











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











用了一連三篇的篇幅介紹近幾代 NVIDIA GPU 的架構之後,接下來我打算把目光放回 AMD 陣營的對應產品 (我知道我還沒寫 NVIDIA 目前主推的 Pascal 架構,不過由於這系列連載規劃的時候 Pascal 架構連個影子都還沒有所以也就沒列入計畫中了,之後有機會的話再寫 XD)。
由於本篇距離上篇發佈的時間已經隔了相當久,因此在正式開始介紹本篇的主角之前,我打算先簡短回顧一下先前曾經提過的內容,在 5-23 節的時候我曾經提到 AMD/ATI 在過去這一二十年的歷史當中其實幾乎是不斷在重複同樣的發展循環,在 2004 ~ 2006 年時 ATI 本來因為 R400 的了無新意、R500 的難產與 R600 的失敗一度被 NVIDIA 打個半死並導致後來 AMD 的收購,但在 2007 年時甫被收購不久的 ATI 就在 R700 系列當中突然轉換策略使用小核心戰略的奇襲戰術來反將 NVIDIA 一軍,並在後來的 Evergreen 系列當中創造了又一次的輝煌時期。
不過緊跟在 Evergreen 系列之後的北方群島系列就如同當年 R400 系列一般陷入了無新意的困境了,但這次 AMD 總算好不容易沒有像當年那樣再次陷入循環,而是跳過自由落體的階段,在隔年就進行了如同當年 R600 一般進大規模的策略轉換,在北方群島系列之後推出了基於全新 Graphics Core Next (GCN) 架構設計的南方群島系列。
Table of Contents
Graphics Core Next (GCN) 架構
如同在「電腦達人養成計畫 5-20:後 ATI 時代的挫敗與策略轉向-Terascale 架構 (上)」當中曾經提過的,從 2012 年以降的所有 AMD 圖形晶片架構大抵都從本篇要介紹的 Graphics Core Next (GCN) 架構演化而來,截至目前為止 (2018 年) 已經有四個世代 (其中分別有數次代內更新),因此與先前介紹 Tesla 與 Terascale 的做法相似,我打算將 GCN 架構分為四期介紹 (由於本篇連載規劃的時候 Vega 還沒有誕生,因此目前預計只會先撰寫前四個世代的介紹),目前暫定分為上、下兩篇。
GCN 架構概觀
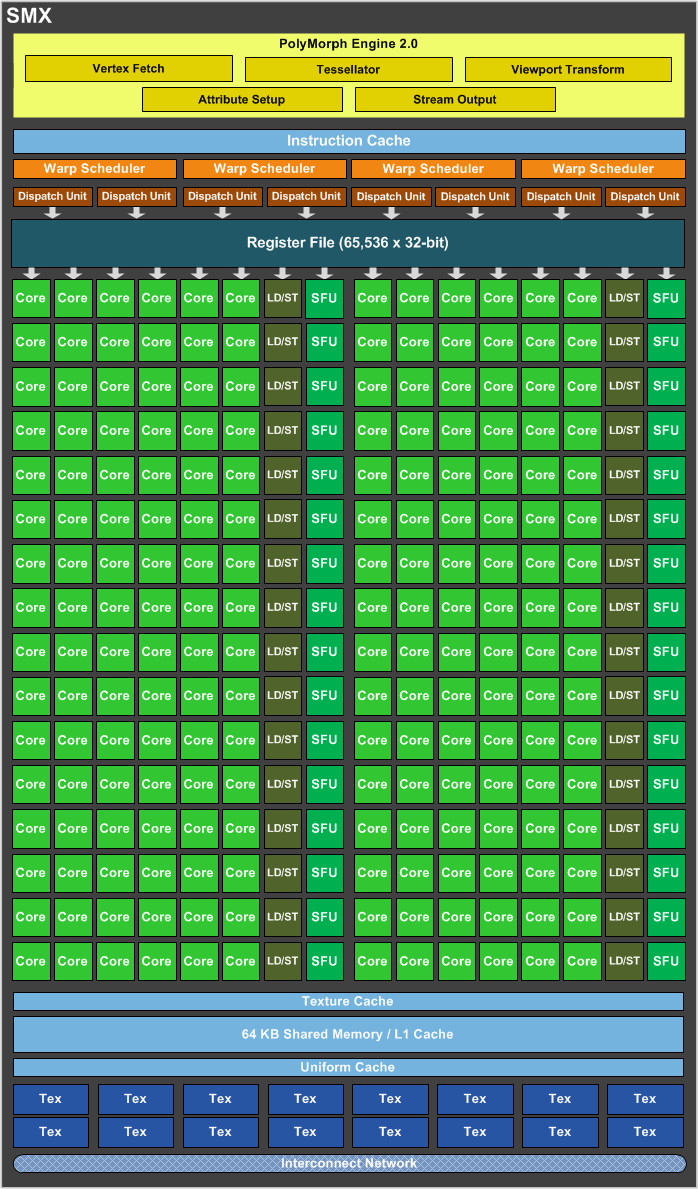
相信大家讀到這裡應該對於 AMD 與 NVIDIA 兩大陣營之間的架構設計思維差異已經有蠻多認識了吧?NVIDIA 的架構是採用 MIMD (Multiple Instruction Stream Multiple Data Stream) 架構,也就是實際負責運算的部分是由大量一模一樣且較為簡單的運算單元 (NVIDIA 將其稱為 CUDA Core) 所堆起來的 (如下圖中的綠色方塊)。
而 AMD 的做法則是採用 SIMD 架構設計,也就受主要運算單元由數組 SIMD Engine 所組成,每一組 SIMD 引擎又由一群運算單元組成,而每個運算單元同時間只能接受「一個」長指令 (也就是 Very Long Instruction Word, VLIW 指令) 輸入但是可以處理多種資料流。

雖然理論上這兩種架構都能達成相似的目標,但是 AMD 的架構對於驅動程式與指令排程器會有較高的要求 (若因為指令相依或是驅動程式未臻完善等情況導致 VLIW 指令合併沒有完全成功,指令無法正確對其硬體單元的配置的話,就會使得運算單元有一部分處於閒置狀態的情況發生)。
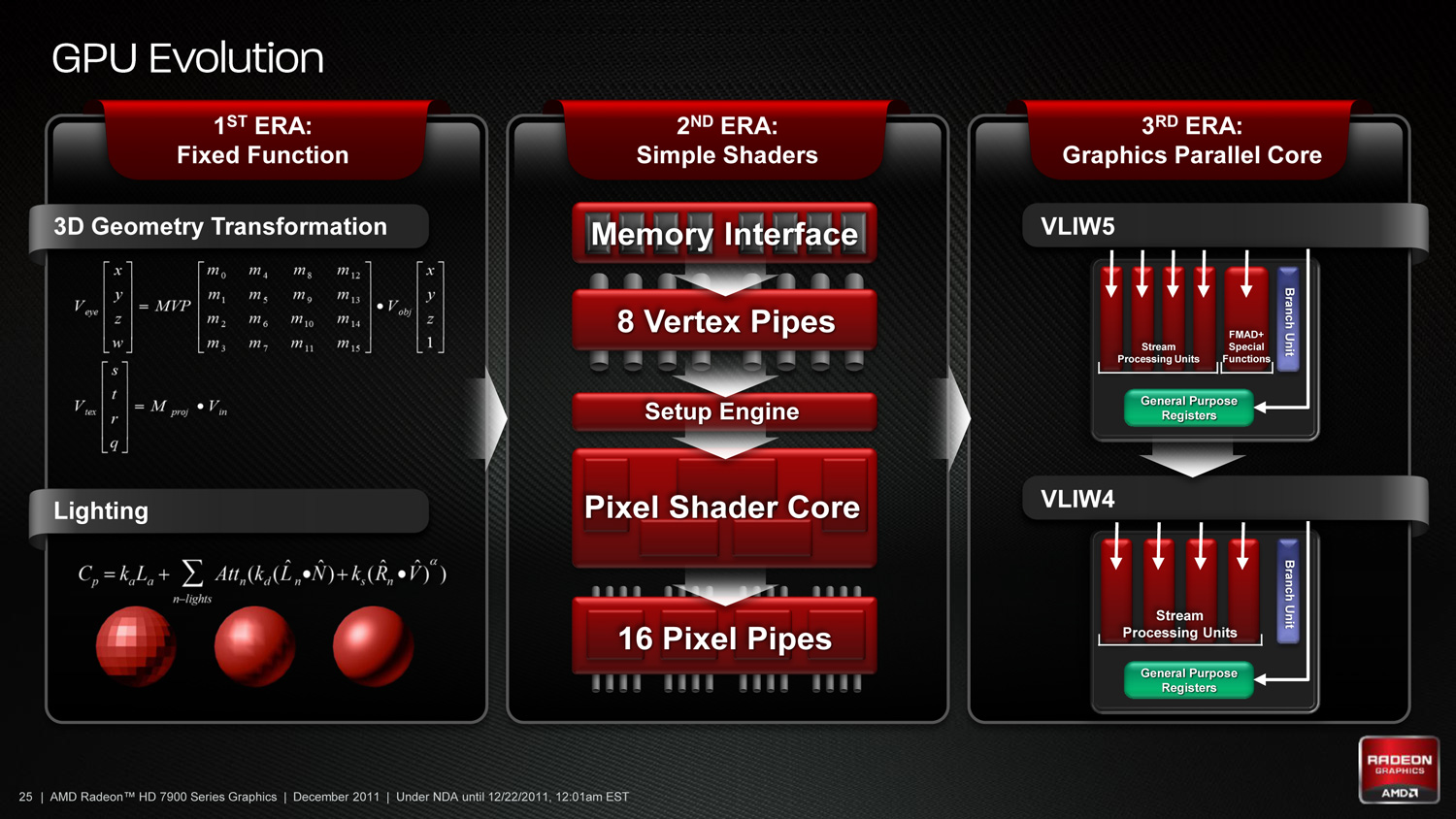
基本上這兩種架構之間各有優缺點,並沒有絕對的好壞之分,而是要看當下處理器所執行指令的「適性」如何而定,AMD 採用的架構在設計電路上複雜度相對較低因此單位面積內可以塞入更多的運算單元,使得創造出比 NVIDIA 更高的「理論峰值性能」數值成為可能,但在指令適性不佳無法充分利用硬體資源的時候就顯得難以發揮,因此有著高度依賴驅動程式與編譯器優化的問題。
而 NVIDIA 的架構則比較能夠適應各式各樣的運算而不需要特別仰賴驅動程式或編譯器的優化,但相對來說在設計電路上複雜度會飆升許多使得晶片上所能設置的運算核心數目受到較大的限制。
一般來說在處理相對而言比較單純的圖形運算時,這兩種架構的表現基本上難分軒輊,但是隨著後來遊戲中可以充分完整利用 VLIW 指令組的頻率越來越低 (以 AMD 自己做的研究來說,平均而言 VLIW5 架構中的 VLIW 利用率不到 68%,平均每組當中大約只使用到 3.4 個運算單元) 又加上 GPGPU 通用運算的流行,由於 VLIW 本身很難提前進行指令排程,對於驅動程式與編譯器的依賴度甚高,也無法在執行過程中進行動態排程,因此在處理通用運算工作時 VLIW 指令合併失敗的情況也隨之大幅增加到足以明顯影響運算性能表現的程度,而 GCN 架構主要就是為了解決這個問題而誕生的 (如果再不改整個通用運算市場會被 NVIDIA 整碗端走)。
捨棄 VLIW 設計,轉為 MIMD 架構但仍保留著濃厚的 SIMD 色彩
Graphics Core Next 架構相較於 Terascale 家族來說,最鮮明的特色就是 AMD 決定捨棄在自家產品上已經沿用多年的 VLIW 設計 (是一種指令級的平行化設計 Instruction-level Parallelism) 與 SIMD 架構,但儘管 AMD 捨棄 VLIW 架構進而改採基於執行緒級的平行化設計 (Thread-level Parallelism) 也轉為使用 MIMD 架構,但其實 Graphics Core Next 架構當中仍然有著濃厚的 SIMD 色彩,因此說 AMD 從 GCN 開始效法 NVIDIA 使用相同的架構設計這說法是大有問題的 (AMD 官方說法是認為 GCN 是一種基於 SIMD 陣列的 MIMD 架構,實際上也可以將其理解為 SIMD 與 MIMD 的混和運用)。

上圖顯示的是 GCN 架構下的向量運算元件中實際負責運算的部分 (AMD 官方稱之為 Vector SIMD),與之前的 VLIW 架構相比應該不難看出兩者之間有相當大的差異,同時這大概也是某些人會誤以為 AMD 直接學 NVIDIA 改成 MIMD 架構的主要原因,畢竟在繪製簡圖的時候負責組成運算基本單元 Compute Unit (CU) 的這票 ALU 看起來確實跟 NVIDIA 陣營的 CUDA Core 可說是十分相似可不是嗎?但實際上 AMD 的設計與 NVIDIA 的架構在本質上仍然有相當明顯的差異。
Compute Unit (CU)
在 Terascale 架構當中實際負責運算工作的單元是串流處理器 (Streaming Processor),而到了 GCN 世代之後負責實際運算作業的基本單元則被 AMD 命名為 Compute Unit,CU 實際上是比起過去 Terascale 架構當中的 SP 更高一階的運算單元組合單位。
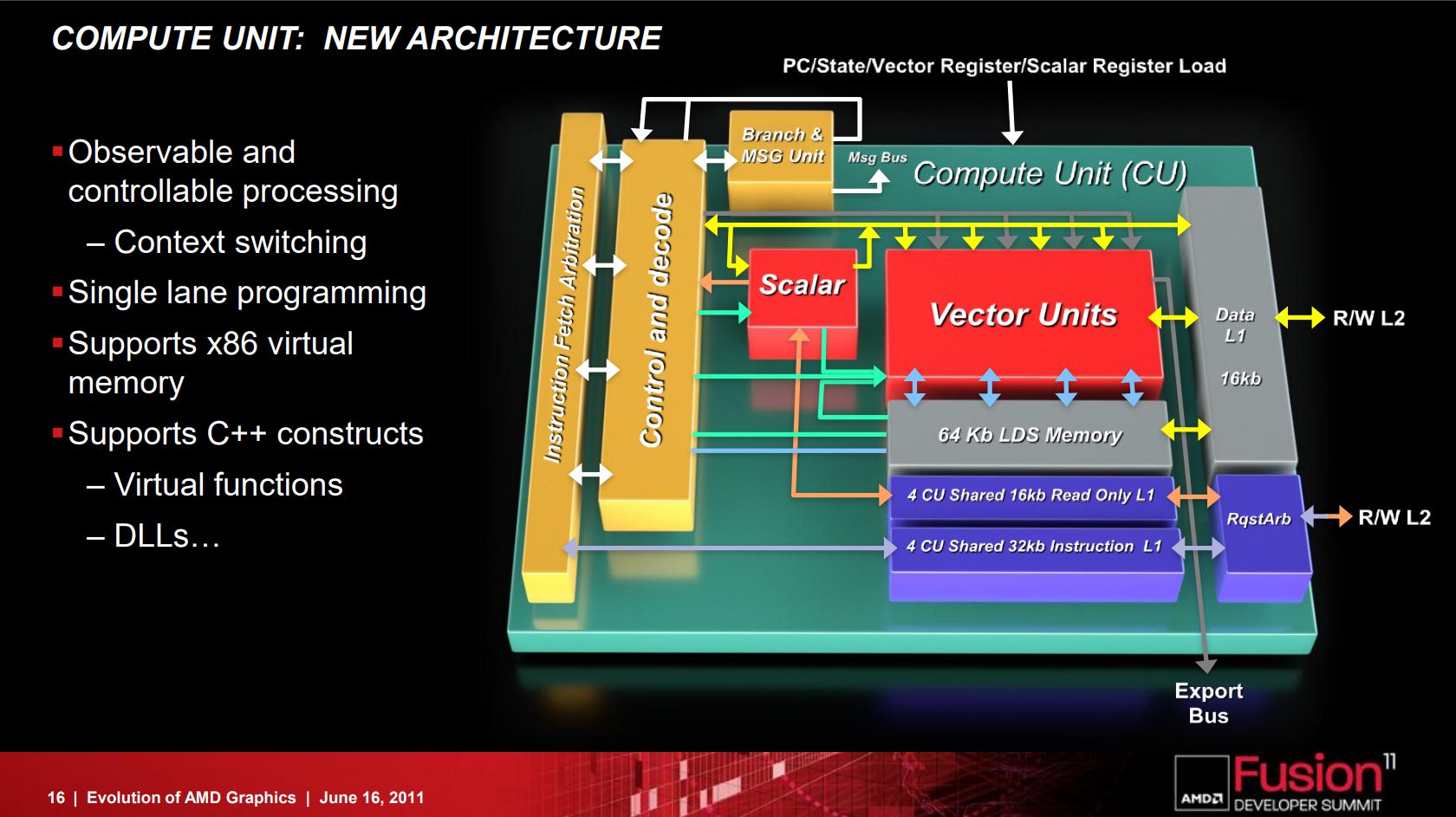
AMD 在設計 GCN 架構的時候將純量運算與向量部分分開,前者作為獨立的純量運算單元而後者實際上是以「多個 SIMD 組」來達成「MIMD 架構」的配置 (每一組 Vector SIMD 基本上仍然是走 SIMD 架構設計的風格,每個時脈可以處理 4 波 64 FMAD 向量運算),因每組 CU 包含了四組 Vector SIMD,使得每個時脈可以處理四個 (可能來自不同應用程式) 指令而達到 MIMD 架構的效果。
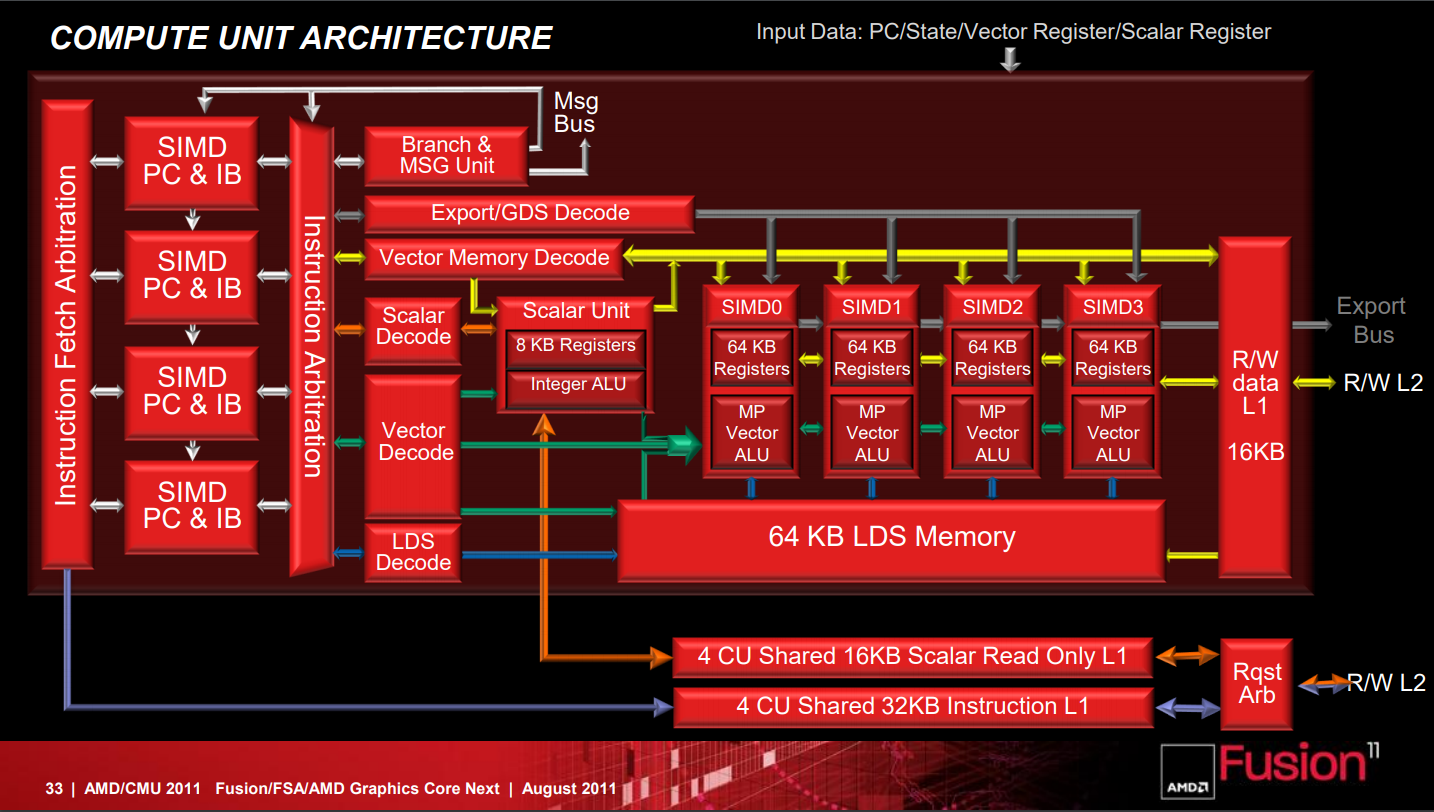
這與 NVIDIA 的架構當中每組 CUDA Core 之間各自作為獨立的個體存在與獨力執行運算工作的作法顯然並不相同,但仍然可以解決 VLIW 架構中如此吃重指令排序、編譯器優化與 VLIW 利用率的問題 (儘管以往在相對單純的圖形運用中這不算是太嚴重的問題,但隨著通用運算等蓬勃發展的新應用所包含的工作內容越來越複雜,要充分利用 VLIW 架構硬體的困難度也隨之快速飆升,這樣的問題漸漸變得不可忍受,再加上高度吃重編譯器優化也使得針對 VLIW 架構開發的軟體難免會受制於特定的程式語言與編譯器)。






