![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











強化雙精度浮點性能
在進行一般圖形應用運算 (例如遊戲) 的時候通常以單精度為準 (畢竟單純算圖其實不需要那麼精準),所以絕大多數的 GPU 都以強化單精度運算性能為主要目的 (其實很理所當然,畢竟單精度運算單元比起雙精度運算單元來得簡單很多,這意味著同樣面積下能塞入更多單精度運算單元,而更多的運算單元幾乎就意味著更高的性能,因此當然要選擇塞更多的單精度浮點單元,甚至犧牲雙精度性能也在所不惜)。

剛剛提過 NVIDIA 在 GTC 2012 上同時發佈了兩款運算卡 (Tesla K10 與 Tesla K20),其中 Tesla K10 的部分官方宣傳強調為「高達三倍的單精度浮點運算性能」,適合影像、訊號處理用途,其實這張 Tesla K10 就跟 GeForce GTX 690 一樣是基於兩顆 GK104 核心而來,因此同樣是強調單精度性能重於雙精度性能的產品 (基本上在 GK104 上雙精度運算性能只有單精度的 1/24),因此本質上來說其實 Tesla K10 比較不像「正規」的運算卡,硬要說的話其實反而比較像是 Quadro 系列的繪圖卡。

為什麼這麼說呢?實際上通常我們在談「運算」領域的時候比較強調的其實是專業運算、科學運算、金融運算這類比較重視精準度的用途,而這類用途通常除了單精度浮點運算之外也會有很多雙精度浮點運算的場合,在這種狀況下 Tesla K10 的設計是肯定是不敷使用的,這也就是為什麼用於組成 Tesla K20 的 GK110 核心勢必得大幅強化雙精度運算性能的原因。
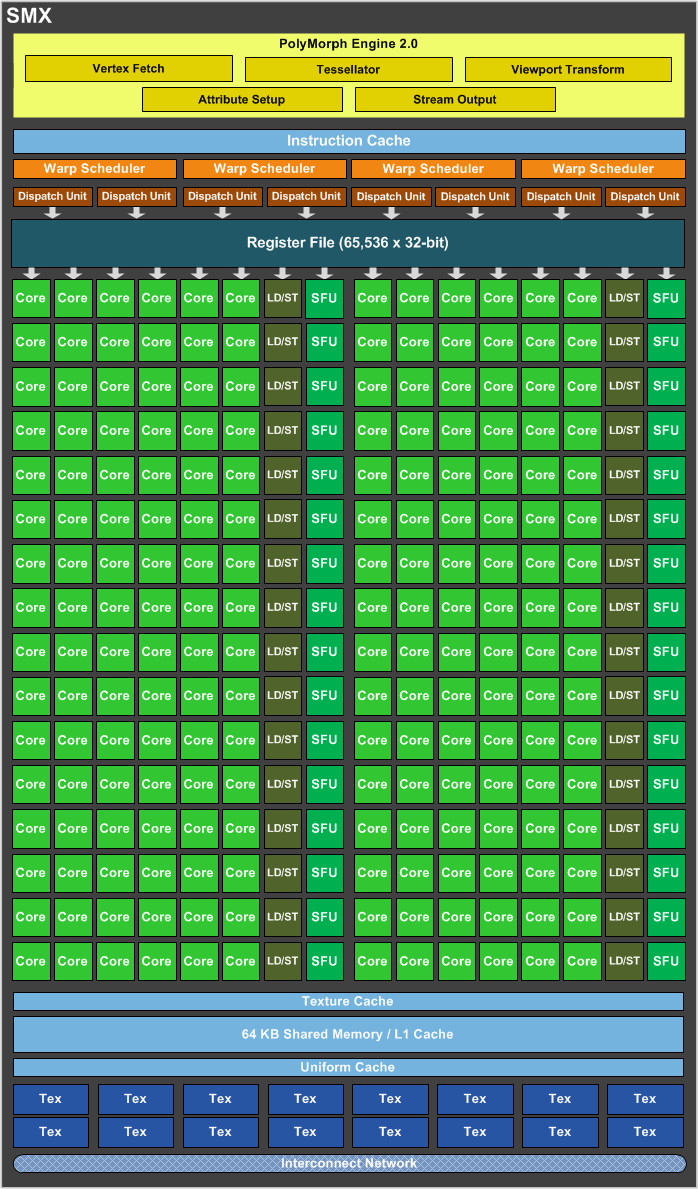
至於具體的做法呢,要解釋之前我們得先回顧 GK104 的 SMX 布局 (上圖),實際上除了圖上可見的 192 個 CUDA Core 之外 NVIDIA 還在 GK104 的每組 SMX 之中安排了 8 個專門負責處理雙精度的運算單元,而在 GK104 上單雙精度性能如此懸殊的原因主要就來自於這裡 (數量相差 24 倍,實際上 GK104 的雙精度浮點運算性能 190.7 GFLOPS 就是單精度性能 4577 GFLOPS 的 1/24),然而前面提過這樣的狀況在正規運算用途中肯定是不夠的,所以到了 GK110 每組 SMX 的佈局就變成下面這樣。
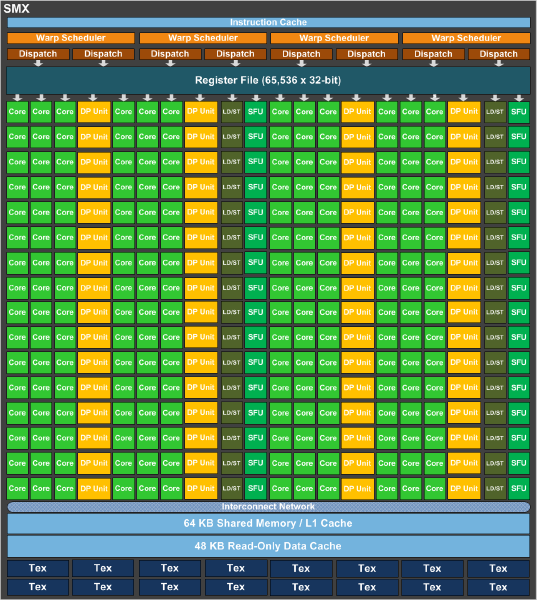
沒錯,黃色方塊 DP Unit 就是 GK110 大幅增加的雙精度浮點運算單元,光是數量上就從 GK104 的 8 個一口氣提高到 64 個了,足足是 GK104 的八倍之多,因此在 GK110 上雙精度浮點運算 1175 GFLOPS 性能實際上大約是單精度浮點運算性能 3524 GFLOPS 的 1/3。
除此之外為了解決在性能提升之後平均每 GFLOPS 分配到的資料頻寬減少的問題,SMX 內的貼圖快取 (Texture Cache) 在進行通用運算任務時現在可以作為「唯讀資料快取」使用,並且將 GK110 每個執行緒所能支援的暫存器數量由 63 個提高為 255 個 (因此在 NVIDIA 的官方文件中,GK110 的 Compute Capability 等級是 3.5 而不是 3.0)。
GPU Boost 2.0
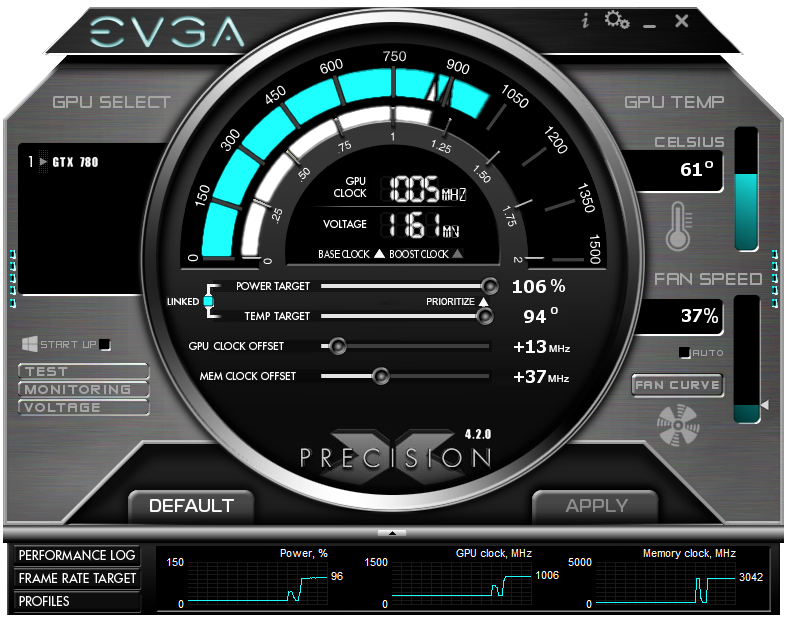
另一項在 GK110 當中引入的改進則是第二代的 GPU Boost 技術,如果你了解 GPU Boost 1.0的運作方式的話,其實 GPU Boost 2.0 的改進方向並不是甚麼很複雜的東西,還記得前面提過 GPU Boost 是以「Power Target」,也就是 GPU 耗電量作為動態調整時脈的依據嗎?

而第二代的 GPU Boost 技術其實就是把動態調整時脈的依據變得更多樣 (說穿了就是把溫度也納入調整依據) 而已,所以支援 GPU Boost 2.0 的 GPU 在運作時脈上會更難預測 (因為 GPU Boost 1.0 的電壓上限 Vrel 是由 NVIDIA 預先定義,而 GPU Boost 2.0 的 Vrel 則會根據溫度自動調整)。
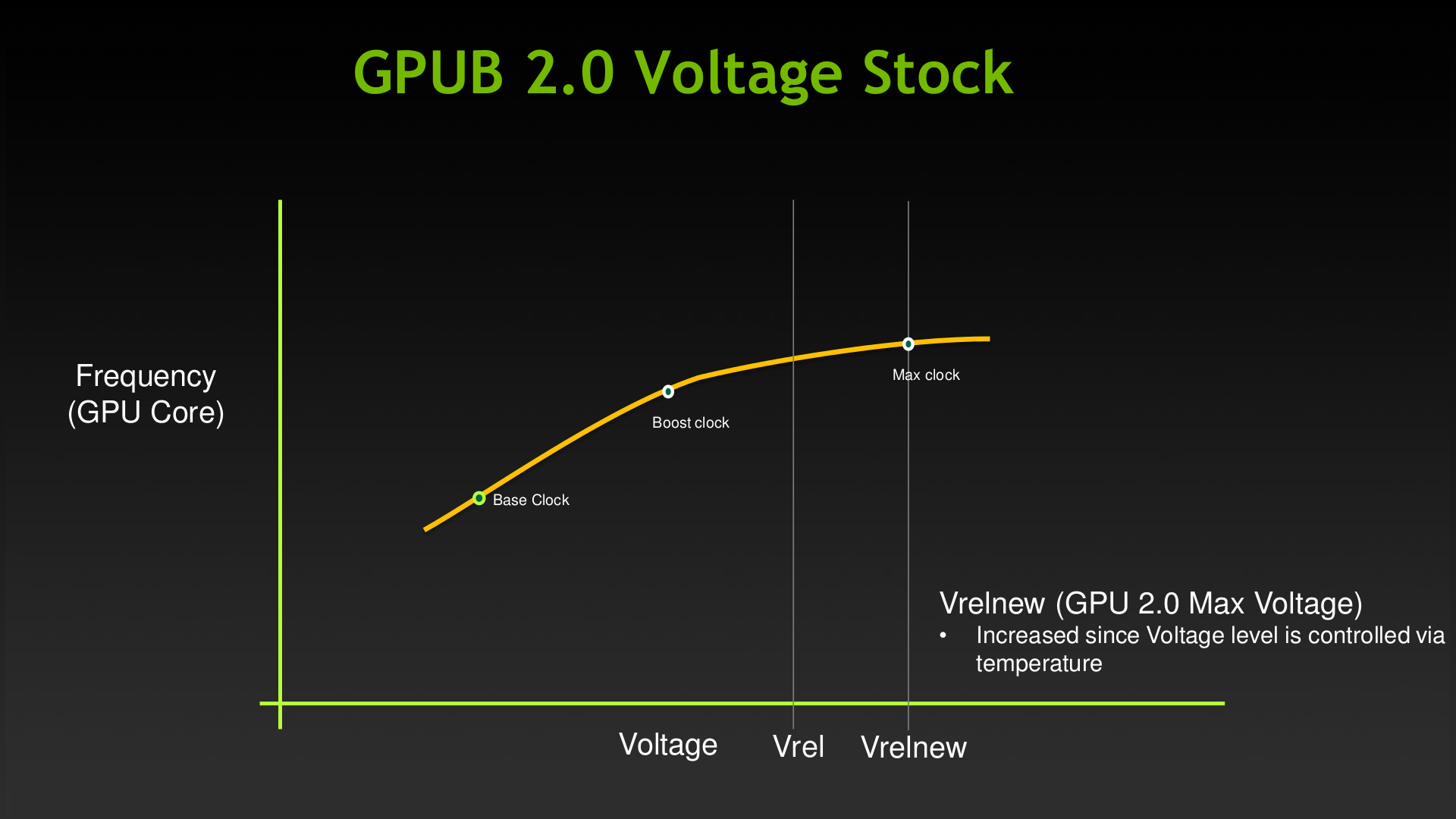
這樣的結果在大多數情況下會允許顯示卡的 Vrel 上限動態調整到超過原先 NVIDIA 定義的 Vrel,所以通常可以允許顯示卡動態超頻到更高的時脈。
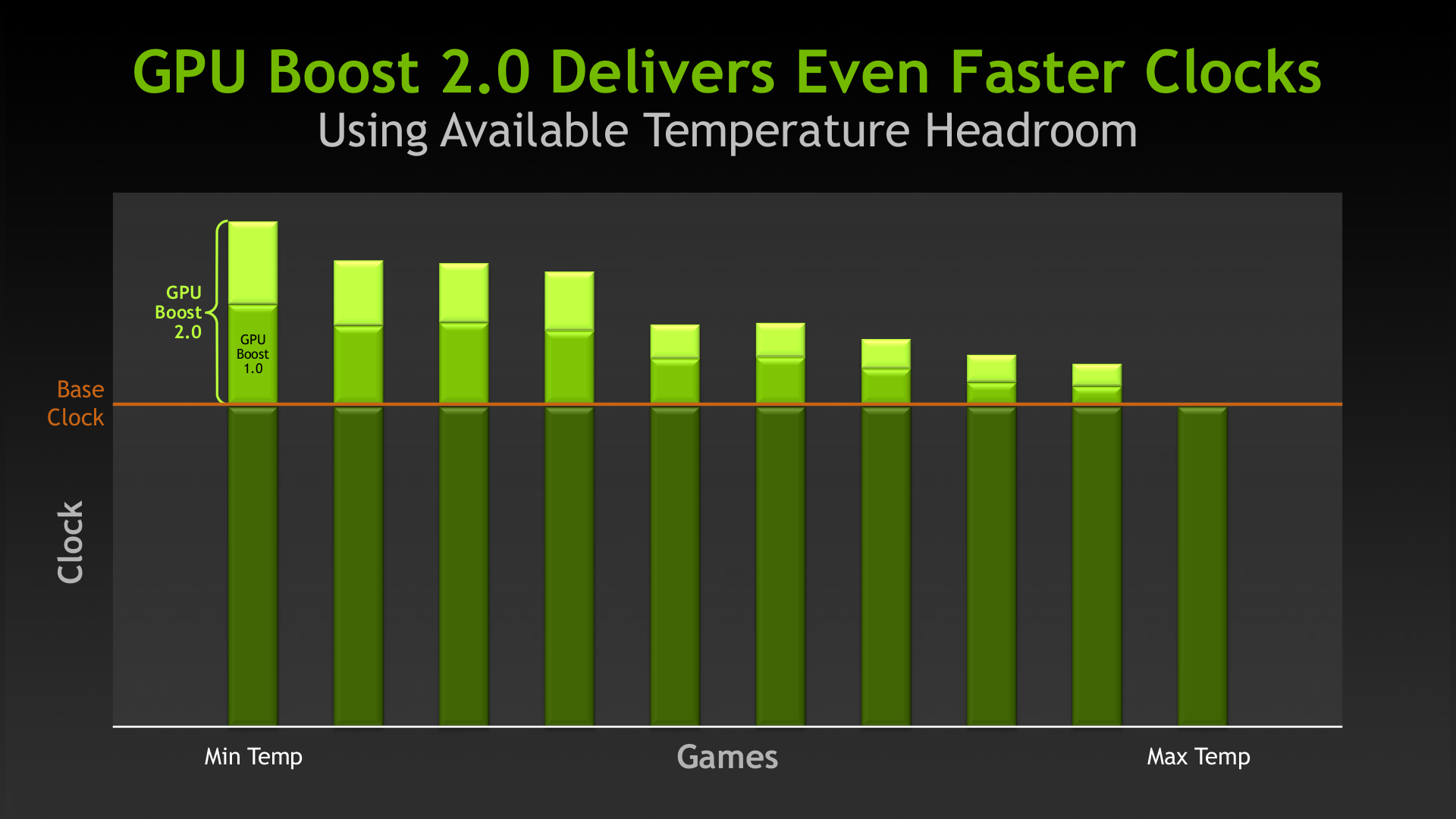
然而與 GPU Boost 剛被引入的時候類似,由於參考標準不再只侷限於 Power Target,因此在 GPU Boost 2.0 之後超頻設定時的調整依據將變成 Power Target 與 Temp. Target 共同參照,並且允許使用者決定要使用「溫度先決」或「耗電量先決」模式。