![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











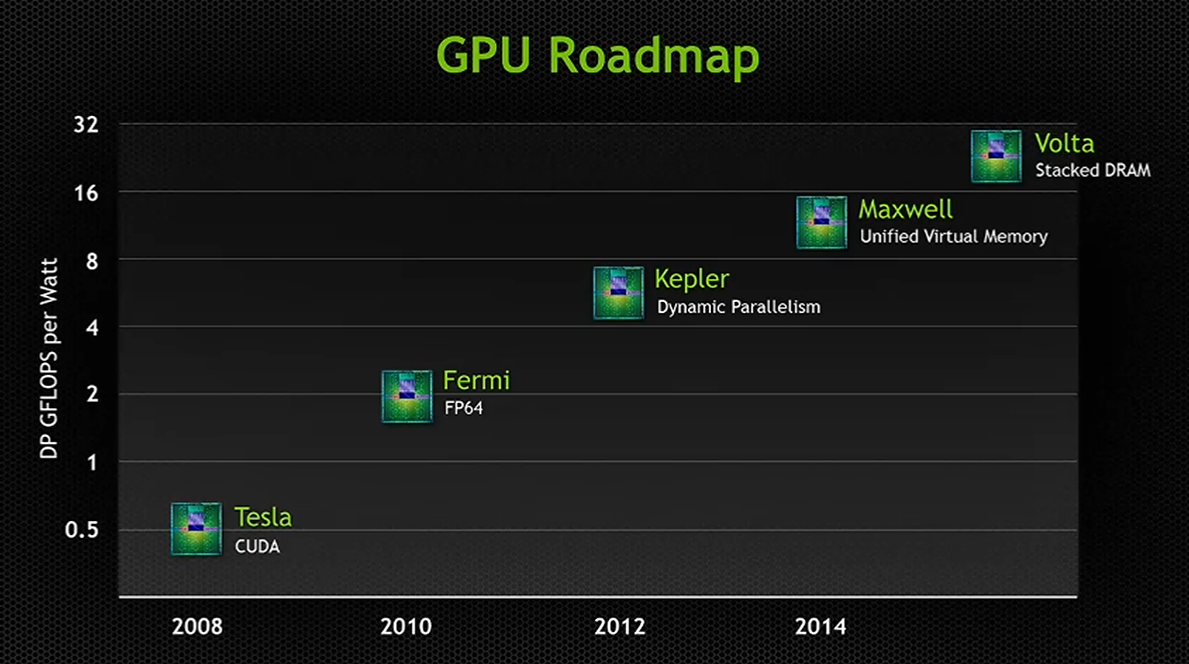
NVIDIA 陣營在 Kepler 架構之後負責接檔的是 Maxwell 架構,由於 Maxwell 架構本身的改進方向與架構設計跟 Kepler 架構的相似度其實還蠻高的,所以接下來我打算就直接接著講 Maxwell 架構。
或許你會好奇為什麼我不像之前那樣先講 DirectX 12.0,其實是因為 DirectX 12.0 基本上沒有帶來太多架構上的改變,相較於 DirectX 11.x 來說其實 DirectX 12.0 主要的改進內容只是針對多執行緒運算方面進行大量的優化工作,因此原有的 DirectX 11.x GPU 只需要更新驅動程式與應用程式就可以支援 DirectX 12.0 帶來的絕大多數新特性,所以沒有太多值得額外介紹的內容 (當然這不代表 DirectX 12.0 沒甚麼重要改進,只是大多數是演算法優化,跟硬體沒甚麼關係而已),而且 NVIDIA 也沒有在 Maxwell 架構硬體中實作那些功能,因此不會在本篇提及。
Table of Contents
NVIDIA Maxwell Microarchitecture (第一代)
- 推出日期:2014 年 02 月 (GM107)
- 所屬系列編成:GeForce 700 系列、GeForce 900 系列
- API 支援:DirectX 12.0、OpenGL 4.5、OpenCL 1.2、Vulkan 1.0
- Shader Model 支援:SM 5.0
上回我們提到 Kepler 架構是 NVIDIA 由一味追求規模、性能提升轉為強調效率提升為主要策略的開始,而 Maxwell 這一世代實質上就是以 Kepler 架構為基礎繼續往這個方向發展之下的產物,因此在架構本質上與 Kepler 架構之間的差異其實並不是很大,反而最明顯的差異只有內部元件組織被打散重新排列組合而已。
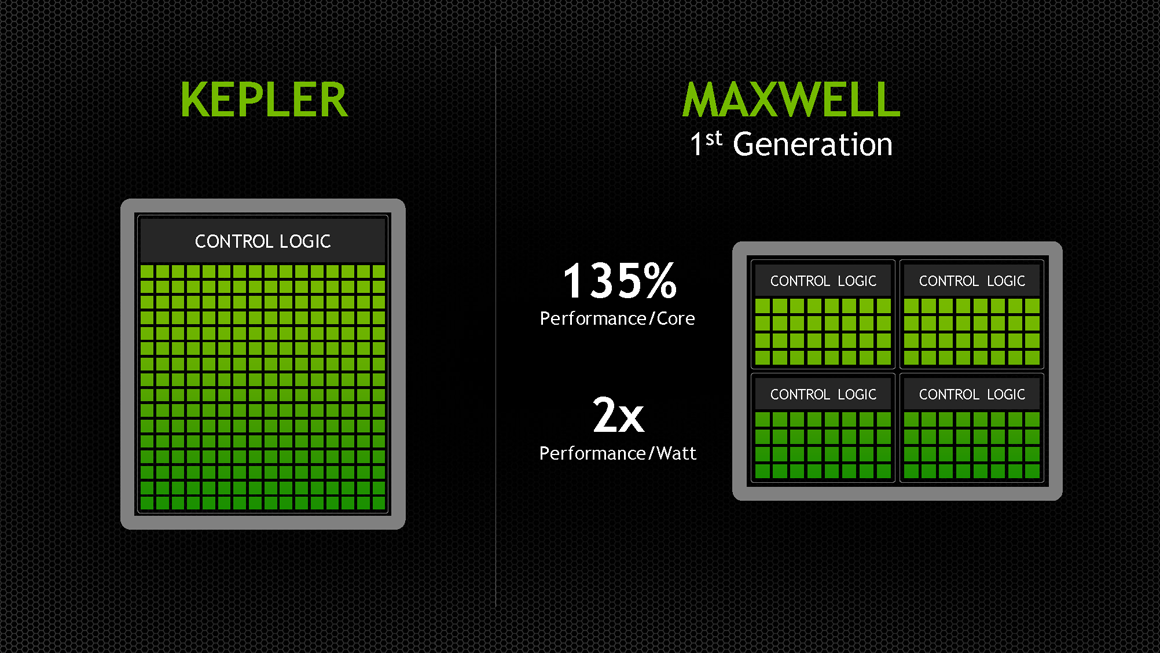
然而這正是 Maxwell 架構最有意思的地方,只是重新排列組合而已居然能讓每瓦效率直接翻倍 (Maxwell 與 Kepler 一樣都是基於 28 奈米製程,所以效率提升並不是來自於製程改進,而是 100% 純正的架構效率提升)。
打散重排的 SMX 配置
聽起來好像不太科學,究竟 NVIDIA 到底是怎麼做到的?要深入探討之前我們得從上一代 Kepler 架構的排列方式開始談起,下圖就是 Kepler 架構核心中的分組單位-SMX 的組成圖:
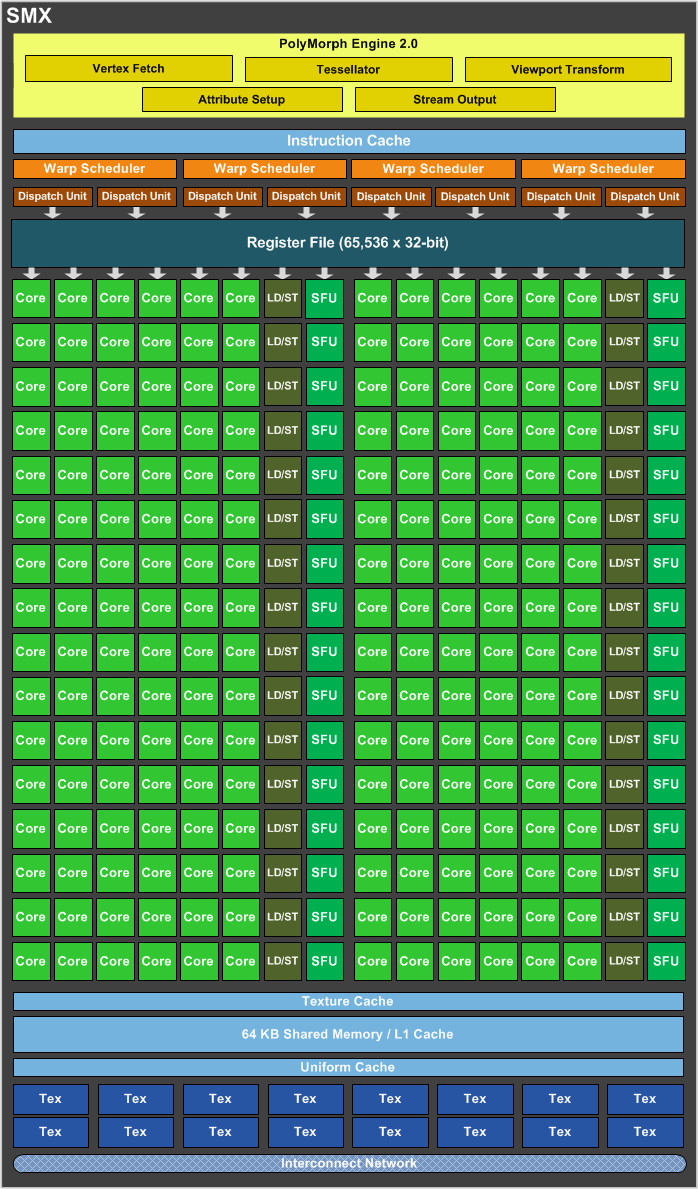
基本上 NVIDIA GPU 架構內的基本組成-SMM (或是 Tesla / Fermi 時代的 SM) 大抵上可分為三個組成部分:控制電路 (指令快取、Warp Scheduler 等)、運算單元 (CUDA Core、FP Unit、SFU、LD/ST) 與材質渲染 (底下的 Tex 材質單元)。先前曾經談過 Kepler 架構的性能提升主要來自於 CUDA Core 的配置數量大幅提升 (從每組 SM 32 或 48 個大幅提高到每組 SMM 192 個),但是單一 SMM 模組內的 CUDA Core 數量大幅提升就意味著每個 CUDA Core 所能分配到的控制電路與材質渲染資源也就相對大幅減少了,沒錯吧?
然而除了平均分配的資源減少之外,在實際運作中軟體也不一定能很理想的餵飽共用的控制電路,讓控制電路得以讓所有 CUDA Core 同時都有工作可以處理 (畢竟每個指令被丟進控制電路內的時間不一定剛好對上,而指令被分配到 CUDA Core 上的情形也很難預測),且在共用控制電路設計中,很難讓控制電路根據 GPU 使用率進行高效率的動態啟閉,這兩個問題很大程度的影響了 Kepler 架構在實際運作下的效率,因此解決這三個問題就成為 Maxwell 架構發展上最重要的課題了。
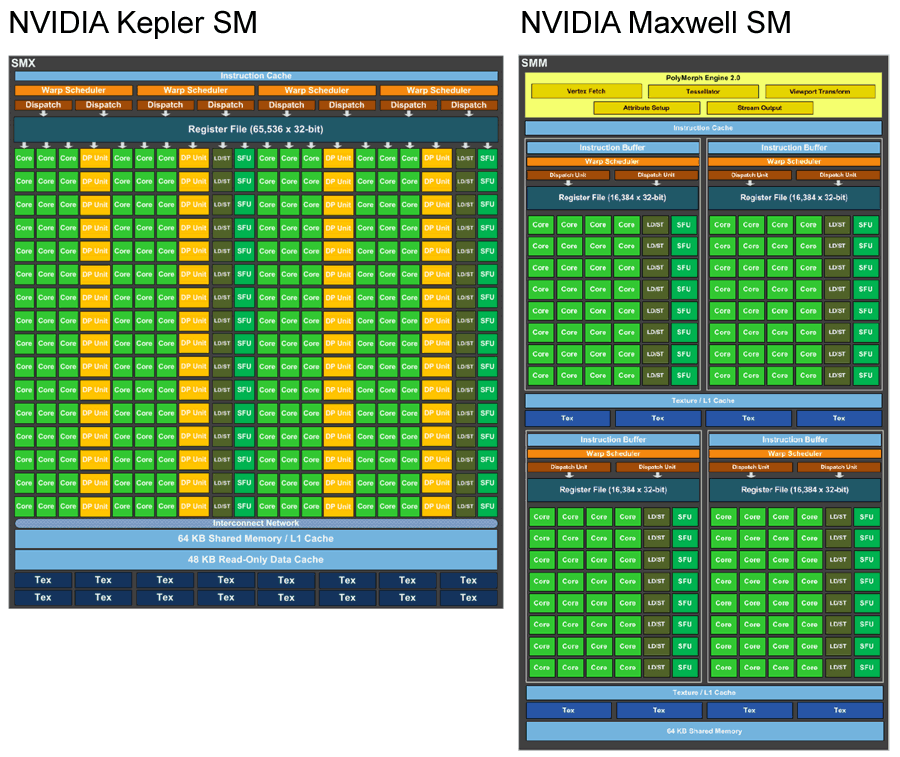
而實際上 NVIDIA 是怎麼做的呢?基本的思維是將 Kepler 的 SMM 內部再切割為 4 小塊,每一小塊各自擁有自己的指令緩衝區、排程器、Register File 等控制電路 (每小塊各自擁有 1/4,總規模實際上與 Kepler 是一樣的),並以 2 小塊為一組享有各自獨立的 L1 與材質快取、材質單元,最後這 4 小塊再以 64 KB 的共享記憶體作為彼此溝通的管道。
在這樣的設計之下四小塊各自擁有的控制電路得以不互相影響獨立運作,因此可以大幅提升 CUDA Core 資源的利用率,L1 與材質快取合併之後快取命中率也得以提高,共享記憶體所承擔的工作也變得更加單純,總和下來帶來的改善就是非滿載情形下的資料吞吐量與運算核心利用效率的大幅提高,當然性能與效率也就隨之提升了。
不過這樣的設計當然也有缺點,那就是在滿載情況底下的性能會略為減損,不過實務上會滿載的情況並不是那麼多,而減損的性能其實也並不是非常多,但卻能得到大幅簡化連結指令分派單元與運算單元之間的 Crossbar 電路來達到省電與降低控制電路所需晶片面積的效果,因此整體換算下來還是划算的 (而根據 NVIDIA 的官方說法,NVIDIA 也有做一些改進來提升每個 CUDA Core 的效率,因此一來一往最後性能還是提升了不少)。
除此之外要特別提及的是 Maxwell 內的 SMX (即相當於 Kepler 當中 SMM) 當中的雙精度浮點運算單元只有 4 個 (即 Kepler 的一半,因此 Maxwell 架構的雙精度浮點性能只有單精度浮點性能的 1/32),CUDA Core 的數量也從 192 個調降為 128 個。
快取大幅提高,記憶體頻寬縮減
另一項 Maxwell 架構的改進重點則是出現在記憶體佈局上,NVIDIA 在 Maxwell 架構當中把 L2 快取的容量從原來的 256 KB 大幅提高到 2 MB (以 GK107 與 GM107 比較的情形),讓快取可以容納更多的資料從而減少需要存取記憶體的頻率,最終達到降低記憶體頻寬需求的效果。
在記憶體頻寬需求下降之後 NVIDIA 便得以減少 Maxwell 架構當中配置的記憶體控制器數量,從而達到降低晶片面積與耗電量的效果。
That’s all…?
實質上第一代 Maxwell 在架構上的修改真的就只有 SMX 打散重排、快取增加跟記憶體通道寬度縮減 (本來我想用改進這詞,不過記憶體通道縮減好像不算改進 XD) 而已,除此之外就是一些 H.264 部分支援之類的小東西,不要懷疑,真的就只有這樣,實際上 Maxwell 架構大部分的特色 (像是動態超級解析度、第三代色彩差異壓縮等) 都要等到後續的第二代 Maxwell 架構才會出現,而當年 NVIDIA 在 Roadmap 上標註 Maxwell 架構將有的主要特色-Unified Virtual Memory 實質上後來也沒有加入第二代 Maxwell 之中,而是要等到 Pascal 才會出現。