











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











Table of Contents
PowerTune 技術改進
在第二代 GCN 架構當中主要的改進並沒有很多,其中之一是在初代 GCN 架構與 Terascale 後期產品當中引入的 PowerTune 動態超頻技術獲得了改進,以往在 Terascale 與 Southern Islands 當中 PowerTune 只有四階動態控制 (低檔、中檔、高檔與超頻),但實務上由於檔位之間的落差很大,因此 GPU 從高檔與中檔之間切換的機會甚少 (通常都在高檔當中的各個次檔位當中移動),在大多數情況下 GPU 並沒有辦法來得及將電壓下調至中檔以達到省電的效果而使得 PowerTune 功能在省電方面效果非常有限。
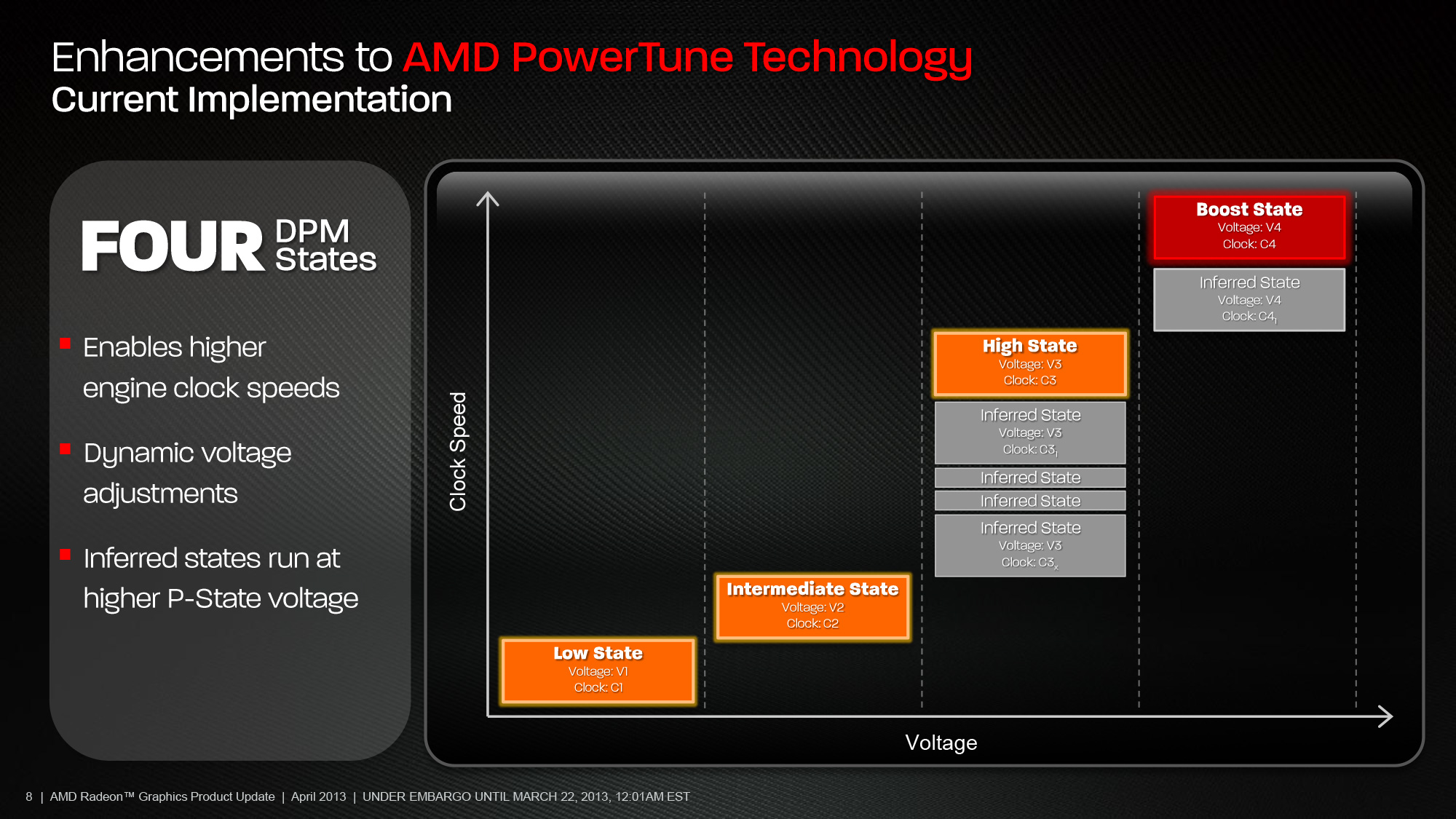
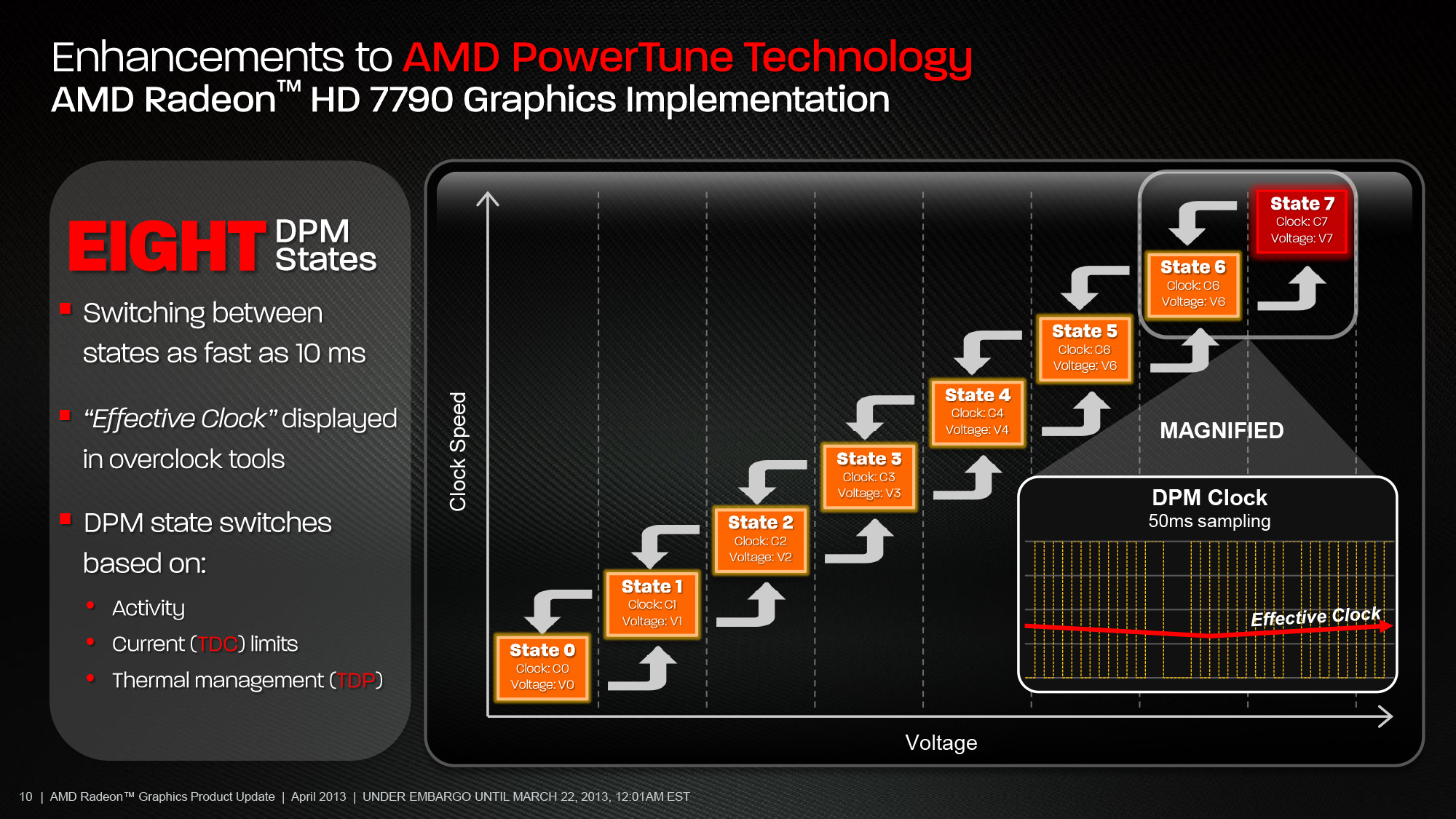
在 Sea Islands 世代 AMD 則將 PowerTune 的切換階數增加到八個檔位,透過細分檔位與加快電源管理單元的處理速度 (高達五倍快) 來讓 PowerTune 功能可以更快速、即時的根據當下的情況動態調整 GPU 的電壓與時脈,使 PowerTune 帶來的省電效果更加明顯。
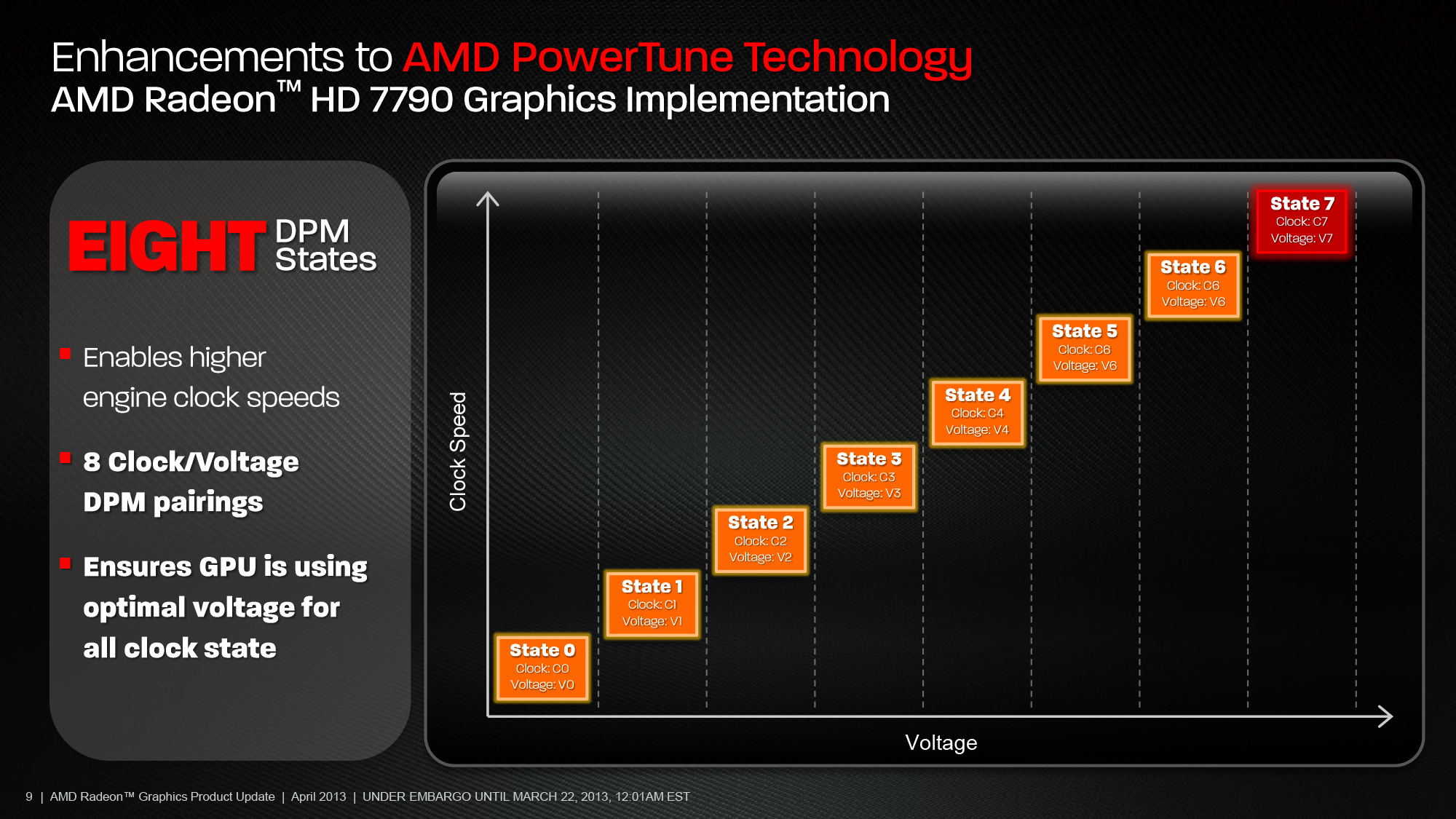
此外,在新版 PowerTune 功能當中動態調整 DPM 檔位的一句除了原先的 GPU 使用率、熱功率 (TDP) 之外,還額外新增了一項稱為熱設計電流上限 (TDC Limits) 的指標 (計算依據為通過 GPU 的電流大小)。
通用運算與前端單元的強化
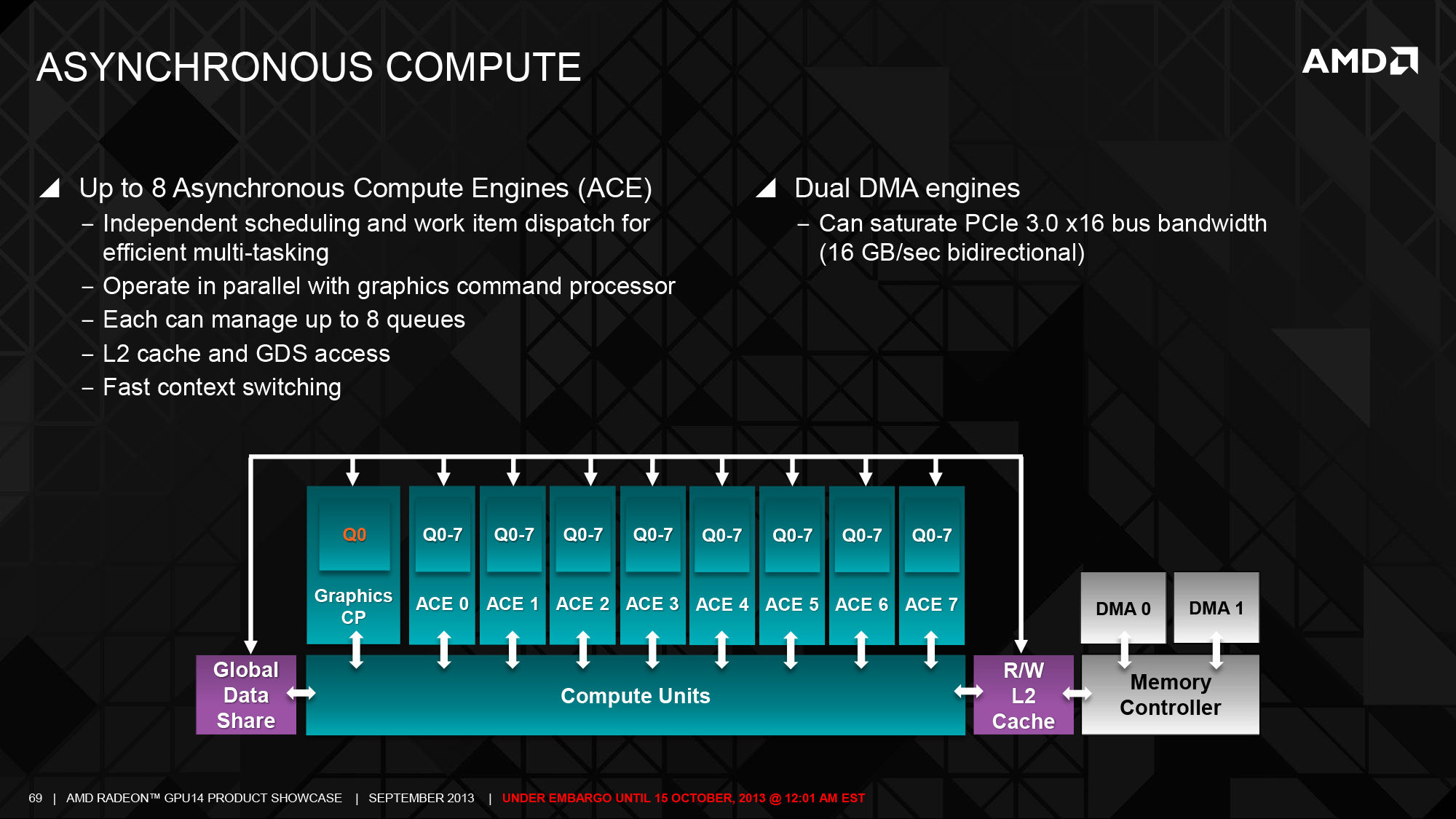
另一項在 Sea Islands 當中引入的主要改進則是在指令集架構 (Instruction Set Architecture, ISA) 中納入了對通用位置定址、MQSAD 指令與一些雙精度向量運算相關的指令的支援與前端運算單元的改進,儘管前者主要是針對程式開發者因此一般用戶比較沒有辦法感受,但這對於 AMD 當時希望發展的異質運算架構 (HSA) 來說可說是至關重要。
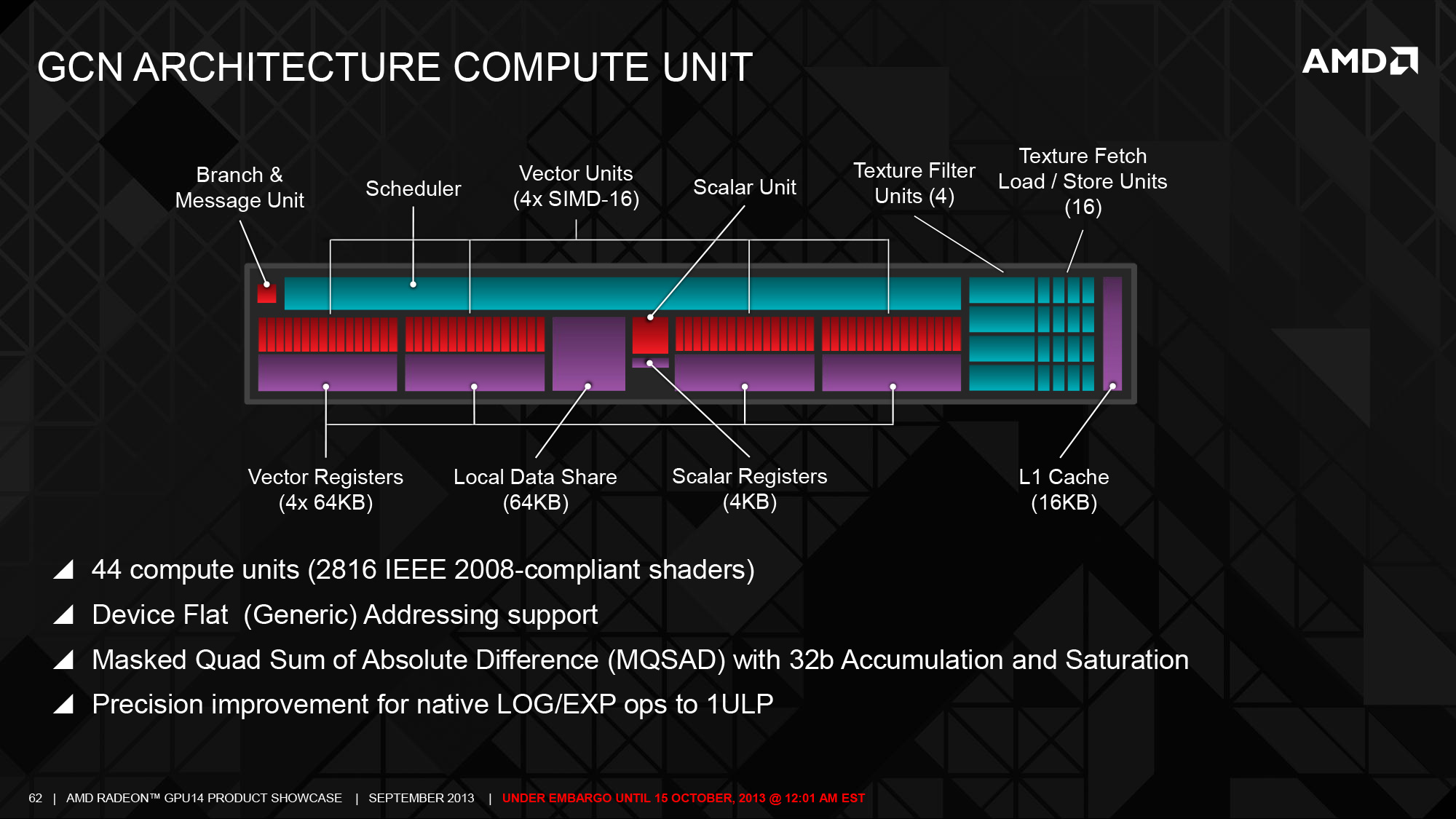
至於在前端單元的改進方面則主要出現在異步運算引擎 (ACE) 上,ACE 是 GCN 架構當中負責執行緒排程與發派工作給 CU 的單位,與 GCN 架構 GPU 的資源調度效率有著至關重要的影響 (實際上後來幾代 GCN 架構當中幾乎都免不了針對 ACE 進行強化或增加數量),在第二代 GCN 架構當中允許 GPU 可以包含更多組的 ACE,每組 ACE 也都能支援更長的任務佇列,這是第二代 GCN 架構產品當中除了 CU 數量之外性能提升的主要來源。
CrossFire 改進,捨棄 CF 連接器
在第二代 GCN 架構當中 CrossFire 也獲得了一些改進,透過改進 GPU 上的硬體 DMA 引擎 (設計改進並由一組改為兩組) 使多顯示卡偕同運作不再像過去一般需要依賴 CrossFire 連接器的協助,而是可以透過系統本有的 PCI Express 匯流排直接達成類似的目的,由於 PCI Express 通道的頻寬遠比以往的 CrossFire 連接器要來得大,因此可以避免 HD 7990 時代因 CrossFire 連接器頻寬不足而導致的跳格、掉圖問題,並且比起以往而言多卡 CrossFire 的性能衰退其實是大幅減少的。

但這樣的做法實際上也造成了新的問題,因 PCI Express 通道為與其他 GPU 資料共用的通道,與過去 CrossFire 連接器使用專屬的點對點通道不同,因此傳輸延遲較先前的設計略有增加,且在通道發生阻塞的時候可能會影響 CrossFire 的性能與穩定性。
Bonaire 核心
基於第二代 GCN 架構的桌上型 GPU 核心實際上只有兩款,其中第一款採用第二代 GCN 架構的 GPU 是定位於主流市場的 Bonaire 核心。

精確來說的話 Bonaire 實際上是定位在 Pitcairn 與 Cape Verde 之間的產品,主要是為了解決 Cape Verde 與 Tahiti、Pitcairn 之間性能落差過大造成中間出現空缺的問題而生。
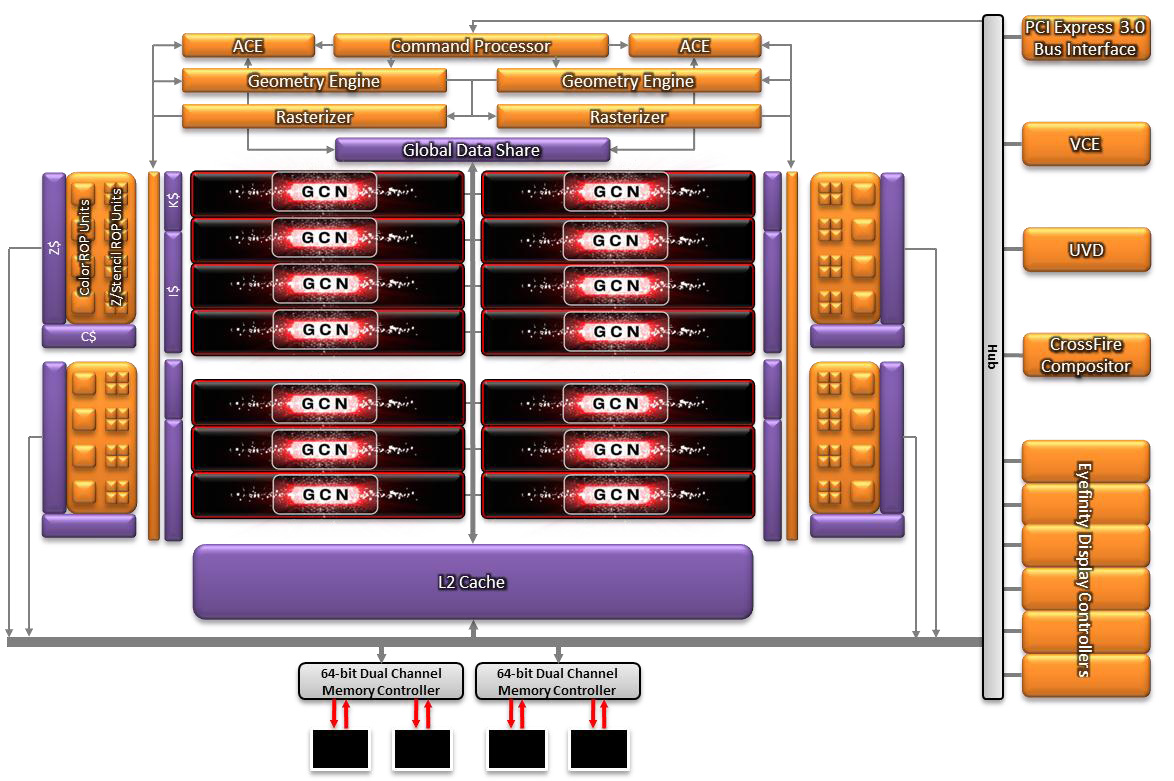
Bonaire 的配置大致上與 Cape Verde 非常相似,同樣採用由四組記憶體控制器組成 128 位元的記憶體頻寬與具備 16 組渲染輸出單元,至於 CU 的數量則略為增加了四組 (亦即多了 256 個 SP),最大的差異則是出現在前端處理單元的部分。
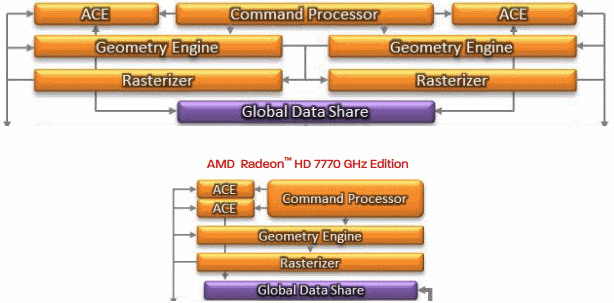
上圖當中出現的是 Bonaire (上方) 與 Cape Verde (下方) 的前端運算單元之比較,可以發現 AMD 當初在設計 Cape Verde 的時候刪除了一半的 Geometry Engine 與 Rasterizer,然而這正是 Cape Verde 與 Pitcairn 之間性能落差過大的主要原因,在 Bonaire 當中 AMD 就採用了與 Tahiti 與 Pitcairn 相同的前端設計了,得益於加倍的前端元件性能與 40% 的運算單元數量增長,因此 Bonaire 的性能比 Cape Verde 要好上不少,特別是在處理曲面細分的時候。





