











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











由於篇幅過長因此站長後來決定將本文拆分為上、下二篇,本篇為「上篇」,主要介紹 DirectX 11 引入的新特性與 AMD 方面推出的世界第一款 DirectX 11 GPU 與對應的 Terascale 2 架構 (Evergreen 家族)。
接下來時序來到了 2009 年,在這一年當中對於 GPU 界來說最為重要的事情就是 Windows 7 的誕生帶來了 DirectX 11.0,距離上次大改版 (DirectX 10.0) 已經經過將近三個年頭之久。

Table of Contents
DirectX 10 「補完計畫」
儘管 DirectX 11.0 跳入了下一個大版號,但實際上 DirectX 11.0 並沒有帶來甚麼非常大的變革,充其量就是 DirectX 10.x 的性能改進與功能補完罷了 (其實微軟如果將其命名為 DirectX 10.5 也不會太奇怪),DirectX 11 主要帶來了五個面向的改進,接下來我會逐項說明。

Shader Model 5.0
首先看到的是每次 DirectX 改版或多或少都會調整到的 Shader Model,由於統一渲染器架構已經在 DirectX 10.0 時代成形,因此這次 SM 5.0 的更新內容其實很少,主要出現在五個面向:
- 各類 Shader 指令整合得更加緊密。
- 新增對 Compute Shader 的支援 (實際上後來也被追認回 DirectX 10.x 規格中了)。
- 新增對 Hull Shader、Domain Shader 的支援 (之後在談 Tessellation 的時候會提到)。
- 新增數個額外指令支援。
- 將雙精度支援納入標準規範。
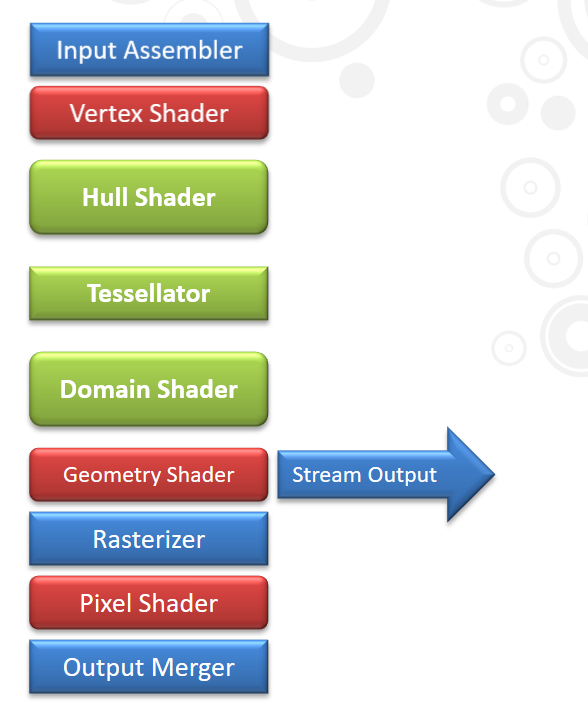
至於在規格參數本身的部分,SM 5.0 則沒有帶來甚麼明顯的變化。
DirectCompute 11
在前面的 5-17 當中我們曾經談過 GPGPU 通用圖形運算的崛起與發展,當時我就有特別提到 DirectCompute 這東西了,因此關於 DirectCompute 的緣起與發展我就不再重述,在這裡只提一些 DirectCompute 11 與 DirectCompute 10 之間的差異比較。
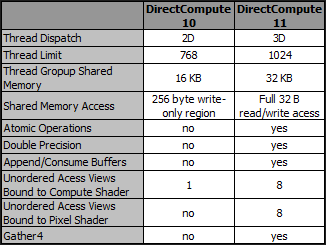
DirectCompute 在 DirectX 11.0 當中最重要的改進應該就是執行緒方面的限制獲得了很大幅度的放寬,支援的指令派遣方式從 2D 提升為 3D (可以提高效率),執行緒共用記憶體的大小也翻了一倍,並且在共享記憶體存取的部分有了飛躍性的成長 (本來只有 256 bytes 而且僅供寫入,DirectCompute 11 則一舉提高為 32 KB 且可寫入與讀取),並且加入對 Atomic Operations 的支援 (因此實際上 DirectCompute 只有在 DirectX 11 後的版本中才比較有實用價值,如同在 5-17 中我提過的 DirectCompute 10 基本上是微軟後來為了不甘願落後於 CUDA 與 OpenCL 發展才「追認」的版本,在最初的 DirectX 10 規格當中是沒這東西的)。
多執行緒優化
以往的 DirectX 基本上主要應對的是單 CPU 的系統配置,並且只提供相當有限的多執行緒支援 (舉例來說,以往 DirectX 內所謂的多執行緒指的是渲染一個執行緒、物理特效一個執行緒、材質貼圖一個執行緒,而不是我們認知中一件事情可以開一堆執行緒的做法)。
不過隨著雙核心處理器出現的機率越來越高,這樣的方式顯然無法充分利用現代處理器的性能,而且隨著 GPU 性能的提升 CPU 已經開始漸漸出現「餵不飽 GPU」的狀況了,因此勢必得針對這個問題進行依些修正才行,而這一切的關鍵在於非同步 DirectX API 呼叫的支援能力。
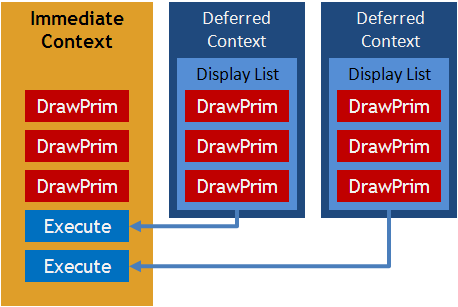
DirectX 11.0 使用的做法是從驅動程式與 API 方面的調整來允許開發者進行非同步 API 呼叫與非同步資源分配,並且如同上圖一般加入對多重 Context (情境內文) 的支援,分為一個主要 (Primary) Context 與數個次要 (Secondary) Context (由程式開發者定義),其中 Primary Context 又被稱為 Immediate Context,顧名思義這個 Context 才是 GPU 當下即時在處理的 Context,但在 DirectX 11.0 架構當中允許將 Secondary Context (又叫做 Deferred Context) 的工作對應到 Immediate Context 中執行,從而達成多重執行緒的效果。
材質壓縮
第四個 DirectX 11 改進重點則是在材質壓縮 (Texture Compression) 技術的部分,一直以來材質貼圖都是占用顯示記憶體空間最大宗的一類,因此材質壓縮技術的好壞對於 GPU 能處理的資料量與速度至關重要 (遊戲解析度也逐步增長到 1080P,甚至是未來的 4K,每次解析度上漲需要處裡的貼圖大小就變得更加驚人)。

在 DirectX 11 當中材質壓縮技術的改進主要可分為兩個方面,首先是首次對 HDR 影像材質引入了材質壓縮技術 (稱之為 BC6 壓縮),可以將 HDR 影像資料以 6:1 的比例進行壓縮,並且支援硬體加速解壓縮功能。

至於在一般的 LDR 影像材質的部分也引入了新的壓縮機制,稱之為 BC7 的新壓縮模式可以將 8-bit LDR 影像材質資料以 3:1 的比例進行壓縮,而壓縮前後的失真情形比起以往使用的 BC3 壓縮模式要來得好上許多。
(BCx 實際上是 Block Compression,區塊壓縮的意思,從以往的 DXTC 改名而來,到 DirectX 11.0 為止一共有 BC1~BC7 七種不同的壓縮模式,由於這部分內容太細節所以我就不特別提這七種壓縮模式的差異了。)





