











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











至於為什麼要這麼做呢?其實有很多理由,首先在以往的架構當中,由於繪圖管線本身是一個具有 4 個維度的運算單元,在單一周期內雖然可以同時處理一個三維度的向量與一個純量,但在實務上卻不是隨時都有這些資料能夠充分「餵飽」這些運算單元,在這種情況下就類似以往的非統一渲染器架構,會發生有些部分在納涼的資源閒置浪費情形。

而在新的架構當中,雖然每次都只能處理一個維度,在遇到向量指令的時候得「分次處理」,但由於 G80 架構當中本身有一堆 SP 可以做事,因此在效率上造成了不減反增的效果,而且還能解決過去在處理純量或低維度指令時的閒置問題,每分每秒都能完整利用所有的 SP,壓榨出 GPU 的性能極限。
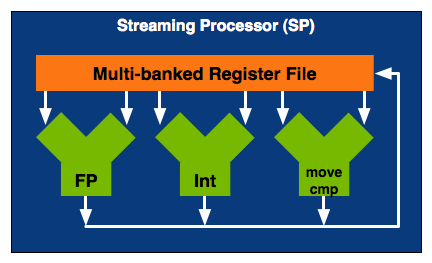
而另一個重要的理由則是大幅簡化「單一 SP」的電路複雜度,這讓 NVIDIA 得以在 G80 架構當中運用分頻技術來讓 SP 運作於比 GPU 本身還要高上許多的時脈設定 (這點有點像 Pentium 4 的快速執行引擎,後面介紹 Tesla 架構產品的時候時脈數字有三個,第二個就是 SP 的時脈),更降低了 NVIDIA 在 GPU 當中塞入更多 SP 的困難度 (相較於以往增加 VS、PS 的難度而言)。
Table of Contents
Lumenex Engine,TMU 一分為二並採不對稱設計
除了在運算單元的部分有著大幅度的調整之外,在 G80 架構當中 NVIDIA 還將原本的 TMU (Texture Mapping Unit,材質對應單元) 一分為二,分為 Texture Addressing Unit (TAU,材質尋址單元) 與 Texture Filtering Unit (TFU,雙線性材質過濾單元) 兩個部分。

而最特別的地方則是 TAU 與 TFU 的數量並不相等,G80 當中的 TFU 數量是 TAU 的兩倍,主要是基於當時預期 GPU 對記憶體索取紋理的機會變少,而處理 HDR 等操作時所需要的雙線性過濾操作頻率增加的考量。

至於要說到 Lumenex Engine 與前作在處理材質貼圖上的差異,其實主要只是體現 DirectX 10.0 當中關於 HDR 與反鋸齒的變更與新要求而已,從 Tesla 架構開始 NVIDIA 的 GPU 就不再有以往受制於 HDR 會占用 MSAA/FSAA 所需要的緩衝記憶體位置而無法同時處理 OpenEXR HDR 與多重採樣反鋸齒 (MSAA/FSAA) 的情況了。
Tesla 架構對平行化的要求與敏感度大增
看了前面的架構設計你應該可以很清楚的感受到 NVIDIA 在設計 Tesla 架構的時候完全是朝著為高度平行運算最佳化的方向進行的,花費了非常多的努力在降低可能導致 GPU 部分運算單元閒置情形的發生機率,這意味著對新的 Tesla 架構來說指令與運算操作的平行度與相依性就是影響性能的最大關鍵因素,因此在 Tesla 架構當中,下圖當中橘色的 Thread Execution Manager (後來被改稱為 GigaThread Technology) 扮演了非常重要的角色。

在 Tesla 架構當中的很多地方都體現了充分運用多執行緒的特性,舉例來說我們剛剛提過的 SM 就是這樣的狀況,在 Multithreading 運作成功且高效的狀況下,可以弭平將運算單元全部拆分為純量單元所造成的額外延遲,但相對來說也讓 Tesla 架構對所執行的程式之平行化程度更加敏感。
所以在設計上 NVIDIA 是朝單一指令多執行緒 (SIMT) 的方向思考,透過讓每個 SM 都能高效執行大量的執行緒來弭平內部的各種延遲問題,這正是剛剛提到過的 TEM 所負責的重要工作,TEM 會將所有指令與數據拆分為數千個平行執行緒,使 GPU 能在其最適應的狀況下 (也就是高平行度運算) 來高速執行工作。

除此之外 TEM 還會隨時監測是否有閒置的運算單元出現,當發現這種情況時 TEM 就會立刻發出新的指令給閒置的運算單元處理,以求最大程度的降低硬體閒置發生的機率。

除此之外 NVIDIA 還給每個運算單元提供了暫存器,當 TEM 發現有運算單元因為在等待記憶體存取或其他相依指令的時候,會要求運算單元將目前準備執行但卡住的工作存到暫存器中,並直接指派新的工作給運算單元處理,直到剛剛卡住的指令所需要的資料或條件齊全之後,才會繼續把暫存器內保存的工作拿出來繼續完成,這使得 SP 幾乎不需要等待其他指令或是延遲解決,在運作過程當中可以持續以最高效率 (高平行度) 的狀況運轉,改進了過去繪圖管線可能經常會因延遲而整個停頓的狀況。
G80 核心
簡單看過第一代 Tesla 架構之後 (Tesla 的另一個重點-CUDA 通用運算技術在上一篇我們談過很多了所以在此不再贅述),讓我們回到實際的產品上,基於第一代 Tesla 架構的第一款產品是 G80 核心 (也就是剛剛在圖片中出現很多次的樣板,因為 G80 是最完整的第一代 Tesla 架構核心)。

跟上一代 G70 的情況一樣,NVIDIA 記取過去過於積極提升製程結果被良率整到產品出不來的教訓,因此 G80 並沒有急於採用更高階的製程,而是維持與上一代 G71 相同的 90 奈米製造工藝,不過由於全新的架構與大量的 Streaming Processor,G80 的電晶體數量非常驚人,來到了誇張的 6.81 億個,將近是上代產品 G71 2.78 億的 2.5 倍了,因此 G80 一舉突破了歷代 NVIDIA GPU 面積的最高紀錄 (也超越所有當代的頂級 CPU 了,同期的 Core 2 Duo 只有 2.3 億左右個電晶體)。





