











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











如果你還記得我在 5-18 當中解釋 NVIDIA 為何要將傳統的 3D 向量 + 1D 純量處理單元拆成一大堆 1D 純量處理單元的話,當時我說是為了讓電路中的運算單元可以被彈性的充份利用,從而避免在處理只需要 1D 純量或 2D 向量時運算單元當中有電路閒著沒事做的問題,或許你會想問為何即便如此 ATI 還是選擇了傳統的做法,實際上是因為 ATI 選擇了另一種稱之為 Very-Long Instruction Word (VLIW) 的實作方法的關係,這種作法讓 ATI 的 GPU 實質上也變得跟 NVIDIA 一樣,可以將這 5 個運算單元分開運用 (只是做法顛倒而已)。
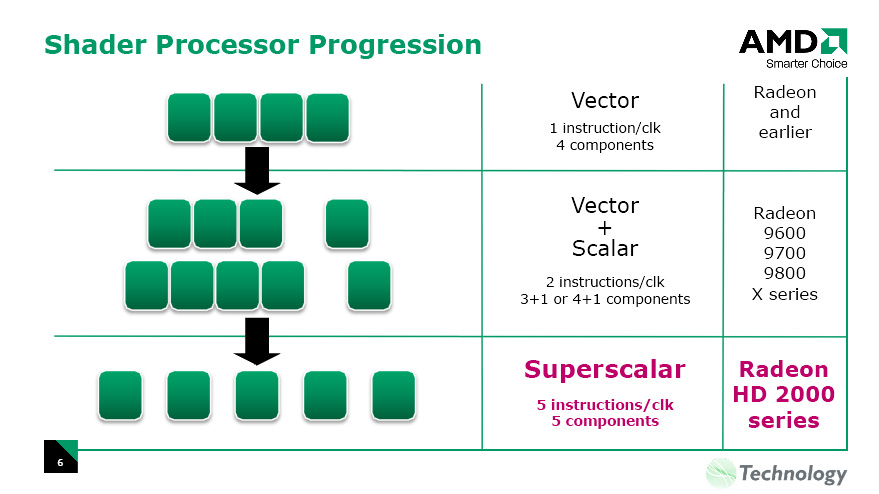
VLIW 的運作原理籠統上可以被視為將多個短指令合併為長指令從而避免造成資源的閒置與浪費 (當然也是要付出代價的,前端處理電路與分支執行電路都會變得複雜,而且對性能的影響程度也會吃重,而且只有沒有相依的指令才能被合併),實際上 NVIDIA 與 ATI 的做法之間並沒有明顯的優劣,前者有著相對來說設計單純、容易拉高時脈且高效率但會造成電晶體與連線數量大幅成長的問題 (畢竟每個純量運算單元都要有自己的輸入與輸出),後者則是提升流處理器數量的困難度相對較低 (整組共用一個輸入與輸出) 但若 VLIW 成效或合成成功率不彰就會直接導致性能低落,而且時脈拉不上來。哪種架構較優則端視實際遇到的遊戲所發出的指令如何編排與 VLIW 合成指令的成功率有多高、判斷指令相依性的能力有多強 (這跟驅動程式與 Ultra-Threaded Dispatch Processor 是否成功有很大關係,熟悉 AMD 與 ATI 的人應該都知道當年 ATI 的驅動程式功力有多差吧?) 而定。

根據架構圖來說,R600 在最糟糕的情況下幾乎只相當於 64 個 NVIDIA 架構中的 SP,但如果排到最理想狀態的話,則相當於高達 320 個 NVIDIA 架構中的 SP,所以 ATI 的設計是否能夠成功其實取決於遊戲本身的設計與驅動程式的好壞,不過從歷史上的教訓來看 NVIDIA 綁住遊戲廠商的成功率與功力好像始終顯著高於 ATI?
Table of Contents
流處理器之亂
我們說 G80 與 G92 有數百的流處理器 (SP) 實際上由來只是從原本的數十組由 4+1 或其他組合方式拼成的運算單元拆成一堆小純量處理電路來看的結果,但在宣傳上確實可以造成不小的效果 (畢竟如同時脈戰爭一般,當時電腦規格的不成文規定就是數字小的就輸了)。
為了避免在行銷上輸給 NVIDIA,因此 AMD 即便旗下顯示晶片產品內的架構是將 5 個運算邏輯單元 (ALU) 拼起來才組成一組處理器 (共用一組輸入與輸出) 但仍然自稱自家的 R600 核心可以包含至多 320 組流處理器 (SPU),實際上這個數字也是換算出來的,由 4 組繪圖管線乘上每組 8 個子處理器,每個子處理器內又由兩套共計 10 組運算邏輯單元所組成,數量能比 NVIDIA 多那麼多的原因其實是 ATI 的每組 SPU 之間所能負責的事情其實不盡相同,例如處理三角函數等特殊計算的單元就只佔所有 SP 當中的 1/5。
不過最終這樣的做法其實造成了後來不少的混亂,實際上大約就是從這個時期開始兩家廠商之間使用的專有名詞就常有意義不同或是名過其實的情況,而且實際上在架構設計不同的狀況下比較 SP 的數量或是 ALU 的數量是沒有任何意義的。
第二代環狀記憶體通道
至於在記憶體匯流排的部分呢,R600 大致上是沿襲自 R500 系列後期產品 (R580) 的設計,但是為了降低設計不同等級晶片的難度與複雜度,在 R600 系列當中的環狀記憶體通道是採用完全去中心化的設計,因此不會再見到中央集線器的蹤影。
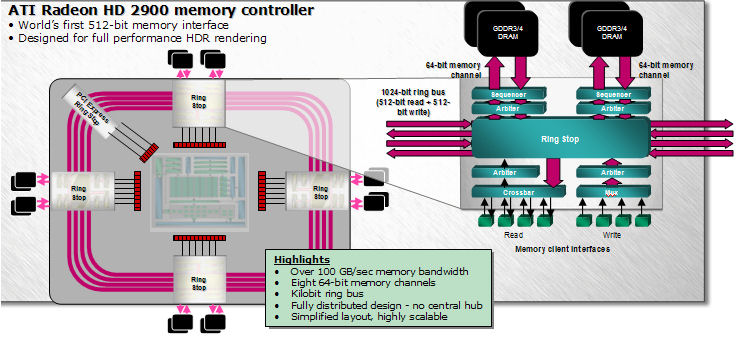
去中心化的好處是增加新的 Ring Stop (你可以想像成環狀公路上的公車站牌) 時的佈線會變得比較單純與容易,並且能夠降低電路設計的複雜度 (至少不必拉一堆線連接到中間的控制器上),但相對來說效率則沒有先前那麼高 (畢竟當時有個中央控制器隨時在找最佳路徑,而且可以透過中央控制器的路徑來跳過不需要經過的 Ring Stop),但當時的 ATI 認為這個缺憾可以透過增加記憶體界面的寬度來補足,因此最高階的 R600 足足由八組 64-bit 的記憶體控制器 (4 組雙通道) 組成,使得總對外記憶體通道寬度一舉來到 512-bit,對內部而言若算上雙向傳輸則是高達 1024-bit,突破了當時的最高紀錄。

不過最後的答案表明在 R600 上這樣的設計並不成功,太多組記憶體控制器造成的結果是延遲變得明顯許多,最終反而在性能表現上顯得差強人意,而為了增加這些東西所占去的額外晶片面積與造成的額外發熱、耗電反而益加明顯,且這意味著需要配置的記憶體顆粒數量將居高不下 (無法隨著記憶體單一顆粒的大小而簡化設計) 造成成本問題,因此之後的產品中有很長一段時間我們不會再見到記憶體通道寬度高達 512-bit 的 GPU。

除了記憶體寬度的問題之外,R600 的記憶體控制器還有另一個比較大的特色是支援了 GDDR4 記憶體,不過在歷代圖形記憶體當中 GDDR4 恰巧是命運最悲劇且採用率最低、生存年代最短的一代,有機會的話我打算在本章的結尾談談歷代圖形記憶體的演進,到時候應該會談到這部分的歷史。
材質處理單元
另一項 R600 架構相較於 R520 而言比較大的差異則出現在材質對應單元 (TMUs) 的部分,在 R600 當中 ATI 重新設計了負責處理材質貼圖的單元以支援 DirectX 10.0 當中增加的 8192×8192 材質貼圖支援與 RGBE 9:9:9:5 材質格式等要求,此外,由於 R600 的 TMU 完全獨立於運算引擎之外,是聽 Ultra-Threaded Dispatch Processor 號令做事的,因此可以在流處理器提出要求之前就先進行資料取樣等運算工作,理論上這可以提高性能。
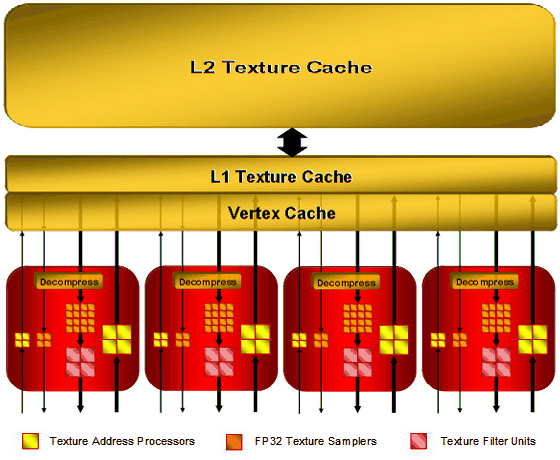
上圖是完整版大核心 R600 內的編制 (有四個材質處理模組),其中每個材質處理模組當中都包含了 8 個材質位置處理器、20 個材質取樣器與 4 個材質過濾單元 (相對於對手的 G80/G92 來說少了很多,如同 R500 系列時期一般,基於繪圖管線對性能的影響比材質對應單元來得明顯許多的觀點,ATI 在此代產品當中把 TMU 與運算單元之間的數量差距比例拉得更開了),並且連結到三層快取 (依序是頂點快取與一、二級的材質快取,這是 R600 的新規劃,ATI 在上一代產品當中並沒有將材質快取分為兩層,而且快取大小也小很多,這是為了引入統一渲染器架構而做的配套改變,以滿足新的運算單元需要的資料存取效率),如同上圖當中可以看到的,在 20 個材質取樣器當中有 4 個是不經過材質過濾單元的,主要用於處理頂點,而材質位置處理器也可分為兩組,一組連結到材質快取,一組則是負責處理頂點。
渲染輸出單元 (ROP)
至於渲染輸出單元的部分改變就不是那麼明顯了,大致上是沿襲 R500 系列所使用的架構而來,主要的改進出現在材質壓縮技術的部分,在 R600 當中可以使用更高壓縮比例的模式。
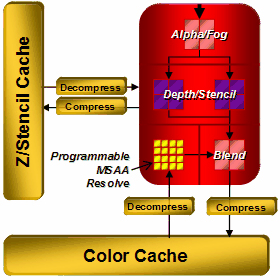
R600 中的 ROP 可分為 16 個多重採樣子單元 (主要用於處理多重採樣反鋸齒 MSAA)、4 個用於處理 Alpha/Fog 的子單元、8 個用來處理 Z-buffer 與 Stencil Buffer 的單元、4 個融合子單元,儘管相對於對手的產品來說數量較少,但由於 ATI 的晶片並不像 NVIDIA 有在內部進行高低分頻處理,因此在 ROP 的部分 ATI 晶片的運作時脈比 NVIDIA 高出不少,理應足以彌補數量上的不足。
R600 核心

接下來讓我們把焦點移回到產品本身吧,基於 Terascale 1.0 的第一款產品就是完整版的 R600 核心,是 R600 系列當中規模最大的版本,包含了完整的 320 個串流處理器單元 (SPU) 與 4 組渲染輸出模組 (相當於 16 個 ROP)、4 組材質對應單元 (相當於 16 組 TMU),同時 R600 也是系列當中唯一一款繼續使用上一世代 80 奈米製造工藝的產品。

R600 在 2007 年 05 月被命名為 Radeon HD 2900 系列推出,先後發佈了 2900 XT (743/1000 MHz + GDDR4 與 743/828 MHz + GDDR3)、2900 PRO (600/925 MHz + GDDR4 與 600/800 MHz + GDDR3,搭配 GDDR3 時記憶體頻寬只有 256-bit)、2900 GT (601/800 MHz + GDDR3,但記憶體頻寬閹掉一半且 SPU 只剩下 240 個,渲染輸出模組與材質對應模組各被刪減了一組)。






