![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











本篇由於篇幅過長因此將分上、下二篇,下篇預計明天發佈。
上篇看完 2006 年個人電腦 3D 圖形方面的巨大革新之後,接下來我打算回到產品的部分,不同於過去幾代廠商在命名上沒有太多同代產品改名甚至交錯的情況,從 2006 年開始每代 GPU 架構幾乎都還蠻長壽而且橫跨多個不同系列,所以沒辦法再繼續用系列當成產品之間的分界了,基於這樣的理由,從這篇開始我會改用「GPU 架構為單位」,一次介紹一間廠商的一代架構,並且輪流介紹 NVIDIA 與 AMD 的產品。
Table of Contents
NVIDIA Tesla Microarchitecture
本篇要介紹的是 NVIDIA 的第一款基於統一渲染器架構的 GPU 架構設計,也就是在 2006 年推出的 Tesla 架構,從此代架構之後 NVIDIA 都使用歷代知名科學家的名字來做為架構的研發代號,這同時也是 NVIDIA 史上最為長壽的架構,從 2006 年開始一路到 2011 年都還能見到基於此架構的產品,Tesla 架構同時也是未來十年內 NVIDIA 所有 GPU 架構的基礎原型。
Tesla 架構由於生存年代很長,因此先後更換過許多次製程,也經歷的數次小幅的改版,因此大致上可以分為前期與後期,其中前期的部分由 G8x 與 G9x 兩個核心系列組成,後者則是由 GT200 系列核心所組成,接下來我打算以此為區分,將 Tesla 世代架構分成二代分別介紹。
第 1 代 Tesla 架構:G8x 系列核心
- 推出日期:2006 年 11 月 (G8x)
- 所屬系列編成:GeForce 8 系列
- API 支援:DirectX 10.0、OpenGL 3.3
- Shader Model 支援:SM 4.0

還記得上一篇我們談了 DirectX 10.0 帶來的大量改變,這理所當然的意味著 GPU 廠商得對他們的架構進行一番大改造才能完整支援新一代的 DirectX,對 NVIDIA 來說,他們給出的答案就是 GeForce 8 系列 (2006 年 11 月就端出來了,AMD 陣營則是被上一代的 R500 拖累並且忙於合併事宜因此要等 2007 年才會端出這世代的產品)。
大幅翻新的架構規劃
由於前代產品 G70 已經是好一陣子之前介紹的了,所以在開始深入談這代架構之前,讓我們稍微先複習一下 G70 的架構規劃吧 (上圖),像是多達 8 組頂點渲染器、多達 6 x 4 組像素渲染器與底下的 16 組 ROUs 之類的,是典型的可程式化管線設計。
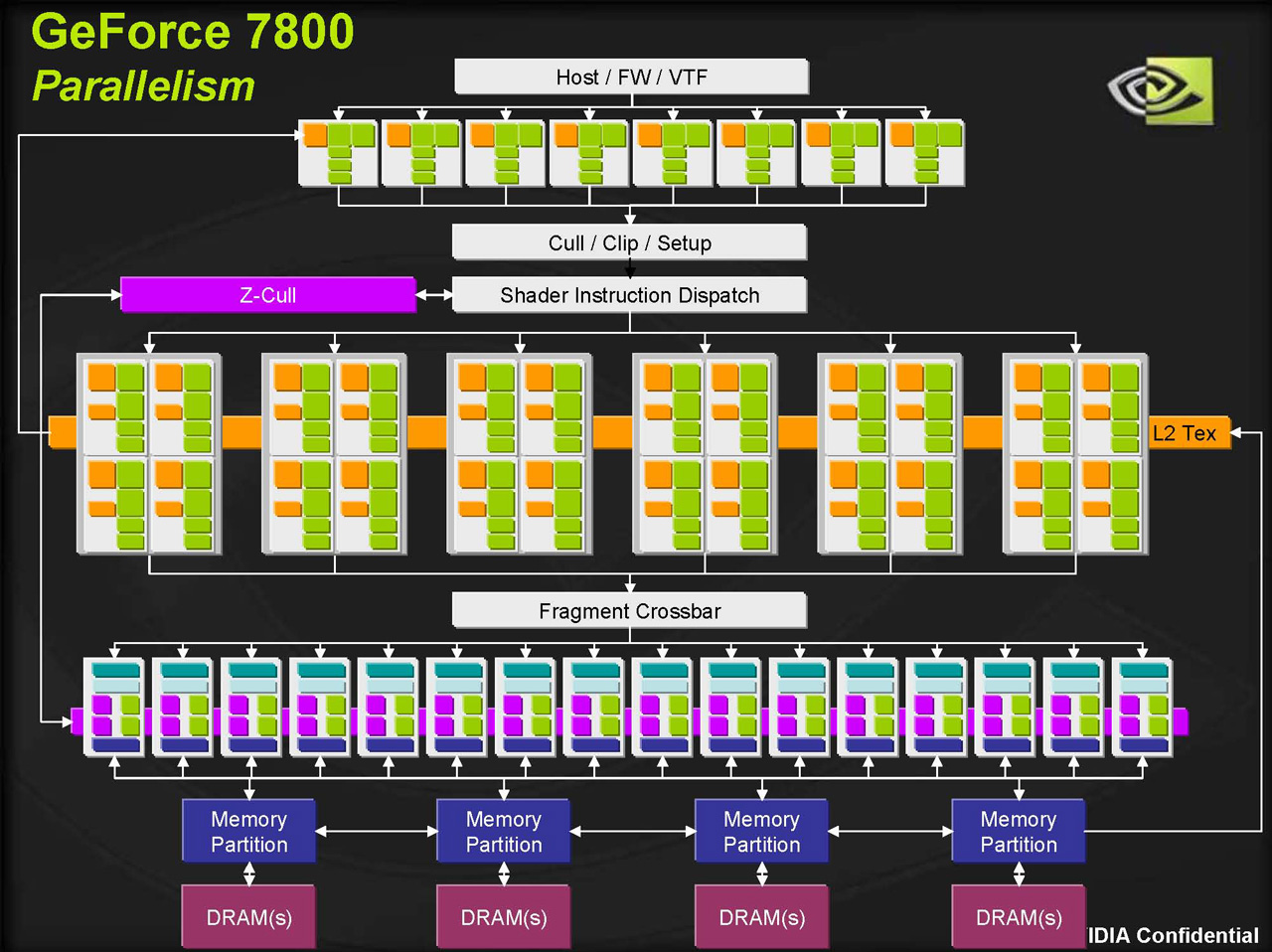
接下來讓我們回頭看看第一世代 Tesla 所帶來的全新架構設計吧,相信明眼人都能看得出來兩者之間差異非常的大,受到統一渲染架構的影響,Tesla 架構跟上一代幾乎沒有太多相似之處,除了中央繪圖管線的架構全部重新洗牌且看不出不同種類 Shader 的分別之外,連同快取記憶體的規劃也產生了巨大的變化,TMU 與 ROP 的部分也和以前大不相同了。
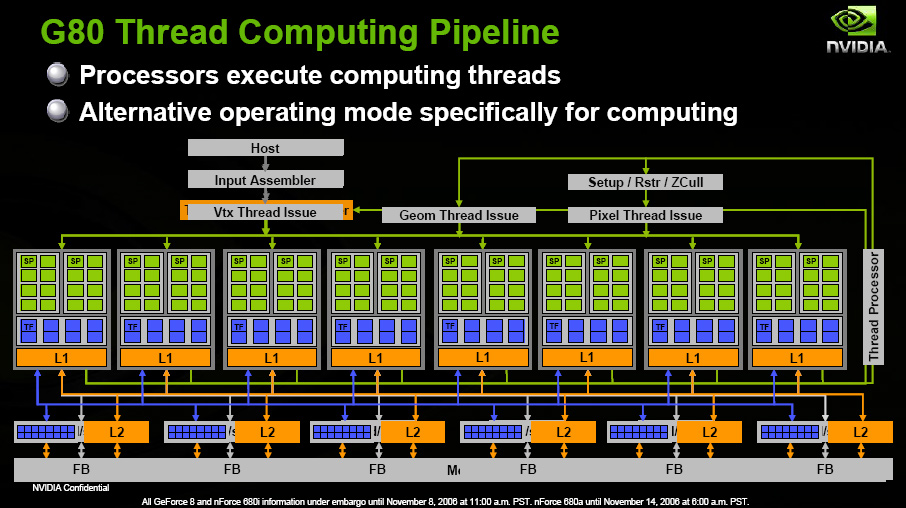
單從上面的架構圖,一般人應該除了發現中間多了一大堆的綠色方塊之外甚麼也看不出來吧?實際上這些五顏六色、各種大小的方塊就是 Tesla 架構最大的變革所在,NVIDIA 稱它們為 Texture Processor Cluster (材質處理單元叢集,TPC),這 8 大組 TPC 在這裡完整取代了以往的繪圖渲染管線成為 NVIDIA GPU 最重要的核心部分 (所以從 G80 開始我們就不討論 NVIDIA GPU 有幾條繪圖管線了),接下來讓我們拉近距離了解一組 TPC 當中到底有著哪些東西。
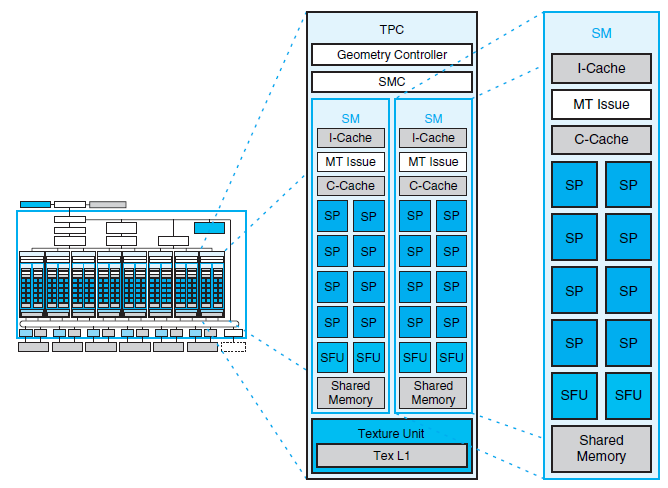
從上圖當中我們可以很明顯地注意到每組 TPC 當中都包含了兩大組稱之為 Streaming Multiprocessor (串流複合處理器,SM) 的運算單元與一大塊用於存放貼圖材質的 L1 快取 (在 Tesla 架構中每個 TPC 之間的 L1 快取是各自獨立的) 與貼圖單元,而每組 SM 單元之中都各自擁有一份 L1 指令快取與 L1 資料快取,在兩種快取之間有負責存取與解碼指令的單元。
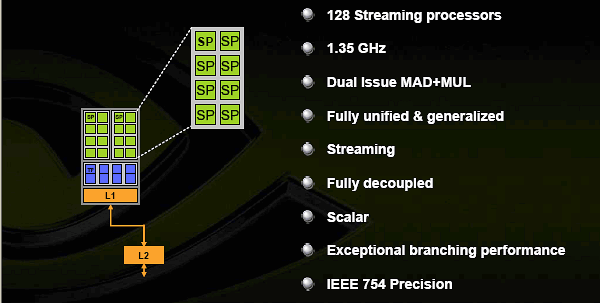
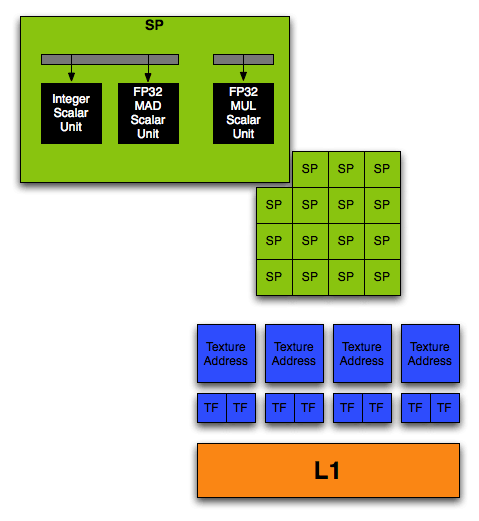
至於實際負責運算工作的則是每組 SM 當中所包含的八個串流處理器 (Streaming Processor,SP,在 G80 當中最多有 128 組之多) 與兩組用於處理複雜數學函數 (例如指對數、三角函數等) 的特殊功能單元 (Special Function Unit,SFU),這十個運算單元彼此之間還設計了一小塊共享記憶體用於讓這些運算單元得以互相溝通、傳遞資料。
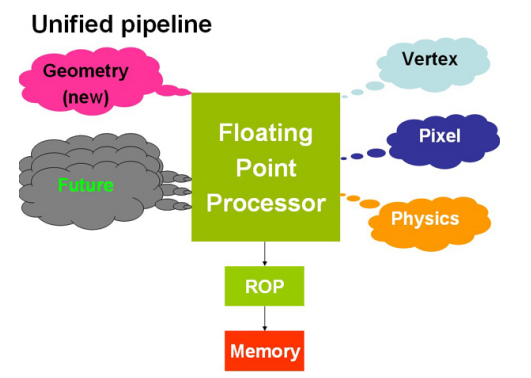
透過大量的通用浮點運算單元來取代以往具專用色彩的 Vertex Shader、Pixel Shader 與 Geometry Shader 實際上就是 NVIDIA 用來實作 Unified Shader Architecture 的基本精神。
SP 數量大增背後的涵義
在了解新的運算單元配置之後,或許你腦中會浮現這個疑問:我們以前說影響 GPU 性能最直接的指標就是繪圖管線 (或是 VS、PS) 的多寡,得益於 3D 圖形運算的高度平行性,我們幾乎可以認為在架構不變的狀況下繪圖管線 (或是 VS、PS) 的數量會與處理器的性能成正比成長,但上一代的 G70 只有 24 條像素管線,G80 的 128 個核心這數字是怎麼來的?難道 G80 一口氣比 G70 快了 5.33 倍嗎?顯然不可能嘛,其實問題的癥結點是在於 VS、PS、SP、繪圖管線這四個名詞所代表的東西,其實根本是完全不同的事情。

但要解答這個疑問之前,我們得先了解在過去幾代 GPU 當中,繪圖管線中的運算單元是怎麼運算傳進來的資訊的。實際上以往我們的 GPU 大致都是設計成能夠同步處理一個三維向量與一個純量,也就是一次最多能處理四個維度的意思,這被我們稱為「一組 ALU」,也就是過去我們所談的 Pixel Shader (PS) (上圖)。
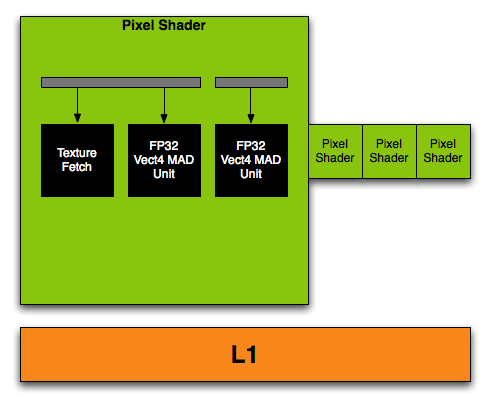
不過在 G80 的架構中 NVIDIA 決定不這麼做,改成全部只使用「純量運算單元」,讓每個 SP 簡化成只由「一組純量乘加運算單元」與「一組純量乘法運算單元」組成,由於每個 SP 只能處理一個維度的資料,在理論值上只有過去的 1/4 (粗略而言你可以想像成 4 組 SP 才相當於一個 PS),因此才會發生 SP 數量突然暴增的情況 (其實 NVIDIA 應該也有意藉此讓用戶產生 G80 比起以往產品性能強大數倍的錯覺吧?)。