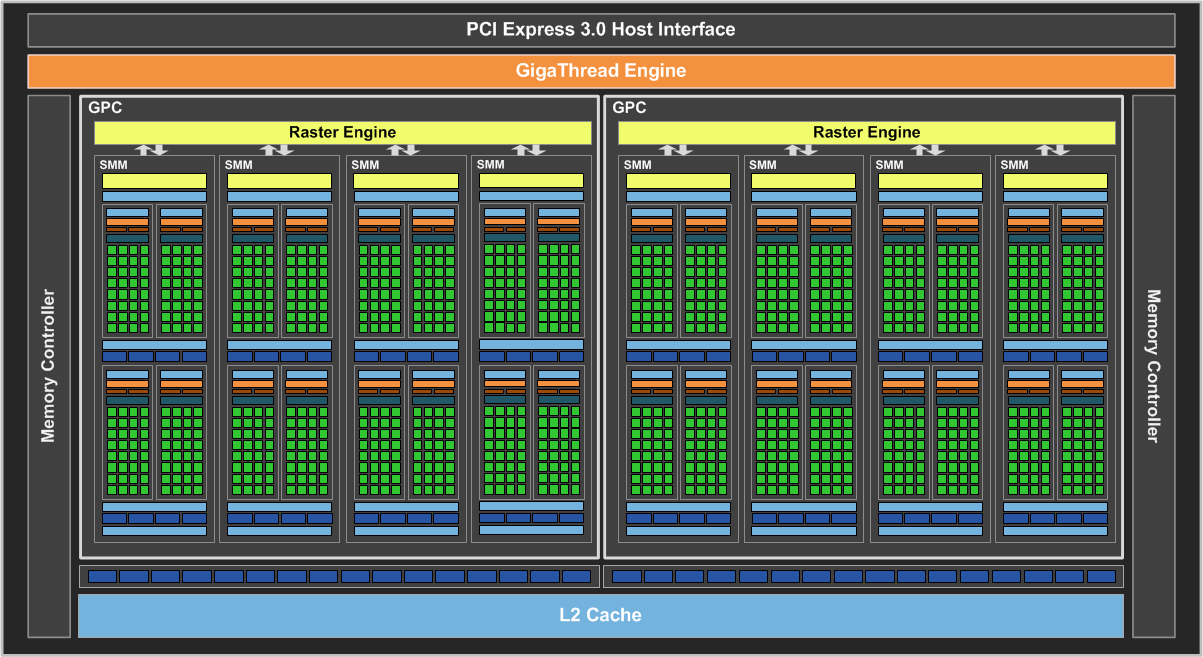
GM206 在功能特性上基本上與 GM200、GM204 相同,所以我就不再重述了,接下來讓我們直接看產品的部分吧。

採用 GM206 核心的產品同樣只有兩款,分別是採用完整版 GM206 核心的 GTX 960 (1127 MHz / 7010 MHz) 與刪減兩組 SMM 的 GTX 950 (1024 MHz / 6610 MHz)。

基於第二代 Maxwell 架構的入門產品呢?
最終 NVIDIA 並沒有再繼續推出等級比 GM206 還要低的產品,因此直到現在你還是可以很容易在店裡買到基於 Kepler 架構的 GT 730 或是更低階的產品做為裝機卡,而 GeForce 900 系列也沒有推出 GTX 950 以下的型號 (雖然曾經有消息說要出一張給 OEM 廠商、基於第一代 Maxwell GM108 核心的 GT 945A,但沒有甚麼確切證實的紀錄),而是直接在去年被基於 Pascal 架構的 GeForce 10 系列給取代了。