











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











Table of Contents
說大不大,說小不小的改進
如果以最後的性能成績來評判的話,其實 Sandy Bridge 帶來的改進並沒有很明顯 (遠遠不及 Netburst 到 Core 或 Core 到 Nehalem 那樣),但在架構上卻有很多改變,其中有不少設計變更都持續被沿用至今日的 Broadwell 與 Skylake 上,並且在可預見的未來中會繼續使用。
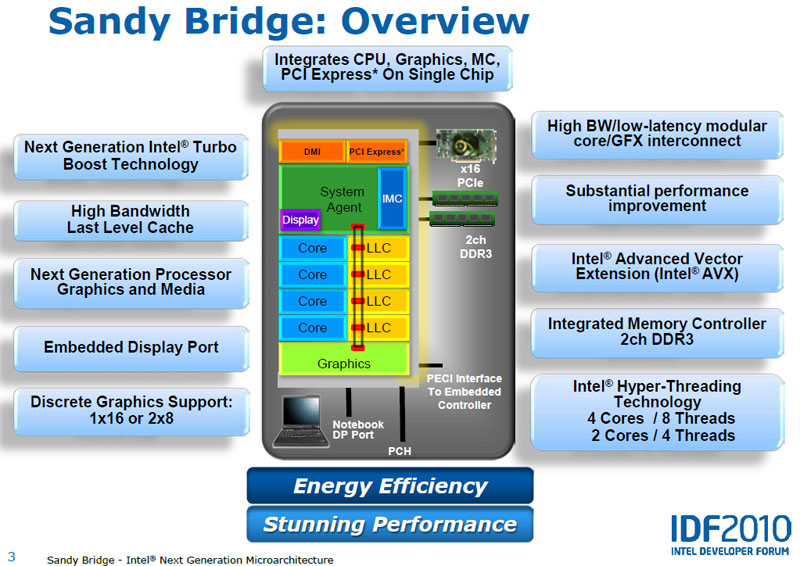
現代 Intel 處理器的基本結構確立
Sandy Bridge 之後基本上處理器設計的基本結構就沒有再發生任何變化了,大致上是延續 Nehalem 市代 Clarkdale 的作法,將 PCI Express 控制器、記憶體控制器放到處理器內,因此北橋已無存在的意義,所以系統基本架構只剩下兩顆晶片,南橋改稱 Platform Controller Hub (PCH) 並繼續稱為晶片組。

但從 die shot 上可以很明顯的看到,從 Sandy Bridge 開始整合顯示核心也被放到處理器晶片中了,不同於 Clarkdale 還使用雙晶片的 MCP 封裝方式,這樣的做法直到今日的 Skylake 仍然獲得沿用,除此之外還有一項很大的不同,那就是模組的排列方式改變了,與下圖的 Clarkdale die shot 對比就能很明顯的看出不同。
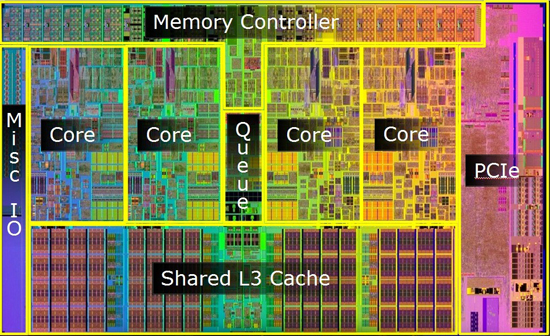
新的排列方式我們可以看到兩個趨勢,首先是 L3 快取與核心正好是切齊的,這意味著 L3 快取的大小與頻寬將與處理器核心數有關 (儘管 L3 快取是共用的),此外也可以很明顯的發現運算核心與快取以外的部分 (Uncore 電路) 有集中被收到旁邊的趨勢,這基本上是為了讓延展性變得更好,讓核心數量增加或減少的時候造成的空間浪費與重新配置需求降低 (所以雙核心版本其實就只是寬度變窄,直接拿掉中間兩組核心而已)。
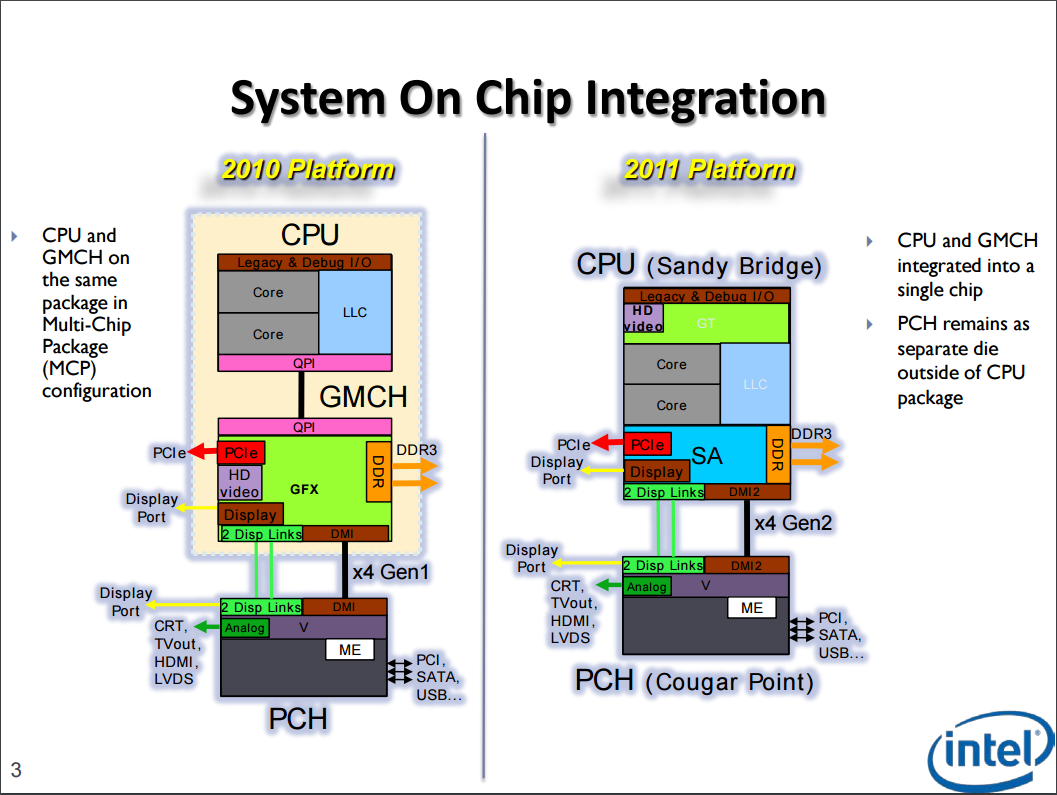
將新舊兩代的系統架構圖排在一起就可以很明顯看出其不同,在 Clarkdale 的時代處理器核心與內建顯示核心兩顆晶片 (MCP 封裝) 之間是用 QPI 溝通的,進入 Sandy Bridge 之後就改為直接整合到單一晶片中。
前端電路再次進化
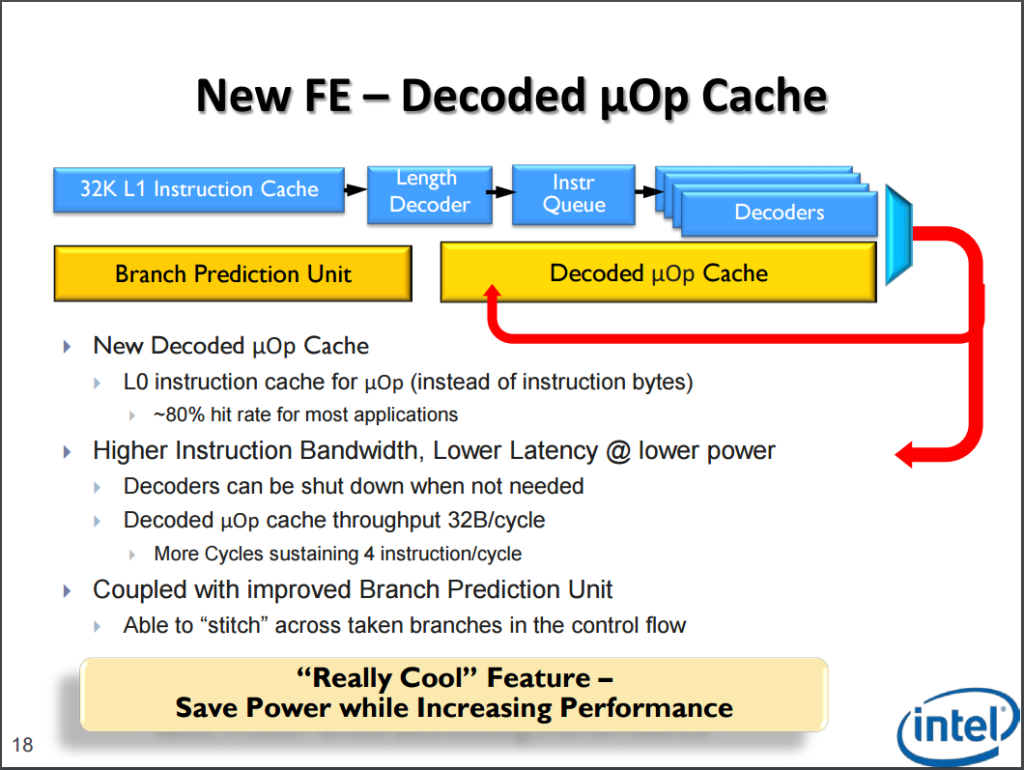
以處理器結構來說,Sandy Bridge 的主要進化是出現在前端的指令解碼、分支預測的部分,SNB 架構處理器的前端增加了一個用於儲存已解碼指令 (microOPs) 的快取 (L0 快取),可以在許多情況下不需要將已解碼的指令重跑一次解碼流程,從而獲得一些性能提升,並且可以在不需要的時候將解碼電路暫時關閉以節省能源,再輔以重新設計過的分支預測電路,在前端部分的性能因此有了一定幅度的提升。
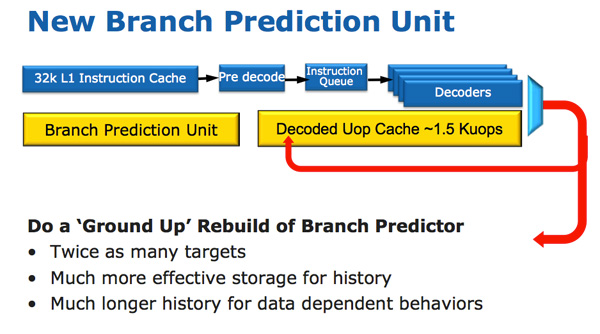
具體的改進內容由於牽涉計算機組織的專業知識與需要相當大的篇幅,因此本篇暫時不談,Intel 官方宣稱新設計的分支預測電路可以提供兩倍多的追蹤目標、可以存放更多的歷史數據以利進行更準確的分支預測。
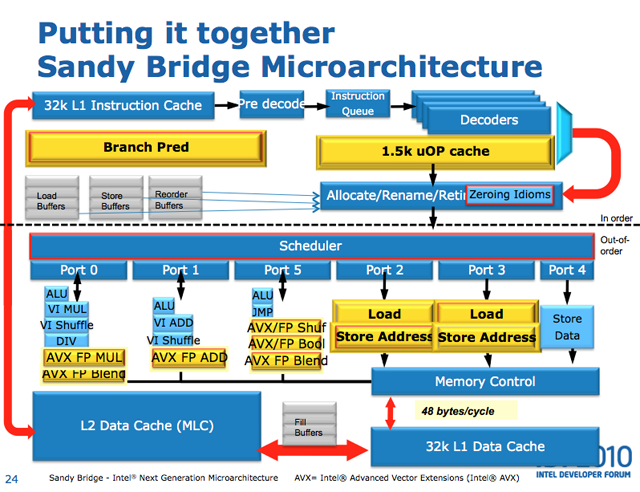
至於後端的改變就不是那麼明顯了,主要大概就是新增了 AVX 指令集,將對操作數的支援拉高到 256-bit 吧。





