











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











Table of Contents
SIMD Array 大擴編
看到 RV770 的架構第一眼發現的不同應該就是不論數量或寬度都有著大幅成長的 SIMD Array 吧?還記得 R600 與 RV670 當中的編制是每個 SIMD Array 當中有 16 組運算單元,而每個運算單元中各有 5 個 ALU 電路 (被 AMD 命名為 SMU),因此 RV670 與 R600 有高達 320 個 SMU。

然而在 RV770 當中,原本至多只有四組的 SIMD Array 一口氣被擴編到了十組之多,而且每組當中的運算單元數量也從原來的 16 組翻倍變成高達 32 組,因此 RV770 的 SMU 數量一舉提高到了驚人的 800 個,但在電晶體數方面的成長並沒有想像中來得明顯 (實際上這正是上篇我提及 ATI 選擇此種作法的優勢,在 SIMD Array 數量擴編之後就變得很明顯了,可以在不需要大量增加電晶體數量與大幅提高電路複雜度的狀況增加大量的 SMU,而 SMU 又直接影響了運算性能,因此對於 Terascale 架構來說提昇 SMU 的數量是增進效能最直接的路徑。
新的材質單元
RV770 當中材質單元的規劃也有調整,在 RV670 當中 ATI 是採用一組 SIMD Array 對上一組材質單元的配置,而在 RV770 當中也依然如此,因此 RV770 的材質單元數量同樣從六組大幅增加為十組,但最主要的差異其實出現在快取的部分。

以往在 RV670 當中,材質單元之間是沒辦法互相溝通的,每組材質單元對應到一個 SIMD Array,彼此之間並沒有任何管道互聯,但在 RV770 當中除了原先每個 SIMD Array 自有的本地儲存區之外,還增加了一個共用的全域儲存區,SIMD Array 與材質單元可以在那裏交換資料。
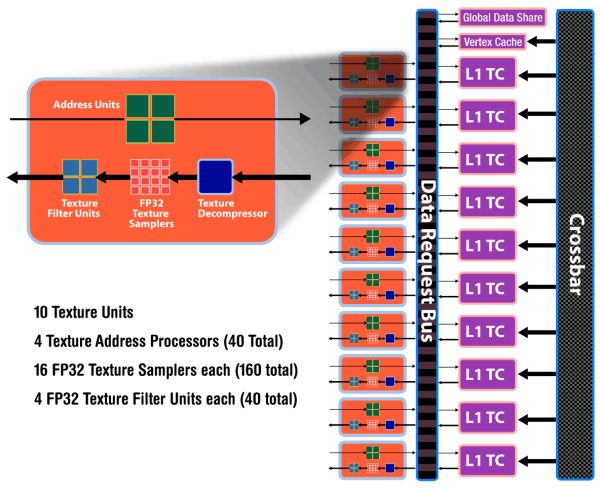
不過值得注意的是在 RV770 當中材質單元的內容被簡化了 (上圖),並且取消了原先的第二層大型共用快取設計 (下圖),改為使用 Crossbar 的方式將每個材質單元的快取記憶體高速相連,這使得新的架構看起來反而跟 NVIDIA 的做法比較相似,儘管在新設計下的單一材質單元本身功能被弱化,但由於數量大幅成長且運作時脈亦有提高,最終的結果反而是性能比前作好上許多。
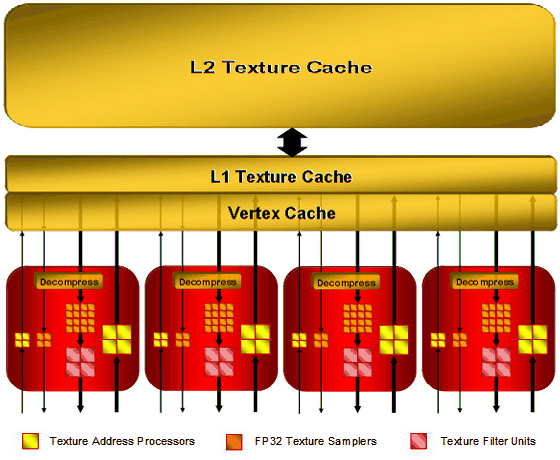
此外,在 RV770 當中材質單元與材質快取之間的連接頻寬也增加了一倍之多。
砍掉重練的記憶體架構
從架構觀點來看 RV770 這一世代改變最大的地方應該就是記憶體階層的規劃方式了,從 R520 開始一路用到 RV670 的環狀記憶體通道整個被砍掉重練,回頭採用了過去比較常用的 Crossbar 架構,將記憶體、L2 快取與 L1 材質快取全部運用中央的 Crossbar 連接在一起,並將原先與 L1 材質快取放在一起的頂點快取整個分離開來,運算單元的部分則使用 Data Request Bus 來與這些記憶體溝通。
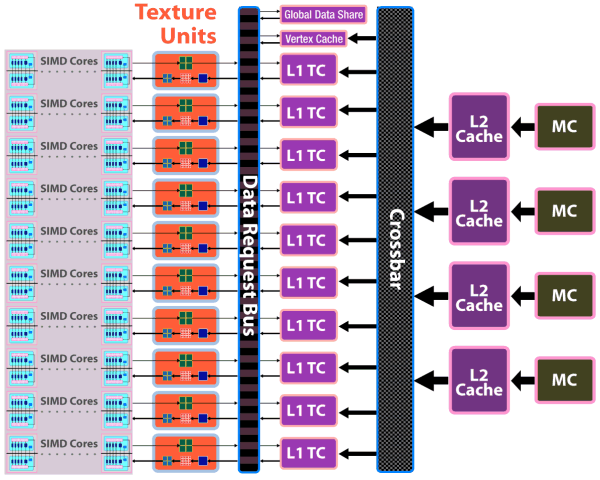
這樣的做法解決了環狀記憶體通道線路過於複雜的問題,讓 AMD 得以把更多空間用於增加更多的 SMU 上,而且 Crossbar 技術也比較成熟。
渲染輸出單元 (ROP)
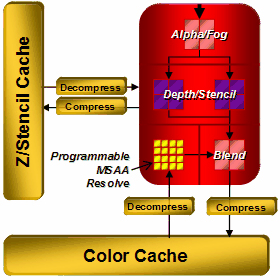
RV770 的 ROP 也獲得了大幅度的性能改進,儘管數量上並沒有增加,但卻透過架構與內部規劃的改進 (負責處理深度與 Stencil 的電路數量加倍,見下圖) 使得在大多數模式下 RV770 的 ROP 性能比起前作要高出兩倍之多,並且可以在不需要 SIMD Array 分擔運算的情況下處理 MSAA 反鋸齒。
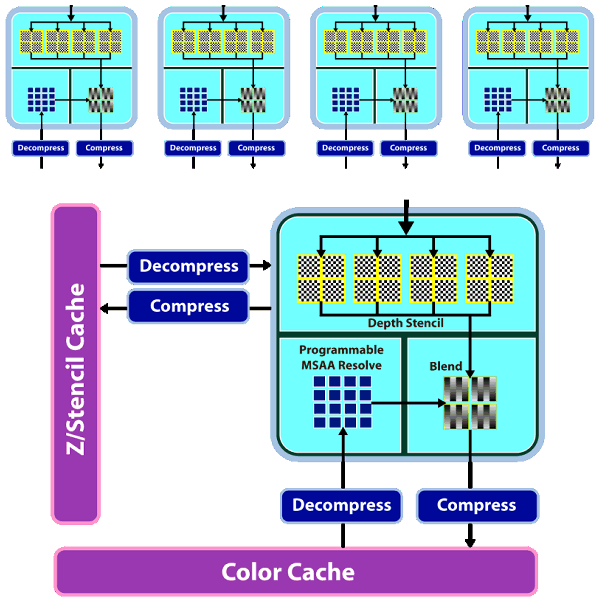
不過新的編制看起來跟 NVIDIA 的做法越來越相似了就是。





