











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











Intel QuickPath Interconnect (QPI)
基本上這東西與 AMD 早在 K8 就開始用於處理器與北橋之間的 HyperTransport 匯流排,同樣是點對點、多用途的晶片互連架構,以 Intel 官方的說法是「跟 AMD 不約而同」的結果 (Intel 官方宣稱在 2004 年就已經開始研究發展 QPI,而 Nehalem 是第一款實作 QPI 的產品)。
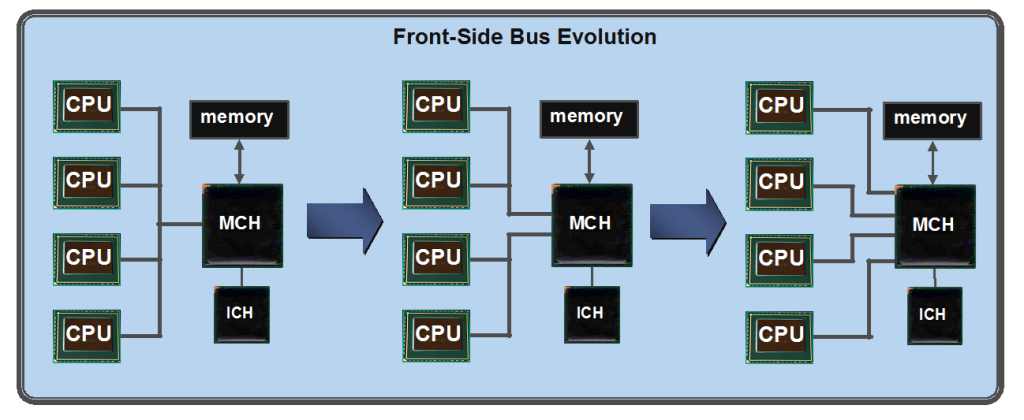
以往多 CPU 系統的設計都是如上圖這樣的作法,所有 CPU 都與北橋 (MCH) 連結,記憶體也直接連結到北橋上,但這樣衍伸出來的問題是當處理器的性能越來越強大、數量越來越多的時候,MCH 的處理能力就會成為多處理器系統上很嚴重的性能瓶頸,而一開始廠商想到的方式是讓 MCH 的通道數增加,但確有造成 MCH 成本提高、能夠增加的數量有限的問題,所以採用直接連結的 QPI 或 HyperTransport 被發展來取代 FSB 可以說是必然的結果。
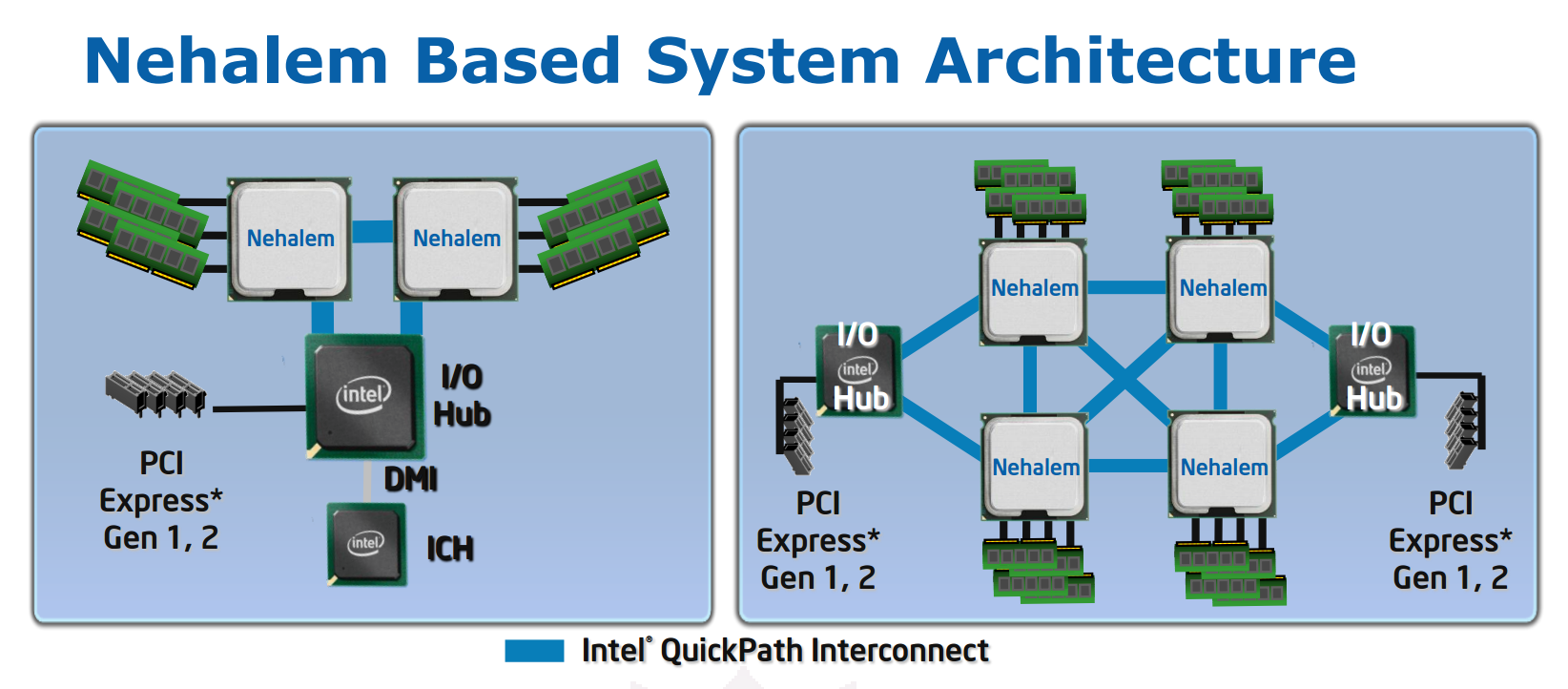
至於上圖右側則是四顆使用 QPI 連結彼此與北橋晶片的 Nehalem-EX 架構圖,可以看出當組成四顆 CPU 的系統時,每顆 CPU 會需要具備 4 條 QPI 通道 (3 條用於互聯,1 條用於連絡北橋),至於比較常見的雙 CPU 配置 (上圖左側) 則需要 2 條 QPI 通道 (1 條用於互聯,1 條用於連絡北橋)。
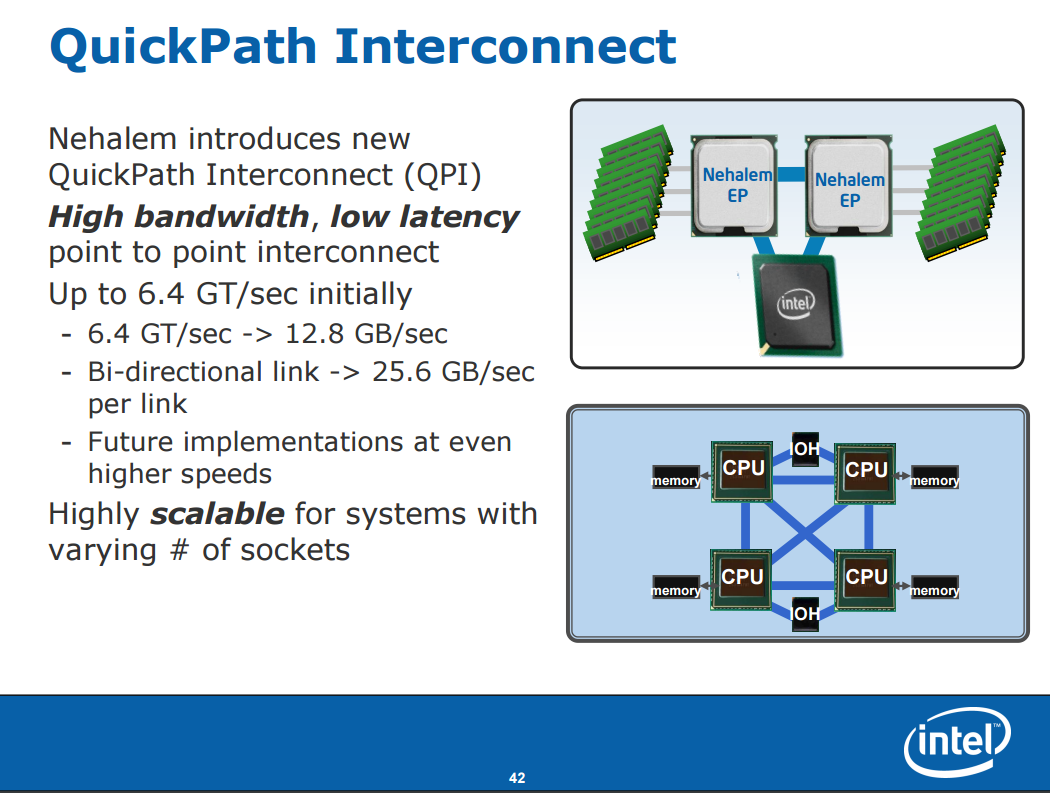
而 QPI 這東西基本上可以用於很多地方,目前已知曾經實作於 Intel CPU 中的就有多 CPU 之間的彼此互聯、CPU 中 Core (運算核心) 與 Uncore (核心以外的周邊電路) 之間的溝通、CPU 與北橋之間的連結等,值得注意的是 Nehalem 架構的高階款 (例如 Core i7 Bloomfield、Xeon 系列中高階款等) 也是目前為止唯一在消費性市場產品上有使用到連外 QPI 通道的世代,之後 QPI 基本上不再用於 CPU 與晶片組之間的連接,基本上都只使用 DMI 匯流排作為處理器與北橋晶片連結的管道。
與 AMD K10 類似的快取結構
以往 Core 架構是採雙層快取,L1 為核心各自獨立,L2 則為全體運算核心共享,稱之為 Intel Smart Cache,而進入 Nehalem 世代之後新的快取階層設計是三層,與 AMD K10 類似,L1 與 L2 都採核心各自獨立,而 L3 則是全體核心共享快取,且與 AMD K10 有類似的大型化 L3 快取現象。

Nehalem 世代的處理器每個核心都具有 32 KB 的 L1 指令快取、32 KB 的 L1 資料快取、256 KB 的 L2 快取 (延遲方面也因為 L2 快取被搬進核心裡面而比 Core 2 架構來得更低很多),至於 L3 快取至少 4 MB,最大則可以達到 30 MB。





