











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











Table of Contents
記憶體的組成結構
接下來這個主題可能對絕大多數人來說都比較陌生一些,因為如果不是在裝載大量記憶體 (逼近支援上限的時候) 的伺服器上,近年來其實我們很少在意這件事情,畢竟通常而言,只要制式跟速度挑對「插上去就會動了」,不過為了讓這章節的內容更加充實,所以我還是把這段納進來了。
記憶體組成的階層觀點
是的沒錯,又是階層,在電腦當中真的有很多東西是一層一層堆疊起來的,而記憶體也不例外,大致上可以從大到小分成 NUMA 節點 (Node)、記憶體通道 (Memory Channel)、記憶體模組 (DIMM)、Rank、記憶體顆粒晶片 (Memory Chip)、Bank、欄位這些階層。
NUMA 節點 (Non-Uniform Memory Access)
NUMA 節點這東西基本上要複數個討論起來才有意義 (只有單一一組的時候就是 UMA 嘛),然而直到目前為止,Intel Core 家族全系列都只由 1 個 NUMA 節點組成 (核心數不夠多而且只能裝一顆所以也沒特別 NUMA 分群,消費性作業系統也不支援對 NUMA 架構的優化),所以如果你對伺服器沒甚麼興趣的話,跳過這段也可以。
以電腦發展史來說其實 NUMA 架構算是蠻新穎的概念,要解釋非統一記憶體存取 (NUMA) 架構是甚麼東西之前我們得從「還沒有 NUMA 支援時的電腦」開始看起,以往電腦使用的統一記憶體存取 (UMA) 架構其實還蠻直覺的,由一條中央匯流排負責處理器與記憶體之間的所有資料交流 (有點像高速公路),架構圖大致上是長這樣 (這樣的設計又稱為對稱多處理器架構 Symmetric Multi-Processor, SMP):
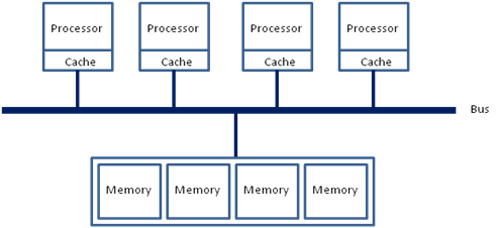
當然這樣做的缺點也很顯而易見,那就是中央匯流排的負擔會很重,因此隨著處理器的數量增加 (核心或實體方面都是) 與處理器、記憶體的速度越來越快,要建造一條足以承擔起所有處理器與記憶體之間資料交換的匯流排就變得很困難,而且會產生不必要的延遲 (因為每個處理器存取資料所要耗費的時間都一樣,儘管資料可能是放在距離要求資料的處理器距離很近的地方也是如此,延遲時間將「統一」為最長的延遲)。

為了解決這樣的問題,所以就產生了這樣的想法:那我們就把記憶體分塊,每個處理器各持有一些就好啦?(有點類似每個處理器的專屬快取記憶體) 如此一來設計匯流排就簡單了 (要連接的東西變少,速度也可以更快),主幹匯流排也就不需要承受那麼大的負擔了,但這世界往往並不如人們想像得那麼容易,這樣的設計雖然在「資料正好就在與需求處理器緊連的記憶體上」時性能很好,但如果資料在其他處理器附近的記憶體呢?那就得繞一大圈才有辦法拿到資料了,所以最後在現今的電腦設計上,是採用將兩種辦法混在一起用的折衷方案,也就是 AMD 早在 2003 年的 Opteron 中就開始使用,而 Intel 從 Nehalem 架構才開始採用的 NUMA 架構。
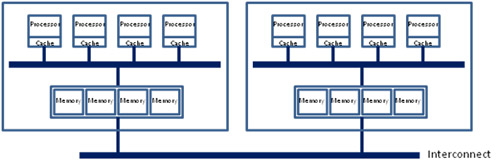
折衷方案的思維很簡單,我們就將幾個處理器劃為一組,而且讓每組都長得像 UMA 架構,然後使用可以彈性增減的高速互聯匯流排 (以 Intel 來說是 QPI,AMD 則是 HyperTransport) 將各組連接起來,就可以同時具備兩種做法各自一部分的特色了,上圖中的一個大藍色框就是一個 NUMA 節點,其中可能包含多個記憶體控制器,並管理多個記憶體通道。
不過呢還有一個問題,當作業系統不支援 NUMA 架構的時候,受制於存取策略不是為了 NUMA 架構而設計,性能表現很有可能比 UMA 架構設計的狀況下還要更糟,而且 NUMA 架構的群組要怎麼分配才能達到最好的性能也是一門很大的學問。





