

隨著近代 GPU 的可程式化管線設計與兩大 API 支援等基本要素大致上在 2001 年確立了,因此從 2002 年開始,新款的 GPU 主要是以將現有架構改進、增加更多的彈性、拉高各項參數為主要目的。
2002:更加實用的 Shader Model 2.0
在 2001 年微軟發佈了 DirectX 8 系列 API 標準,我們說當時引入的 Shader Model 1.0 給 GPU 架構設計帶來了翻天覆地的變化,並且大大提升了未來所有遊戲設計師能夠運用 GPU 創造新效果的可能,並且大幅提升了 3D 立體圖形的實感,但 Shader Model 1.0 有下列這幾個主要的缺點,導致它其實「很難用」、「很有限」,而且「還不夠彈性」:
- Shader Model 1.x 中,軟體工程師只能使用低階語言 (像是組合語言) 來控制 GPU 內的渲染器
- 一次最多只能操縱 4 ~ 6 個相關材質
- 一次只能下達 4 個材質指令 (SM 1.4 可以下達兩組由 6 個指令組成的材質指令),而且只能處理整數
- 只有 8 組常數暫存器
- 只能處理 128 個頂點處理指令
於是在 2002 年微軟發佈了新的 DirectX 9.0 標準來解決前面這些問題。

DirectX 9.0 與 Shader Model 2.0
在 Windows XP 推出後一年多的 2002 年底微軟正式對外發佈了 DirectX 9.0 更新 (實際上 GPU 設計商在幾個月前就拿到定稿版本的 DirectX 9.0 API 規格書了,因此是先有 DirectX 9.0 GPU 才有 DirectX 9.0 支援更新可供使用),相較於過去的 DirectX 7、DirectX 8 都有架構上的變更來說,DirectX 9 的改進幅度其實沒有那麼大,最重要的一項就是對 Shader Model 進行大幅改版,稱為 Shader Model 2.0。
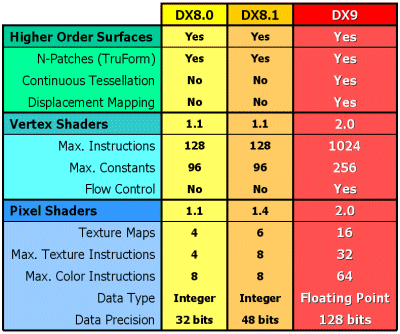
基本上在進入 DirectX 9.0 世代之後,GPU 內的繪圖管線並沒有甚麼改變,但從 DirectX 8 開始引入的 Vertex Shader 與 Pixel Shader 幾乎被重新設計了,改進了剛剛提及在 DirectX 8 當中具有的絕大多數問題,像是像素渲染器只能處理 32 位元或 48 位元整數的問題,在 Pixel Shader 2.0 當中一口氣提升為支援最高 128 位元的浮點運算能力,能夠同時下達的貼圖指令、色彩指令、頂點指令數量方面也都數倍的大幅提升,並且引入了動態/靜態流程控制與巢狀動態/靜態流程控制指令。
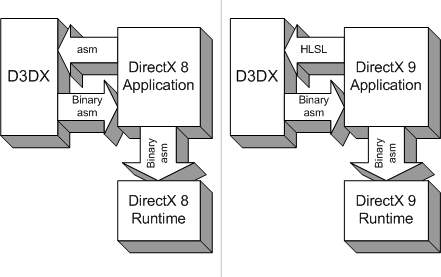
除了在數字方面的大幅躍進之外,Shader Model 2.0 帶來的另一個重點則是 High-Level Shader Language (HLSL),中文翻譯稱之為「高階渲染器語言」,如同過去本站曾介紹過的,在 DirectX 8 當中 Shader Model 1.x 支援的語言實際上很有限,實質上只是低階組合語言 (儘管後來微軟在一些文件當中把 Direct3D 8.x、Shader Model 1.x 也追認為 HLSL,但實際上從官方的介紹文件可以證實實際上並不是這樣),因此在編寫上有相當的困難度,特別是在要撰寫複雜度較高的程式時,顯得更加力不從心,在引入 HLSL 之後,開發者得以活用 GPU 實際能力的程度便瞬間提高了不少。

而最後要提的是,儘管 DirectX 9 帶來的改進並不如前作那麼巨大,但 DirectX 9 可以說是歷代 DirectX 當中影響力最大、生存時代最長的版本 (直到今天都還有很多遊戲提供 DirectX 9 模式),雖然這某種程度上和 DirectX 9 是 Windows XP 能支援的最後一個版本、DirectX 10 要等到 2006 年才生得出來、Vista 失敗導致 DirectX 10 難以在短時間內普及、Windows XP 直到 2013 年市佔率才開始明顯下滑等因素有關,但最大的因素還是因為 DirectX 9 的 Shader Model 2.0 比起前作來說大有長進且能合乎基本需要的緣故。
接下來我打算介紹的就是 DirectX 9 世代的產品,首先要登場的是在可預見的未來內都會被 ATI 與 NVIDIA 兩家公司永遠銘記的 Radeon R300 與 GeForce FX。
ATI Radeon R300 (9000 系列中高階版、X3/X5/X6/X10 系列前期)
發佈時間:2002 年 08 月 (R300)、2003 年 (RV350/RV360/R350/R360)、2004 年 (RV370/RV380)
API 支援:Direct3D 9.0、OpenGL 2.0
Shader Model 版本:Vertex Shader 2.0, Pixel Shader 2.0
像素渲染器 (PS):8 組/頂點渲染器 (VS):4 組/材質對應單元 (TMUs):8 組/著色輸出單元 (ROUs):8 組 (R300/R350/R360)
像素渲染器 (PS):4 組/頂點渲染器 (VS):2 組/材質對應單元 (TMUs):4 組/著色輸出單元 (ROUs):4 組 (RV350/RV360/RV370/RV380)

如同在上一篇曾經談到的,R200 系列曾經讓 ATI 短暫坐上性能王者的位置,但很快就被 NVIDIA 推出的 GeForce 4 Ti 給踹了下來,當時 ATI 曾經醞釀要再次改良 R200 為 R250 並用來推出 8500 XT 以奪回性能王者之名,但最後或許是聯想到當年 3dfx Rampage 的悲劇了吧?最後 R250 計畫並沒有實現,ATI 決定集中公司的開發能量來進行次世代 GPU 的研發,而最後的成果就是 R300 家族 (對了,R300 的主要開發團隊是由 ATI 在 2000 年收購的 ArtX 公司演變而來,而 ArtX 公司本身是從 SGI 獨立出來的,在此之前最著名的產品是任天堂 64 遊戲機的繪圖晶片)。
Radeon R300 架構諸元
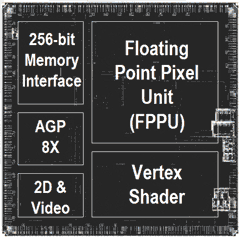
Radeon R300 系列的架構基本上是由 R200 演化而來,主要的改進可分為四大部分,首先是 Radeon R300 增加了對 Shader Model 2.0 的支援能力 (因此 Vertex Shader 與 Pixel Shader 幾乎被砍掉重練了,這使得 R300 成為世界上第一款得以完整支援 DirectX 9.0 的 GPU,看到右上角那一大塊浮點像素單元了嗎?


Table of Contents
有史以來第一次超越 NVIDIA
值得注意的是,對 DirectX 9.0 的支援也使得 ATI 有史以來第一次成功在產品功能上超越 NVIDIA),從歷史的角度上來看其實這點還蠻有趣的,在 DirectX 8 時期是由 NVIDIA 搶快推出了支援 DirectX 8 的 GeForce3,不過後來卻因為太早推出而被微軟的 DirectX 8.1 扇了一巴掌,但這次卻是由 ATI 搶快了,而且有著截然不同的結果 (其實主要原因在於 DirectX 9 沒改架構,卻讓 Shader Model 真正進入成熟階段,而且市面上支援 Shader Model 的遊戲也漸漸增加了)。

新的覆晶封裝方式
第二個主要改進則是封裝方式的改變,儘管 Radeon R300 仍然基於與前代相同的 150 奈米製造工藝生產,但卻首次使用新的覆晶球狀陣列封裝 (FC-BGA) 來製造 GPU 晶片 (其實也不算新啦,FC 技術早在 1960 年代就被 IBM 發明出來了,只是沒有用在個人電腦上) 而不是使用一般常見的 BGA 封裝方式。

傳統上使用的 BGA 封裝方式 (上圖) 是採用導線架 (Lead Frame) 來將晶片本身的接點與基板連接 (這種方式稱之為「打線接合 (Wire Bonding)」),因此實質上晶片電路本身是面向電路板的,因此面對散熱器的部分實質上是晶片的外殼,而且只是「背面」,顯然這種作法散熱效率不會太好。

而 Radeon R300 所使用的覆晶球狀陣列封裝 (FC-BGA) 則是直接在晶片本體上做出金屬接點,並將整個晶片翻面之後,運用熱風回流焊等技術直接焊接到電路基板上,因此晶片本身是得以和散熱器接觸的,這使得 Radeon R300 的散熱問題變得容易解決許多 (基本上當今的 GPU 與 CPU 都是使用類似的方式封裝的),也使得 R300 能夠拉高時脈,在性能上有很明顯的幫助。

搭上 Shader Model 2.0 的強化之後這兩個因素更讓 ATI 得以再次從 NVIDIA 手中奪回性能王者的王位 (同時也因為當時顯得極為強大,遠勝過 NVIDIA 同期產品 50% ~ 100% 的反鋸齒 (AA) 計算性能,使得反鋸齒技術得以漸漸普及)。
幾乎全面翻倍的架構設計
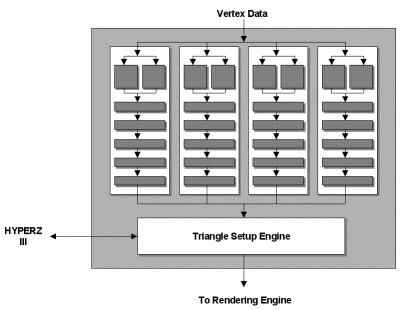
而第三個主要改進則是在架構上的配置參數有很大的不同,我們知道在上一代的 R200 當中 ATI 放棄了三重紋理貼圖設計,並將材質對應單元 (TMUs) 的數量改為 2 的倍數以提高雙重紋理貼圖 (較常見的情況) 利用 TMU 的效率,在 R300 當中也是維持了這樣的想法,但是數量上又再次提高了不少。
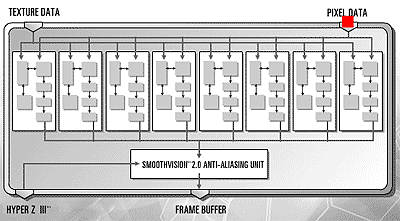
R300 系列的核心最多能搭載 8 組像素渲染器、4 組頂點渲染器、4 組著色輸出單元 (ROP),這些都是 R200 的兩倍 (僅有 TMU 數量維持不變,因此像素渲染器對材質對應單元的比例變成 1:1,但得益於 loopback 設計的強化,對性能沒有造成太多負面影響),因此在性能上又帶來了更大幅度的提升,也使得 ATI 可以透過刪減這些單元配置的方式來細分出更多不同版本的晶片以滿足不同階層市場的需要。
記憶體架構與第三代 HyperZ 技術
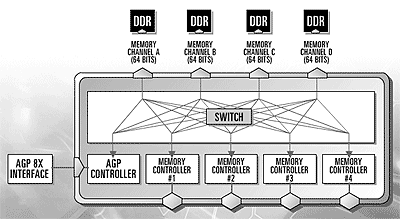
最後一項改進則是記憶體頻道寬度的大幅提升,Radeon R300 是全世界第一款支援 256 位元寬度 DDR 記憶體通道的顯示晶片 (由四組 64-bit 記憶體控制器所組成,至於為什麼這樣設計其實是有原因的,因為「每次傳送的資料未必足以塞滿 256-bit」,如果在這種情況下單一的 256-bit 記憶體控制器就會有很多地方被浪費掉,若分成四組就不會有這個問題,因為沒用到的記憶體控制器可以去做其他事情),使其顯示記憶體的理論資料傳輸率直接翻了一倍來到了 20 GB/s 之譜,但 ATI 對顯示記憶體的努力卻不僅止於此,第三代的 Hyper-Z 更可以大幅節省記憶體頻寬的利用,使得 Radeon R300 有著非常充裕的記憶體頻寬來發揮其性能。
以上四大改進使得 Radeon R300 得以成為歷代 ATI 顯示晶片當中市場生命周期最長的一代,從 2002 年夏天作為新一代旗艦顯示晶片開始,歷經 2003 年的風光與 2004 年的延續,直到 2005 年還能在經過簡化之後作為低階市場的主力產品,甚至在 2006 年 Windows Vista 推出前夕都還能在許多品牌電腦當中見到基於 R300 核心衍伸版本的身影,不過也因為如此,R300 系列是有史以來衍伸版本最多,也是截至 2006 年為止更名最多次的一代。

回到產品本身
看完 R300 系列的特性介紹之後,是時候回到產品本身了。R300 系列當中的第一款晶片就是 R300,在 2002 年 07 月 18 日以 Radeon 9700 Pro (325/620 MHz) 的名稱推出,是針對高階市場發佈的產品,擁有完整的 8 組 Pixel Shader 與 4 組 Vertex Shader,並且具有 256-bit 寬度的 DDR 記憶體匯流排支援,在推出兩個月之後 ATI 另外推出了時脈較低的 Radeon 9700 (275/540 MHz) 以填補中高階市場上的空缺位置。

在 2002 年底時,ATI 決定將 DirectX 9 世代的顯示晶片向下扎根到中階市場 (某種程度上也是為了消化生產初期因良率問題而無法達到 Radeon 9700 要求的部分晶片),因此以 R300 為基礎將記憶體頻寬減半後命名為 Radeon 9500 (不支援 Hyper-Z III 當中的部分與階層化 Z-buffer 優化有關的功能) 與 9500 Pro 推出,打趴了當時 NVIDIA 推出的所有同級產品,由於使用了與當時頂級產品 9700 Pro 相同的晶片,因此曾經引起透過修改電阻將其破解為 9700 系列的破解熱潮。
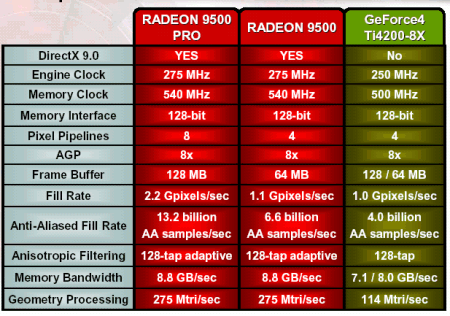
而在進入 2003 年後,由於 R300 的良率已經有所提升,因此 ATI 推出基於 R300 簡化而來的 RV350 做為新的中階產品接替 Radeon 9500 系列的位置。

RV350 與 R300 最顯著的不同是製造工藝提升到 130 奈米,但像素管線與記憶體頻寬都直接腰斬為只剩下一半 (只剩 128-bit 記憶體頻寬、4 組 Pixel Shader、2 組 Vertex Shader、4 組 TMUs 與 4 組 ROUs),因此在理論性能的部分也大致剩下 R300 的一半,先後有 9600 Pro (400/600 MHz)、9600 (325/400 MHz)、9600 SE (325/400 MHz,記憶體頻寬再次腰斬為 64-bit)、9550 (250/400 MHz)、9550 SE (250/400 MHz,記憶體頻寬再次腰斬為 64-bit) 幾個版本推出。

而在 RV350 推出的同時 ATI 也針對 R300 進行了小幅的改版,推出了名為 R350 的新版核心,不同於 RV350,R350 並沒有採用新的 130 奈米製程,而是繼續維持在 150 奈米製造工藝的基礎上,主要的改進內容為運作時脈提升與透過對渲染器及記憶體控制器進行小幅調整帶來更高的反鋸齒運算性能,並以 9800 (325/620 MHz) 與 9800 Pro (380/620 MHz) 的名義推出 (主要對抗的是 NVIDIA 推出的 GeForce FX 5900),可以注意到 AGP 插槽的標準供電已經不足以應付 R350 的需要,因此右上角有了外接電源插座 (用的是傳統硬碟的大 4-pin 電源)。

而 R350 後來又為了因應 OEM 廠商的需要,推出了時脈介於 9800 與 9800 Pro 之間的 9800 XL 與以 9800 為基礎砍掉一半記憶體頻寬 (只剩 128-bit) 的 9800 SE。

接下來在 2003 年下半 ATI 再次更新 R300 系列的成員,分別以 R350 為基礎推出了 R360 (時脈拉的更高的 R350) 與以 RV350 為基礎但首次導入 Low-K (低介電質絕緣) 製程技術的 RV360,其中前者以 R300 系列集大成者之姿上市,命名為 9800 XT (412/730 MHz),而後者則是作為 9600 Pro 的時脈提升版本,以 9600 XT (500/600 MHz) 之名發售。

上面這張圖就是 Radeon 9800XT,沒意外的話這大概是 ATI 第一張開始想到要設計風扇外觀的顯示卡吧?不過 R360 與 RV360 並不是 R300 家族的尾聲,剛剛提到過 R300 家族是歷來最為長壽的 ATI 顯示晶片架構,實際上直到進入 PCI Express 都還有 R300 家族的影子。
PCI Express 時代
在 2004 年 ATI 推出下一代的 Radeon R400 系列時,便把 RV360 再次翻出來改版為 RV370 (主要差異為納入對 PCI Express 的原生支援並採用了更新的 110 奈米製程,某種程度上是 ATI 用來測試新製程用的產品) 並以 X300、X300 LE、X300 SE (記憶體頻寬砍半為 64-bit,另有 HyperMemory 版本可以分享主機板上的系統記憶體作為延伸顯示記憶體使用) 的名稱做為入門款顯示晶片發售 (時脈均為 325/400 MHz)。

而在 2004 年底 ATI 又再次以 RV370 為基礎發展了 RV380,唯一的不同是製程又更換回 RV360 使用的 130 奈米 Low-K (低介電質絕緣) 製程,並以 X600 Pro (400/600 MHz)、X600 XT (500/740 MHz) 的名義發售,然而由於 RV370 還有庫存,因此又使用了 RV370 晶片推出了 X550 這款顯示晶片 (400/500 MHz)。

而 R300 家族的真正絕唱實際上要等到 2006 年底,ATI 推出 Radeon R500 架構 (X1000 系列) 時,又再次把剩下的 RV370 庫存拿來作為 Radeon X1050 推出 (比較特別的是此款採用 64-bit DDR2 記憶體配置),相信大家看到這裡應該已經眼花撩亂了吧。 XD

Radeon R300 系列核心比較
| 晶片代號 | R300 | R350 | R360 | RV350 | RV360 | RV370 | RV380 |
| 推出日期 | 2002 | 2003 | 2003 | 2003 | 2003 | 2004 | 2004 |
| 支援介面 | AGP 8x | AGP 8x | AGP 8x | AGP 8x | AGP 8x | PCI-E | PCI-E |
| 奈米製造工藝 | 150 | 150 | 150 | 130 | 130 | 110 | 130 |
| 像素渲染器 | 8/4 | 8 | 8 | 4 | 4 | 4 | 4 |
| 頂點渲染器 | 4 | 4 | 4 | 2 | 2 | 2 | 2 |
| 材質對應單元 | 8/4 | 8 | 8 | 4 | 4 | 4 | 4 |
| 著色輸出單元 | 8 | 8 | 8 | 4 | 4 | 4 | 4 |
| 記憶體通道寬度* | 256-bit | 256-bit | 256-bit | 128-bit | 128-bit | 128-bit | 128-bit |
* 此處提及的記憶體通道寬度為該核心的最大值。
NVIDIA GeForce FX (NV30/NV31/NV34/NV35/NV36/NV38)
發佈時間:2002 年 11 月
API 支援:Direct3D 9.0a/b、OpenGL 2.0
Shader Model 版本:Vertex Shader 2.0a, Pixel Shader 2.0a
像素渲染器 (PS):4 組/頂點渲染器 (VS):2 組/材質對應單元 (TMUs):8 組/著色輸出單元 (ROUs):4 組 (NV30)
像素渲染器 (PS):4 組/頂點渲染器 (VS):1 組/材質對應單元 (TMUs):4 組/著色輸出單元 (ROUs):4 組 (NV31/NV34)
像素渲染器 (PS):4 組/頂點渲染器 (VS):3 組/材質對應單元 (TMUs):8 組/著色輸出單元 (ROUs):4 組 (NV35/NV38)
像素渲染器 (PS):4 組/頂點渲染器 (VS):3 組/材質對應單元 (TMUs):4 組/著色輸出單元 (ROUs):4 組 (NV36)

接下來要看到的是 NVIDIA 陣營的部分,與 ATI Radeon R300 一樣,NVIDIA GeForce FX 這一世代也是 NVIDIA 永遠難以忘懷的一代,不過不同於 ATI,GeForce FX 帶給 NVIDIA 的可不是什麼光輝的記憶,反而是永遠無法忘記的慘敗。
有史以來第一次被 ATI 超車
GeForce FX 最早在 2002 年 11 月 08 日被公開,第一款基於新架構的圖形核心被命名為 NV30,又一次的跳號、全新的命名、首次把 GeForce 的 G 變成大寫、全新的 Logo 設計,種種地方無一不表現 NVIDIA 對這代產品寄予的厚望,畢竟從 RIVA 128 時代開始,NVIDIA 就一直以創造能夠妥善實現最新 DirectX 規範的 GPU 而聞名,但卻在 DirectX 9.0 這一世代被 ATI 超車,這對 NVIDIA 來說可以說是死裡回生之後第一次遭遇的奇恥大辱。

時序回到 2002 年 08 月,當 ATI 發佈 Radeon R300 時,其實 NVIDIA 並沒有太當作一回事 (畢竟過去 ATI 有很多次產品時程跳票一直拖的紀錄,反而 NVIDIA 幾乎都很準時),當時的 NVIDIA 似乎是有點輕敵,認為 NVIDIA 還沒搞定的 DirectX 9 應該不可能那麼早就被 ATI 做出來,不過 NVIDIA 沒想到的是,這次 ATI 並沒有像以前那樣跳票,反而異常準時的推出了 Radeon R300。
基於認為 Radeon R300 無法太快對自己構成威脅的想法之下,NVIDIA 最初是希望在 DirectX 9.0 世代能夠讓自己的王者地位更加穩固,因此在 GeForce FX 這一代產品上大量加入了新的技術與特性 (結果導致電晶體數與電路複雜度失控飆升),並大膽採用當時台積電才剛開始量產不久的 130 奈米製程與同樣仍舊不夠成熟的 DDR2 記憶體 (由三星提供)。
功能很多很好很強大,結局卻是歷來最悲劇。
不過選用最新製程的代價卻是由於良率拉不起來而造成的不斷延期,本來 NVIDIA 暗算 ATI 應該會發生的悲劇居然落到自己身上了,在發佈後不久就發出 GeForce FX 得拖到 2003 年才能上市的新聞,而實際上最後要等到 2003 年 01 月我們才能真正在市場上見到 GeForce FX 的身影,在這之前 NVIDIA 則只能靠 GeForce 4 Ti 的超頻版來與 ATI 對抗 (顯然只有被壓著打的份)。
除了製程造成的問題之外,搶先採用尚未成熟的 DDR2 記憶體也帶來了悲劇。當時的 DDR2 記憶體溫度很高,而且儘管時脈所提升,但延遲卻提升了更多,又加上 NVIDIA 只給第一批 GeForce FX 搭配 128-bit 的記憶體通道,於是即便在採用新世代記憶體的狀況下,GeForce 2 時代的記憶體瓶頸卻再次重現了 (理論資料傳輸率落後於 Radeon R300),甚至還帶來了新的散熱問題,GeForce FX 能發揮的性能也因此大打折扣。
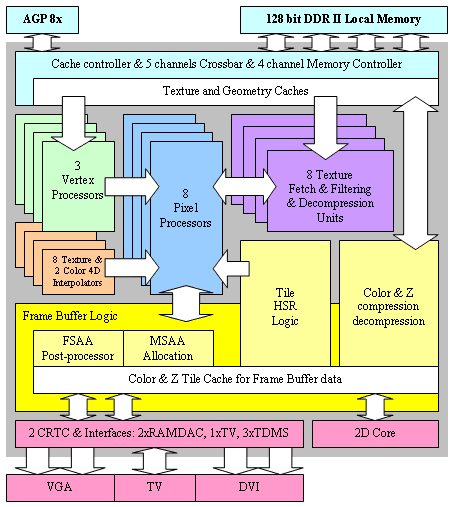

接下來回到 GeForce FX 的架構本身,以前期最高階的版本 NV30 為例,NVIDIA 將 NV30 使用的架構設計命名為 CineFX 引擎,從架構圖上其實可以看得出來 NV30 (上圖) 是演化自 NV25 (下圖) 而生的產物 (很像同時融合 DirectX 7、8、9 的結果),主要可見的改進有 Pixel Shader 數量的成長與多了一組 Vertex Shader,記憶體控制器的部分則經過重新設計,由 DDR 升級為 DDR2、Crossbar 從四通道變成五通道,不過仍然只有 128-bit 的通道寬度,此外,TDMS 輸出的數量也大增為三組 (可以支援更多 DVI 螢幕) 等。
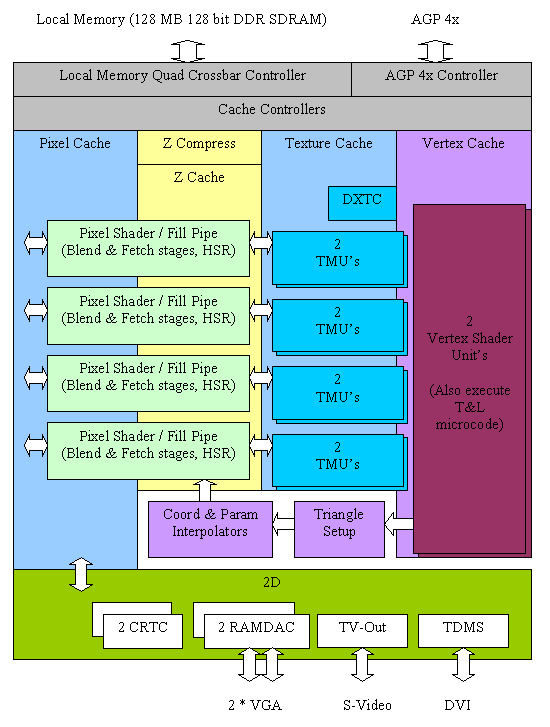
單從架構上看來 NV30 確實在各方面都有比 NV25 進步沒錯,因此在執行 DirectX 8 程式的時候 NV30 的性能確實可以贏過上代的產品不少,不過最大的根本問題是,作為當家旗艦競爭對手絕對不會是上代產品,而是得跟競爭對手的最新旗艦直接 PK,特別是在處理 Shader Model 2.0 等新技術的時候必須要能輾壓對手,這樣才說得上是真正的旗艦產品吧?
BUT,根據實驗結果顯示,在絕大多數情形下 NV30 處理 Shader Model 2.0 的速度大概只有 Radeon R300 的一半左右。
GeForce FX 背後牽扯的三方角力
至於為什麼會發生這麼慘的狀況呢?其實跟 GeForce FX 的浮點運算單元配置有關,在 Radeon R300 上我目前掌握的資料顯示 ATI 給每條像素管線都設計了完整的兩套 24-bit 浮點運算單元,而 NV30 則是設計每條像素管線都由兩組 12-bit 浮點運算單元組成,這意味著對於 NV30 來說會有兩種運算情形:
- 高精度模式 (FP32):畫質比 Radeon R300 好 (但其實看不出來),但速度只有 Radeon R300 的一半甚至更低
- 低精度模式 (FP16):畫質比 Radeon R300 差 (其實相當的明顯),但速度還是只有 Radeon R300 的一半甚至更低 (因為一組 FX12 仍然不足以處理 16-bit 的浮點運算)
而在這樣的狀況下造就了 GeForce FX 不僅在很多狀況下速度不及對手的一半,甚至連畫質都比對手差一大截,可以說幾乎是全盤皆輸的慘烈狀況,而且為了做到 FP32 支援,電晶體的數量與電路複雜度又再次往上飆了一個等級,連帶的讓溫度也飛上天了。
至於為什麼會發生這種慘劇呢?有一個說法是當年 NVIDIA 與微軟因為在 Xbox 晶片的價格上喬不攏,因此微軟刻意跟 ATI 聯手一起婊了 NVIDIA 一次,一方面讓 ATI 較早獲知確定的 DirectX 9.0 規範以讓其能夠提早推出 Radeon R300,另一方面又刻意把 FP24 這個挺特別的數字定為高精度浮點的下限 (微軟還特別在文件中提到 FP24 與 FP32 的圖片品質沒有差別,而 Radeon R300 的浮點處理能力更是全部專為 FP24 而設計,讓人很難不懷疑其中有特別偏向 ATI 的部分),不過這樣的說法永遠也不會被公開證實就是了。
NVIDIA 永遠的黑歷史-GeForce FX 5800

接下來,回到產品本身來看,首先是剛剛才花費不少篇幅介紹、在 2003 年 01 月推出的前期完整版核心 NV30,以 GeForce FX 5800 Ultra (500/1000 MHz) 與 FX 5800 (400/800 MHz) 的名稱發售。


第一眼看到 FX5800 系列的時候,相信絕大多數人的想法都是「哇,這風扇也太大太豪華了吧?」,對吧?確實 FX5800 最後給人們留下的印象大概就是很燙、很貴、很慢三個悲劇吧,如同剛剛談過的,DDR2 記憶體的溫度很高,因此 FX5800 使用的 FX Flow 散熱器首度把記憶體顆粒晶片也納入散熱器的管轄範圍,除此之外 NVIDIA 也跟進 ATI 的做法,在自家旗艦晶片上使用了新的覆晶封裝技術 (不過由於溫度太高,所以還學 Pentium 4 上了一組金屬均熱板)。

而且 FX5800 系列是有史以來第一張需要占用兩個擴充卡槽的顯示卡、有史以來電路板最多層的顯示卡、有史以來電路用料最豪華的顯示卡、有史以來第一次使用這麼大塊的純銅散熱片,同時也是世界上第一張開始在意散熱器的表面設計的顯示卡 (後來顯示卡散熱器外觀一張比一張酷炫就從這裡開始的,畢竟面積大那麼多,有的是地方可以設計),不過 FX Flow 最引人詬病的不僅止於此,更大的問題在於 FX Flow 是歷來運作時噪音最大聲的 NVIDIA 顯示卡,在這樣的慘況之下,國外一時之間甚至發展出了 Photoshop 惡搞 NVIDIA 的熱潮。

至於性能表現的部分,即便 GeForce FX 5800 Ultra 是世界上第一款記憶體時脈超過 1 GHz 的產品,但實際上在對上競爭對手的 Radeon 9700 系列時其實只能勉強拉到互有勝算的地步,但卻有著很燙、很貴、很慢的三大問題,而在 ATI 乘勝追擊推出 Radeon 9800 系列之後,GeForce FX 5800 系列更是完全沒戲唱了,堪稱是 NVIDIA 公司創立以來第二失敗的產品,而這時 NVIDIA 迫於情勢只能開始思考要如何挽回這樣的情況。

發行自家 Demo 來拉抬聲勢
剛剛投入大量努力好不容易才生出 NV30 的 NVIDIA 顯然沒有辦法在短時間內作出甚麼改變,於是它們決定開始使用四個策略來解決目前遭遇的窘境,首先第一個策略是從軟體上下手的,這個時期裡 NVIDIA 開始大量發佈「僅限 GeForce FX 系列使用」的 Demo 程式來展示自家顯示晶片在遊戲方面的處理能力 (不過既然是技術展示,當然是以對 GeForce FX 有利的部分為主),其中最有名的大概就是下面這部影片中展示的「Dawn」吧?(實際上本來是要出給入門款 FX 5200 用的,但因為以當時來說相當真實的人型與表情,曾經在世界上引起不小的波瀾。說起來有很長一段時間顯示卡廠商喜歡用電腦 3D 繪圖的女性形象當顯示卡的代言宣傳這風氣就是從這裡開始的)

透過媒體操作降低劣勢的傷害
第二個策略則是針對 3DMark 這個知名的基準測試軟體而來,在 2003 年由 Futuremark (以前叫做 MadOnion.com) 所發展的 3DMark 早已成為業界用於評判 GPU 性能的主要參考標準之一,而 NVIDIA GeForce FX 5800 當時在 3DMark03 當中的表現並不理想 (更精確地說是輸的很難看),顯然在 3DMark03 發佈之後會很大程度的影響自家產品的銷售,於是這時 NVIDIA 便決定退出參與發展 3DMark 的 Benchmark Development Program (測試發展計畫,BDP),並開始準備兵分二路對付 Futuremark (實際上這時 3DMark03 的主體已經完成,剩下的大多是除錯工作)。


NVIDIA 一方面公開發表聲明指控 3DMark 並無法真實反映實際情況 (例如大量使用 Pixel Shader 1.4 但市面上很少有遊戲使用 Pixel Shader 1.4 開發之類的,因為 Pixel Shader 1.4 是 ATI 與微軟合作發展,因此 NVIDIA 一直不願意在自家產品納入對 Pixel Shader 1.4 的支援,但 Pixel Shader 1.4 是微軟明文規範在 DirectX 8.1 與 9.0 當中的)、是一個「不好的測試軟體」(有偏袒 ATI 的疑慮)、「無法讓消費者獲得正確的認知」,另一方面則開始研擬如何透過自家的驅動程式「優化手段」來改善 3DMark 的測試分數。
這些指控到底有沒有奏效呢?其實是有的,畢竟顯示晶片的世界早已只剩下兩強鼎立,而測試軟體被兩強當中的任何一者否定幾乎就表示被將近一半的市佔率給否定了,儘管 Futuremark 發了很多次新聞稿澄清與說明 3DMark03 的測試機制與設計緣由,且包含 DELL 等大型電腦公司也都表態支持 3DMark 的公信力,但 Futuremark 的公信力還是受到 NVIDIA 的指控而有了明顯的下跌 (也在這個時候 3D 基準測試軟體數量突然多了起來)。
在驅動程式的部分呢,當時微軟官方 WHQL 認證過的 42.30 版驅動程式搭配 GeForce FX 5800 Ultra 在 3DMark03 當中的部分可謂慘烈,幾乎在所有情況下全都輸給了競爭對手的同期產品,而這個時候 NVIDIA 突然「不明原因」的流出了多個無法通過微軟 WHQL 認證的「Beta 版驅動程式」(最玄的是有多個測試網站居然都同時用到了 Beta 版驅動程式來發測試報告),這幾個流出版本的驅動程式最鮮明的特色只有一項,就是可以大幅提高 3DMark03 的測試成績 (最高可以達到 100% 提升之譜 (THG 的測試顯示可以從 3468 → 5253),由於程度太誇張很多人都不相信,於是 3DMark03 的公信力再次受到重創,NVIDIA 也開始被質疑是否作弊)。

從前面提過的浮點運算架構差異來看,國外有許多人認為這幾版驅動程式是特別設計在偵測到 3DMark03 測試進行中時就自動強制系統使用 FP16 浮點運算模式而不使用高畫質的 FP32,由於畫質低了理所當然處理速度也就快了,畢竟 3DMark 本身不會檢查顯示卡產生的圖形是否正確無誤 (但是 WHQL 測試會檢查是否至少符合 DirectX 9.0 規範當中至少高於 FP24 精度的要求,因此這些驅動程式過不了 WHQL),這樣的理論也與實際分數差了將近一倍蠻吻合的,後來圖像品質的問題也被國外的評測網站以截圖對比的方式證實 (下圖由 GeForce FX 5800 Ultra 搭配測試版驅動程式產生,而上圖由 AMD Radeon 9800 Pro 產生)。

後來 Futuremark 在當年三月底宣布禁止上傳使用 42.67、42.68、42.69 這三個「洩漏」版本的驅動程式執行 3DMark03 測試所得到的分數,畢竟使用這些被戲稱為「Benchmark Driver」、「Press Driver」的特別版驅動程式跑出來的數據根本只是快樂錶罷了,對實際遊戲體驗一點提升也沒有。
Statement from Futuremark (Released on 2003 March 24) :
FYI, we just decided to disable (at least for the time being) all current submitted results using the questionable drivers, Detonator 42.67, 42.68 and 42.69. This means that the current results are not deleted, but disbaled from being published. We encourage you to use only officially released, and/or WHQL’ed drivers, as results run with the above-mentioned driver versions will be disabled.
The reason for this is that the drivers have been officially stated as optimized for 3DMark03, and we can not verify the purity and integrity of the drivers. We are investigating the drivers and their effect on 3DMark03 – both performance and the rendering quality (ie. image quality).
Originally the drivers were supposedly released to a group of websites (and/or other media) as an example, but unfortunately got leaked for public use. We are striving for allowing only officially released & WHQL’ed drivers in the future.
這時連 ATI 也跳出來落井下石 XD (畢竟難得有在驅動程式方面 ATI 能在 NVIDIA 面前自豪的機會)
Statement from ATI :
ATI’s drivers as part of the CATALYST software suite has always been and always will be WHQL certified.
Looking at NVIDIA we notice they have not posted a WHQL certified driver on their web site since August for Windows ME and November for Windows XP. ATI has already committed during the CATALYST launch that our driver postings will be for all supported Windows operating systems, for all our RADEON desktop cards and always Microsoft WHQL certified drivers.
We don’t post “WHQL candidate” or “WHQL certification pending” drivers. (To be honest I am not sure what those designations mean). To summarize all CATALYST drivers will be Microsoft WHQL certified and they will be updated more frequently than any of our competition.
At this point in time it is clear which company provides their end users with more robust and quality-driven driver support.”
向中低階市場擴張
第三個策略則是無視目前產品的弱勢,繼續將 GeForce FX 系列繼續往中低階擴張,在 NV30 鋪貨後兩個月,NVIDIA 就推出了針對中高階市場的 NV31 與針對低階市場設計的 NV34。

定位較高的 NV31 主要以 GeForce FX 5600 系列的名稱推出,與 NV30 主要的不同在於封裝方式使用傳統的打線封裝 (所以上圖中的 NV31 看起來其實跟 NV25 長得很像),並且把頂點著色器從三組砍到剩下一組,並砍掉一半的像素對應單元 (TMUs),其餘參數則幾乎相同。

FX 5600 系列主要有三個成員,分別是一開始的 5600 (325/550 MHz)、降頻版的 5600 XT (235/400 MHz,這很有趣,ATI 把 XT 當成最高旗艦的代表,但對 NVIDIA 來說 XT 是最差的入門產品的意思 XD)、更高階的 5600 Ultra (350/700 MHz),比較特別的是後來還出了運作時脈更高的 5600 Ultra 第二版,使用與 NV30 類似的覆晶技術以將時脈提高到與 5800 同等的 400/800 MHz。

至於面向入門級市場的 NV34 則與 NV31 很類似,基本上除了時脈低了一階之外主要的差異是 NV34 的記憶體控制器更加陽春,因此在搭配 64 MB 記憶體時記憶體通道寬度最少可以只剩下可憐的 64-bit (即便搭配 128 MB 並維持 128-bit 的狀況下效率也不及 NV31),並且採用了較成熟的 150 奈米製程。不過在管線配置方面就沒有甚麼變化了 (這應該是 NVIDIA 對低階產品砍最少的一次,不過說真的 GeForce FX 慘烈的效能其實也沒多少能砍了)。

NV34 一共可分為 GeForce FX 5200 與 GeForce FX 5200 Ultra 兩個版本上市,僅有前者有 64-bit 記憶體頻寬的版本,時脈為 250/400 MHz,至於後者的時脈則是與 GeForce FX 5600 接近的 325/650 MHz (記憶體時脈的部分甚至高於 FX 5600,但由於記憶體控制器的簡化,因此不會有上打的情況)。
GeForce FX 「效能型」-NV35
而最後一個策略就是 NVIDIA 同時也開始加緊以 NV30 為基礎發展改進版本,希望能夠挽回公司的聲望 (畢竟前面那些「策略」都只能暫時抵擋住壓力,終究不是長久之計),而這個計畫的最終產物就是 NV35,相較於原先的 NV30 來說有著不少細部的改進,並將改版後推出的型號稱之為「效能型」,而之前基於 NV30 技術的型號則命名為「主流型」。
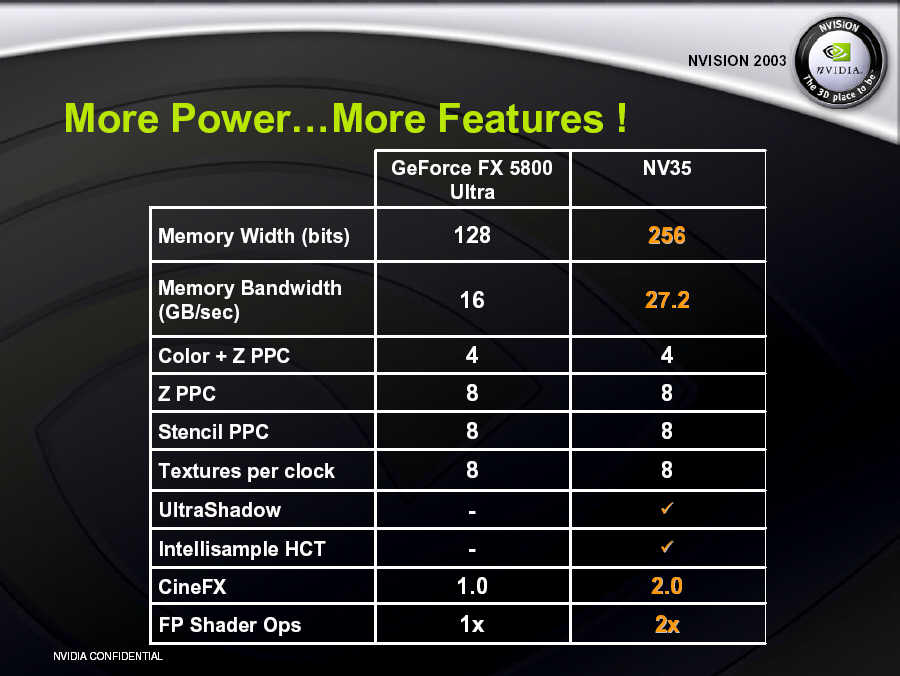
其中第一項明顯的改進就是記憶體規劃,NV30 失敗的其中兩個主因就是過於高溫且延遲過大的 DDR2 記憶體以及僅有 128-bit 的記憶體通道寬度,而在 NV35 當中 NVIDIA 選擇回頭效法 ATI Radeon R300 的作法,改用 256-bit 寬的 DDR 記憶體控制器,於是在 NV35 當中記憶體顆粒晶片的溫度明顯的下降,而儘管記憶體運作時脈也因此下滑,但由於寬度提升最後記憶體頻寬卻反而增加了 (甚至可以比 Radeon 9800 Pro 還高)。
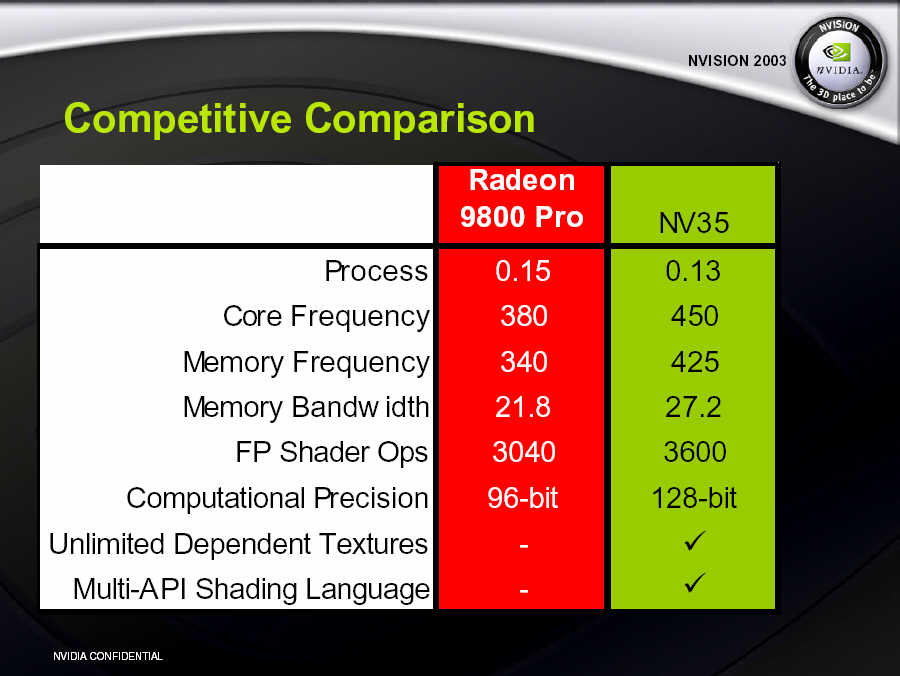
第二項改進則是出現在像素管線本身上,NV35 基於第二代的 CineFX 2.0 引擎,每條像素管線由兩組 Mini FP32 浮點運算引擎組成,相較於上代僅有兩組 FX12 浮點運算能力的狀況來說,在處理浮點運算的效率會比 NV30 來的高上許多 (儘管 Mini FP32 能處理的運算種類不如 ATI 在 Radeon R300 當中使用的 Full FP24 來得多,所以 Shader Model 2.0 使用率越高的狀況下 NV35 還是會顯得越力不從心),改進了 NV30 的另一個主要問題。

而另一方面由於 130 奈米製造工藝在 NV35 的時期已經邁入成熟,因此 NV35 的良率比起 NV30 來得高出許多,這使得 NV35 的生產成本可以進一步下降,同時 NV35 的功耗問題也比較不如 NV30 嚴重,因此並沒有搭配「吹風機」FX Flow,散熱器,NVIDIA 另外給 NV35 設計了另一款挺別出心裁的散熱器 (透過特殊排列的散熱鰭片來達成幫顯示核心散熱之外還順便替記憶體晶片降溫的效果),儘管仍然需要占用兩個擴充卡槽,但安靜了不少。

最終 NV35 以 GeForce FX 5900 系列的名稱在 2003 年 05 月 12 日發售 (距離 FX 5800 上市只過了兩個月),大抵上可分為 5900 (400/850 MHz)、5900 XT (390/700 MHz) 與 5900 Ultra (450/850 MHz) 三款。

整體來說 NV35 是一個比較成功的型號 (雖然比起以前來說還是很失敗),但至少在這個時期裡成功幫助 NVIDIA 收復過去幾個月內丟掉的一些失土,不過畢竟還是從 NV30 衍伸出來的產物,因此還是有很多共通的弱點沒能解決,終究造成了從 Radeon R300 推出之後直到 GeForce 6 Series 推出之前 NVIDIA 都只能當老二的局面。
中階產品的更新
在 NV35 逐步收復失土的同時,NVIDIA 意識到自己在中階市場部分的地位仍然在不斷流失,因此便以 NV35 為基礎在同年 10 月發展出了中階版本的 NV36,NV36 基本上可以視為砍掉一半 TMU 的 NV35,除此之外其實沒有太大的不同,但由於 NV36 出生的時間點正好落在顯示記憶體改版的更迭期間,因此 NV36 先後有支援 DDR、GDDR2 與 GDDR3 記憶體的版本出現。

NV36 一樣使用了覆晶封裝技術,但或許是出於發熱量較低的考量,並沒有如同 NV35 一般在表面上加上金屬均熱板,而是使用晶片直接外露與散熱器接觸的方式,最終 NV36 以 GeForce FX 5700 系列的名稱發售,一共有 5700 Ultra (475/900 MHz + GDDR2)、5700 (425/500 MHz + DDR)、5700 LE (250/400 MHz + DDR,2004 年推出) 與最低階的 5700 VE (235/400 MHz + DDR,2004 年推出) 及最晚推出的 5700 Ultra GDDR3 (475/950 MHz + GDDR3) 五個版本。

值得注意的是,類似於 NV34 的情況,得益於散熱器的體積較小,因此 NV36 通常是採單卡槽的形式設計,不需要占用第二個擴充卡槽。
3DMark03 「優化」事件的續集
在 NV35 推出之後許多國外媒體非常驚訝的是,NVIDIA 在上次被抓包於 3DMark03 基準測試當中作弊之後並沒有學乖,有多個國外媒體在測試 GeForce FX 5900 時發現,明明在架構上沒有明顯的變化,但 FX 5900 卻能在 3DMark03 測試當中輕鬆勝過 ATI Radeon 9800 Pro 許多因此引發了各界的質疑,因此國外媒體向 Futuremark 取得發給參與測試發展計畫的合作夥伴用於測試與分析的開發版本 3DMark03 並在 FX 5900 上試跑,希望能從中找出問題 (開發版本與一般版本的 3DMark03 差異在於開發版本可以暫停並倒帶回去看每張顯示卡產出的畫面甚至切換檢視場景的視角)。
沒想到在一張一張看並稍微移動視角之後,媒體們看到的居然是畫面當中有許多像是下面這樣沒有完全正常渲染的結果 (這是 Game Test 4 的天空):

這意味著 NVIDIA 的顯示卡並沒有正確把整個場景畫出來,而是僅有正確畫出在預設檢視視角的地方 (所以在沒切換視角的狀況下看不出問題,但只要視角一變,畫面就整個破掉了)。

除此之外還有類似情況的場景則是出現在 Game Test 2,由於緩衝區並未被正確清除因此在本來應該是黑色星空的畫面上反而出現大量的白色圖形。

這樣的狀況引起了大家與 Futuremark 公司的重視,Futuremark 在經過一系列內部測試與調查之後在 2003 年 05 月 23 日發表了一份措辭相當強烈的稽核報告,在標題當中直接點名 NVIDIA 透過驅動程式手段在 3DMark03 當中運用作弊試圖提高測試成績,Futuremark 提出的最直接證據是當他們試圖改變 3DMark03 載入畫面的某些部分之後,不同視角下的破圖問題竟然消失了,而且 NVIDIA GeForce FX 5900 Ultra 的測試成績從 5806 分一口氣跌到剩下 4679 分 (跌幅高達 24.1%)。
超過兩成的跌幅顯然不在誤差範圍之內,而 Futuremark 還更進一步在稽核報告當中清楚解析 NVIDIA 是怎麼透過驅動程式手段來做到這些事情的,例如透過載入畫面的特徵來辨識出是否正在執行 3DMark03 測試、透過驅動程式指示圖形晶片略過某些 3DMark03 下達的指令來提高處理速度、透過辨識 Futuremark 使用的 Vertex Shader 軟體來要求顯示晶片不將特定緩衝區 (標準視角畫面會用到的區域) 之外的部分清理乾淨等。
不過最慘的是 Futuremark 在測試的過程中竟然發現 ATI 也做了類似的事情,不過並沒有像 NVIDIA 那麼誇張,在改版之後大約降低了 2% 左右的測試成績 (NVIDIA 的十分之一)。在發佈稽核報告的同時,Futuremark 也同步發佈經過小幅修改的新版 3DMark03 (Build 330) 來解決這個問題 (透過改變一些不影響測試結果的資訊來讓晶片廠的驅動程式無法辨識出 3DMark03)。
不過故事並沒有到此結束,接下來比較有趣的是兩家圖形晶片大廠的反應,ATI 的反應比較平常,由公關部門主管出來坦承他們確實在驅動程式當中使用了一些技巧偵測 3DMark03,並在偵測到之後使用「最佳化的方式」來執行測試,並且承諾會在下一次發佈的 Catalyst 驅動程式當中取消這些優化手段,但 NVIDIA 就沒這麼乾脆了,NVIDIA 聲稱這些問題是該版驅動程式的小錯誤,會在之後進行修正,除此之外則不願多談,與此同時還放出消息指控 Futuremark 是因為 NVIDIA 退出 Benchmark Development Program 並且不願繳交每年高額的會費才挾怨報復,顯然是在偏袒 ATI 一方 (你相信嗎?從 GeForce FX 開始 NVIDIA 花在宣傳這些東西上面的錢早就超過 Futuremark 收的會費不知道幾倍了吧)。
不過 NVIDIA 與 Futuremark 兩邊看似僵持不下的狀況卻在同年六月初突然有了戲劇性的變化,Futuremark 突然與 NVIDIA 共同發表公開聲明,聲明當中還提到「Futuremark 在深入了解之後,我們現在認定 NVIDIA 的所作所為是在驅動程式當中針對特定程式進行優化而不是作弊」,這篇聲明一出全球所有關心的人都譁然了,前不久還鬧得不可開交,現在居然還發起聯合聲明來了,簡直比八點檔還要戲劇化。
聯合聲明全文如下:
Futuremark Statement
For the first time in 6 months, as a result of Futuremark’s White Paper on May 23rd, 2003, Futuremark and NVIDIA have had detailed discussions regarding NVIDIA GPUs and Futuremark’s 3DMark03 benchmark.
Futuremark now has a deeper understanding of the situation and NVIDIA’s optimization strategy. In the light of this, Futuremark now states that NVIDIA’s driver design is an application specific optimization and not a cheat .
The world of 3D Graphics has changed dramatically with the latest generation of highly programmable GPUs. Much like the world of CPUs, each GPU has a different architecture and a unique optimal code path. For example, Futuremark’s PCMark2002 has different CPU test compilations for AMD’s AthlonXP and Intel’s Pentium4 CPUs.
3DMark03 is designed as an un-optimized DirectX test and it provides performance comparisons accordingly. It does not contain manufacturer specific optimized code paths. Because all modifications that change the workload in 3DMark03 are forbidden, we were obliged to update the product to eliminate the effect of optimizations identified in different drivers so that 3DMark03 continued to produce comparable results.
However, recent developments in the graphics industry and game development suggest that a different approach for game performance benchmarking might be needed, where manufacturer-specific code path optimization is directly in the code source. Futuremark will consider whether this approach is needed in its future benchmarks.
NVIDIA Statement
NVIDIA works closely with developers to optimize games for GeForce FX. These optimizations (including shader optimizations) are the result of the co-development process. This is the approach NVIDIA would have preferred also for 3DMark03.
Joint NVIDIA-Futuremark Statement
Both NVIDIA and Futuremark want to define clear rules with the industry about how benchmarks should be developed and how they should be used. We believe that common rules will prevent these types of unfortunate situations moving forward.
不過從後來 3DMark03 開發部門的主管在其他論壇上的發言依舊強調「3DMark 不接受經過『優化』的測試行為」、「我們會在廠商推出新的優化行為時持續修正 3DMark03 的程式來維持公信力與分數的可比性」,後來公司也向記者透漏不會改變對這些優化行為的看法跟立場等動作來看,感覺上 Futuremark 好像只是為了避免當時稽核報告當中使用的「作弊字眼」太過直接而被 NVIDIA 告上法院。
畢竟在 NVIDIA 數千人規模的公司面前,Futuremark 這間當時僅有二三十位員工的小公司看起來根本只像是個小工作室罷了,可禁不起與 NVIDIA 的纏訟,讓 NVIDIA 停止「優化行為」並結束這件事情應該是當時 Futuremark 的最主要考量吧。
不過當時那份稽核報告的舉證歷歷與清楚的論述居然就被這樣三言兩語的聯合聲明給推翻了,Futuremark 瞬間引發網路上一陣撻伐與砲火,無數的人們要不是怒嗆乾脆把 3DMark 改名為 NVMark 算了就是質疑 Futuremark 到底收了 NVIDIA 多少好處,結果繞了一大圈下來受傷最慘重的不是 NVIDIA 也不是 ATI,反而是 Futuremark 的公信力盪到谷底。
然而除了消費者們很火大之外,負責 ATI 顯示驅動程式開發的團隊主管也在公開論壇上寫下下面這一段話,表明對本次 Futuremark 與 NVIDIA 聯合聲明的不滿與不以為然:
OK time to get in the fun.
ITS CM TIME!!!!
First of all as a favor to me, leave Kyle and Brent out of this. This has nothing to do with them. Period
Secondly I am a little upset tonight so I wont say much until tomorrow.
Third I guarantee you that I will ask for an investigation for optimized drivers tomorrow such that has never happened in ATI’s history. I am prepared to put a hold on all new features I have in the pipeline so our top engineers can see how much we can optmize by not rendering the whole scene. I am guessing we can gain 25% at this point.
Fourth I am not commiting to do these optimizations ever in a released driver but I think its time for apples to apples comparison.
Fifth I am sorry to hear you (the end consumers) so dissapointed in the state of the industry. I feel for you.
Sixth, you all have my personal guarantee that if you continue to support ATI the way you have so far, I will always be here to help out and be one of the boyz on the forums. (I hope that means something to at least some of you)]
Have a good night everyone and lets talk more tomorrow
Terry
這位綽號叫做 Catalyst Maker 的 Terry Makedon 當時真的很火大,直接嗆說要回去叫團隊停止所有開發工作專心研究怎麼「優化 3DMark」,相信他們也可以達到 25% 的提升,而這位講話很直白主管直到今日都還是 AMD 顯示晶片驅動程式開發團隊的主管 XD。
3DMark03 「優化事件」第三集
正當所有人都以為在 Futuremark 推出 3DMark03 (Build 330) 並關閉兩大廠在驅動程式當中所做的特別優化處理之後問題應該可以告一段落時,突然國外媒體又爆出了另一項 NVIDIA 對 3DMark03 使用的優化手段。
這個問題由 ATI 發現並通知各大國外媒體,這次的手法很類似 ATI 在 Radeon R200 時期曾經用檔名來判斷 quake3.exe 來針對 Quake III 進行特別優化的作法 (主要原理是偵測到 quake3.exe 就自動降畫質來提高速度,而最諷刺的是,那次是 NVIDIA 抓到 ATI 「作弊」的),是運用檔名來判定 3DMark03 的執行,因此要被試驗出來很簡單,只須要改一下檔名就行了。
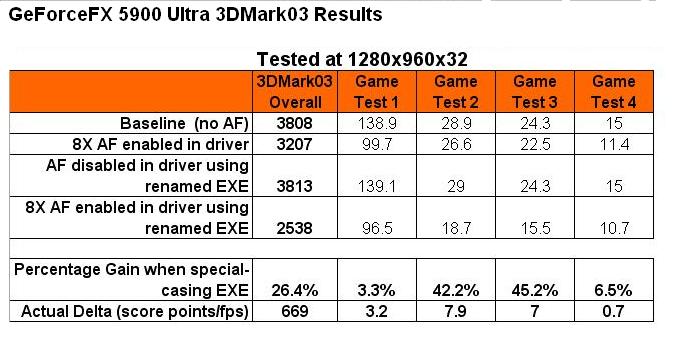
在實驗當中他們發現透過更名可以很大程度的影響在開起非等方性過濾 (Anisotropic Filitering, AF,一種用於改善貼圖物件清晰度及銳利度的功能) 技術時的測試成績,影響幅度可以高達 26.4% 之譜 (不過這次反而 Game Test 4 是最沒受到影響的)。

後來調查之後的結果顯示 NVIDIA 的驅動程式會在發現 3DMark03 之後指示 GPU 使用不同的方式來處理 AF 過濾,連帶使得產出的圖形也不相同 (上圖是國外媒體使用數學方式將更名前後由 FX 5900 所運算出的圖片進行相減得到的結果)
GeForce FX 系列的終極產品-FX 5950
在 2003 年 10 月,為了迎戰 ATI 推出的 Radeon 9800 XT,NVIDIA 將 FX 5900 Ultra 所使用的 NV35 晶片拿出來修改為 NV38,透過採用新的 Low-K 製程與更加成熟的台積電 130 奈米製造工藝,時脈獲得進一步的提升來到了 475/950 MHz,除此之外特性基本上與 NV35 無異。

由於時脈提升因此溫度也跟著提高許多,為了滿足散熱需求,在 GeForce FX 5950 上類似 Flow FX 的散熱器設計被重新起用,不過由於經過採用更大的風扇與不同設計的散熱鰭片形狀等改進,FX 5950 的運作噪音大小並沒有 FX 5800 時代那麼嚴重。
PCI Express 時代
相較於 ATI 選擇使用直接修改自家產品架構來製造具備原生 PCI Express 支援能力之 GPU 的做法,NVIDIA 選擇的是另一條道路-發展橋接晶片 (NVIDIA 真的是一間很喜歡搭橋的公司)。

上圖就是一張 GeForce PCX 5900 顯示卡,實際上在圖形晶片的部分就是普通的 GeForce FX 5900 (所有 PCX 系列的顯示卡大抵上都是這種關係),唯一比較特別的是風扇左下角多出來的金屬散熱片,實際上底下藏的是這顆 BR-02 晶片 (Bridge Revision 2)。

這顆晶片又被稱為 High Speed Interconnect (HSI),它的功能很簡單,就是 AGP 與 PCI-E 之間的轉換而已,因此在 GeForce 7 系列正式全面改採原生 PCI Express 介面設計之前,有很長一段時間在 NVIDIA 的 PCI Express 顯示卡上都可以看到這顆晶片的存在,不過更特別的是,由於 BR-02 是一顆雙向轉換晶片,因此在 GeForce 7 系列甚至 8 系列時也有被拿來負責 PCI-E 轉 AGP 的情況。