











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











相信你也注意到 R520 在架構設計上只有 16 條組成 4×4 結構的像素渲染器了吧?相較於 G70 來說可以說是落後甚多,單看架構圖的話十之八九大概會猜測 R520 的性能遠遠不及 G70,但實際情況卻不是如此,G70 與 R520 在絕大多數的測試情況下都是互有勝負的,ATI 是怎麼做到這點的呢?實際上靠的就是圖上很顯眼的 Ultra-Threading Dispatch Processor。

這種設計基本上就是透過將組成原有的繪圖管線拆成各自獨立的部分來使得利用效率可以獲得明顯的成長 (避免產生互等的情況),如同過去我們所知道的,3D 圖形運算實際上是高度可平行化的運算,因此一旦平行性得以提高,對性能來說造成的成長幾乎跟管線數量增加是一樣的。以處理執行分支的過程為例:
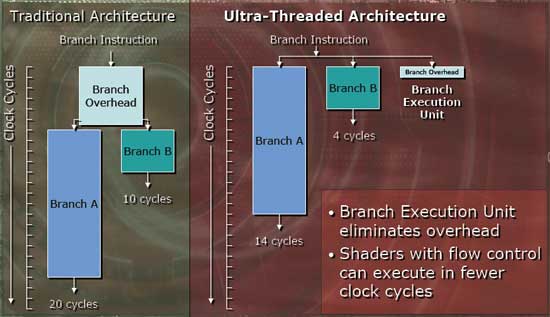
在調整為新的獨立設計之後,原本需要等待 14 + 6 個週期才能執行完的分支 A、B 在全面平行化之後最短可以壓縮到只需要 14 個時脈週期就能完成,不過在這邊要特別提到的一點是,ATI 在設計 Radeon R500 時並沒有支援 Shader Model 3.0 當中的 Vertex Texture Fetch (頂點紋理擷取),依照 ATI 的說法,微軟在規範 DirectX 9.0c 的時候是將 VTF 設為選用特性,因此 ATI 使用了另一種稱為 R2VB (Rendering to Vertex Buffer) 的方式來提供類似的功能,原理上是運用 Radeon R500 超寬的 128-bit Vertex ALU 來達到類似的功能,不過實務上 R2VB 需要軟體的支援,但 ATI 在 DirectX 9.0c 這世代本身已經是遲到許久了,因此 Radeon R500 無法支援 VTF 在上市之初曾經引發過一陣爭論。
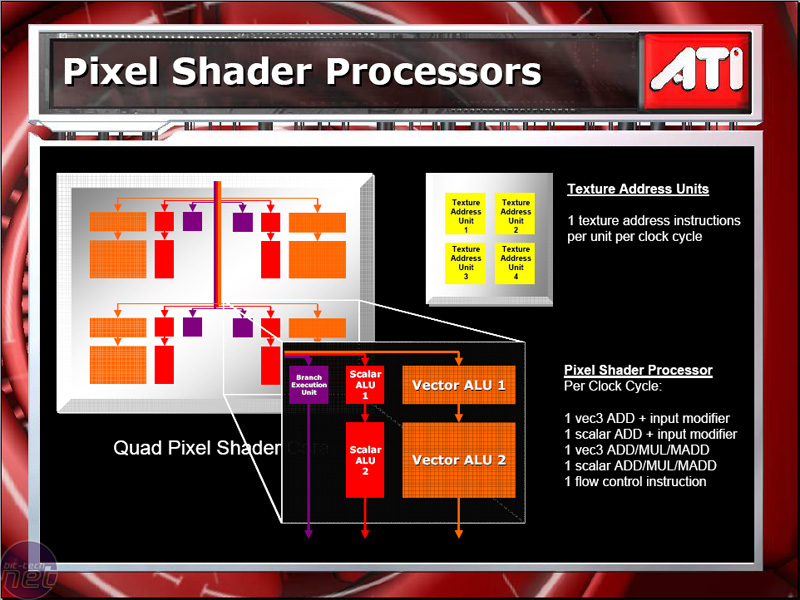
除了降低分支操作造成的延遲之外,透過 Ultra-Threading Dispatch Processor 進行調控與工作分配可以使像素渲染器本身的利用率得以提高許多,更進一步的帶來性能提升,於是最後造就了 R520 只需要 16 條管線就可以與具備多達 24 條管線的 7800 GT 相競爭,而除了繪圖管線的改進之外,R520 的另一項重大變革則是出現在記憶體控制器上。

是的,你沒有看錯,就是環狀記憶體鏈路技術,如果你還有印象的話可能會聯想到 Intel Sandy Bridge 處理器首次採用環狀內部連線吧?透過內建兩條環狀記憶體匯流排 (雙向各一條,連接了四個端點,每個端點負責兩個記憶體顆粒晶片),並由中央的 Write Crossbar Switch 調控最快路徑,使得 Radeon R500 內部的記憶體資料傳輸通道寬度可以高達 512-bit 之寬!乾淨的佈線也讓時脈提升變得相對容易一些,除此之外內部的快取記憶體也升級為全關聯式,因此在處理記憶體映射的延遲也降低了。

除此之外 ATI 還針對 DirectX 9.0c 的一些弱點進行了改善,像是啟用了 HDR 就無法使用反鋸齒效果 (因為占用了相同的緩衝區的緣故) 之類的問題,在 Radeon R500 上是不會發生的,不過由於這部分不屬於 DirectX 官方規範,又加上佔有另一半市佔率的 NVIDIA 產品並不支援,因此實際上使用的軟體或遊戲屈指可數 (就跟 3Dc 材質壓縮技術一樣,說起來 R500 也內建了升級版的 3Dc+,不過依然乏人問津)。

說了這麼多,讓我們回到產品本身吧。R500 系列第一款上市的產品是面向中高階市場的 R520,在 2005 年 10 月 05 日被命名為 Radeon X1800 系列進入市場,初期有 XT (625/750 MHz) 與 XL (500/500 MHz) 兩個型號,全都具備完整的 16 組像素渲染器與 8 組頂點渲染器,年底追加的 CrossFire 特別版則是運作於 600/700 MHz,後來 ATI 在隔年三月還推出了閹割掉 4 組像素管線的 X1800 GTO (500/495 MHz)。






