











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











介紹完第一代 Tesla 架構 (G9x) 與後續的小幅修改版 (G9x) 之後,接下來我們要看的是第二代的 Tesla 架構 (GT2xx),雖然仍然是以 Tesla 架構為基礎,但實際上在架構安排與系列編成方面都與第一代的 Tesla 有明顯的不同,事實上在 NVIDIA 官方的分類當中是把 G8x 與 G9x 歸類為「第一代統一架構」,至於 GT2xx 則是自成一類稱之為「第二代統一架構」。
Table of Contents
第 2 代 Tesla 架構:GT200 系列核心
- 推出日期:2008 年 06 月
- 所屬系列編成:GeForce 200 系列、GeForce 300 系列、GeForce 400 系列、GeForce 8 系列
- API 支援:DirectX 10.0、OpenGL 3.3
- Shader Model 支援:SM 4.0
好的,在經過讓人眼花撩亂的 G9x 大亂鬥時代之後,我們終於要進入 Tesla 架構最後的主題了-第二代 Tesla 架構,這代架構被改名的次數「比較少」,絕大多數情況以 GeForce 200 系列為主,而 GeForce 300 系列本來就是 200 系列改名給 OEM 廠商的版本因此不算複雜,而後來 GeForce 400 系列的入門卡也有一些繼續使用 Tesla 架購的產品 (這種情況 NVIDIA 接下來幾乎每代都有)。
在第一代 Tesla 架構奠定了未來 NVIDIA GPU 的基礎、第 1.5 代 Tesla 架構讓成本下降使得 NVIDIA 獲利成長之後,第二代的 Tesla 架構其實才是 NVIDIA 真正希望呈現的 Tesla 樣貌。
相同架構之下,塞進更多的運算單元
如果你覺得 G80、G92 已經很巨大的話,GT200 會讓你認為根本是另一個世界的產物。還記得我們剛剛談到 G92 是由 7 億個電晶體所組成嗎?GT200 直接翻了一倍,是的,14 億,若把它跟當時同期的 Intel 雙核心處理器排在一起,將是下圖這般德行。

直接翻倍成長這可不是甚麼小數目,在相同的架構基礎下要搞到電晶體成長一倍,這意味著 NVIDIA 其實一定修改了不少地方,讓我們回到第一代 Tesla 架構來思考,Tesla 架構最關鍵的部分是甚麼?顯然是 TPC 吧。
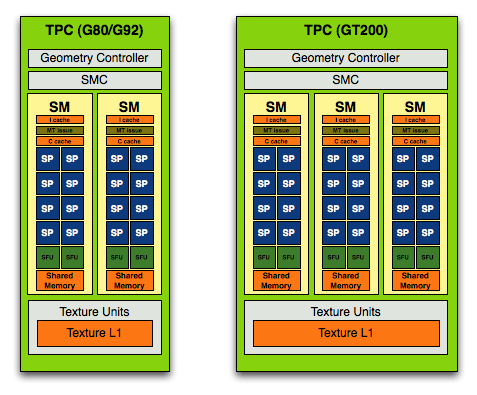
我想用看圖說故事的方式應該就能很容易理解 NVIDIA 在第二代 Tesla 架構當中改了甚麼,本來一組 TPC 當中應該只有 2 組 SM,包含了 16 個 SP 與 4 個 SFU,而在 GT200 當中,基本的架構設計不變,但 NVIDIA 把 SM 的數量從二提高到三,因此每組 TPC 當中現在有 24 個 SP 與 6 個 SFU。
「大、寬、多」是第二代 Tesla 架構的最大特色
不過第二代 Tesla 架構帶來的新特性遠遠不僅只是密度提高的 TPC,基本上與 GeForce 6 系列到 7 系列朝著加寬加廣的方向設計類似,在 GT200 當中你可以發現除了每組 TPC 當中所包含的 SM、SP、SFU 有了大幅度成長之外,甚至連 TPC 本身的數量都從 8 組增加到 10 組了。
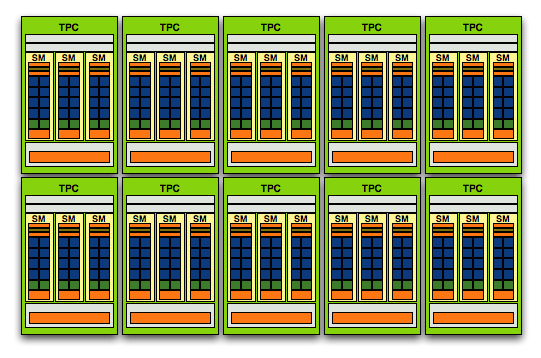
這意味著決定 NVIDIA GPU 性能的最主要因素-SP 的數量將從原先的 128 個一口氣增加到 240 個,幾乎成長了快要一倍,而且除了上面有畫出來的部分之外,實際上在第二代 Tesla 架構當中還首次加入了對雙精度浮點數 (FP64) 的處理能力,每組 SM 都能在每個周期內處理一組雙精度浮點數運算,因此 GT200 每個時脈周期內至多可以處理高達 30 個雙精度浮點數運算。
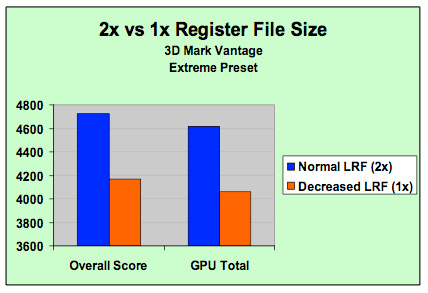
除此之外,儘管我們在 G80 架構當中就知道 Scheduler 在發現 SP 所執行的指令卡住或是陷入等待其他指令的僵局時會要求 SP 將指令丟到暫存器內並執行新的工作,但實務上由於我們使用的 Shader 程式越來越複雜,導致暫存器可能放不下執行中工作的機率提高,導致這項設計所帶來的性能提升無法發揮,因此在 GT200 當中 NVIDIA 將每個 SP 所能使用的暫存器區域大小直接提高了一倍。
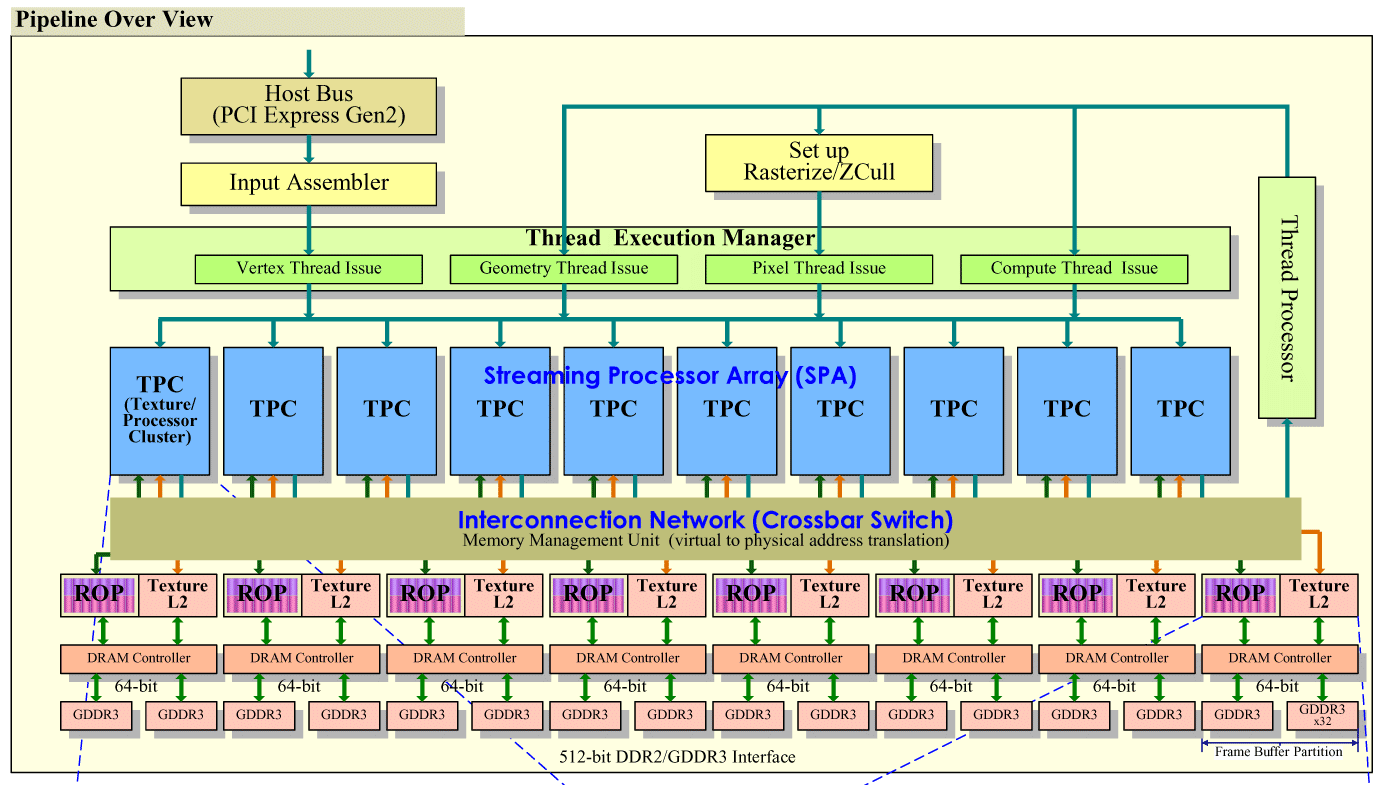
從上面這張較完整的架構圖上可以看到 GT200 的架構體系真的非常寬,特別是在記憶體控制器的部分,以往在 G80 的時候我們覺得 6 組 384-bit 應該就算很多了,但在 GT200 當中,又再次進一步加到八組,可以提供高達 512-bit 的驚人記憶體頻寬。
PhysX 物理運算引擎

除了電路配置上的改變之外第二代 Tesla 架構最主要的新特性應該就是 PhysX 物理運算引擎了,NVIDIA 曾經砸了不少重本來宣傳這項技術,不過這項技術其實本來不是 NVIDIA 的發明,而是來自於一家成立於 2002 年,名為 AGEIA Technologies 的公司,這間公司最主要發展的產品就是被稱為 PhysX 的物理處理器 (PPU,可以製成 PhysX 物理運算卡),顧名思義是專精於物理運算的處理器,如同過去我們所知道的,越「通才」的處理器往往電路複雜,效率提升不易;而「專精」於單一用途的處理器在電路上則會相對比較簡單,處理特定操作的效率也會更強大,在此前物理運算通常是由 CPU 負責的 (在進入統一渲染器架構時代前 GPU 沒有心力也沒有能力處理物理運算)。

AGEIA 這間公司本來生產的物理加速卡雖然在業界上曾經引來很多的注目,但實際上幾乎沒有一般使用者會去額外購買一張只能做物理運算的介面卡來處理遊戲中的物理操作,因此始終在市場上並沒有獲得太大的成功 (如果我手上的資料沒錯的話,似乎只有 ASUS 跟 BFG 有生產過),而在 2008 年 NVIDIA 收購了 AGEIA 之後,PhysX 技術才開始走入一般用戶的世界裡。
 在 NVIDIA 將 AEGIA 收入麾下之後,其實進行了一連串淡化 AEGIA 品牌的各種動作,像是收購完成之後沒多久就把 PhysX 驅動程式當中所有的 AEGIA 字樣以 NVIDIA 取代、實質上完全扼殺 AEGIA 原本發展的 PPU 物理運算卡等,並且非常積極的將 PhysX 技術移植到 CUDA 運算架構上執行,如同大家所知道的,就結果而言這次移植可以說是非常成功,從 G80 以降所有 NVIDIA GPU 都能夠支援 PhysX。
在 NVIDIA 將 AEGIA 收入麾下之後,其實進行了一連串淡化 AEGIA 品牌的各種動作,像是收購完成之後沒多久就把 PhysX 驅動程式當中所有的 AEGIA 字樣以 NVIDIA 取代、實質上完全扼殺 AEGIA 原本發展的 PPU 物理運算卡等,並且非常積極的將 PhysX 技術移植到 CUDA 運算架構上執行,如同大家所知道的,就結果而言這次移植可以說是非常成功,從 G80 以降所有 NVIDIA GPU 都能夠支援 PhysX。
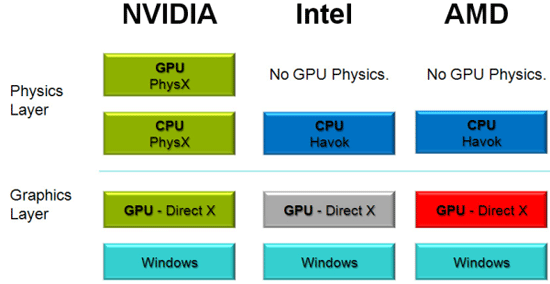
不過 PhysX 技術其實一直以來都存在著很多關於這項技術到底是否真的實用的爭論,特別是在成為 NVIDIA 的獨佔 API 之後只有 NVIDIA 自家的 GPU 能夠支援 (其實 NVIDIA 會去收購 AEGIA 的遠因很可能是 Intel 搶在 2007 年收購了另一家開發物理引擎的廠商 Havok),這意味著在通用度上就有很大的問題,而實際上遊戲也未必真的會去使用 PhysX 的技術規範來設計物理效果,不過 NVIDIA 的強項一直以來都在於吸引大量遊戲廠商提供支援 (對,就是 The way it’s meant to be played 綁標大作戰),又加上 Intel 收購 Havok 之後並沒有重視發展 Havok (畢竟 Intel 的本業是 CPU,太多工作被 GPU 搶去對 Intel 來說是警訊),甚至是陷入停滯,所以最後 PhysX 的採用率其實還是一直都不算低 (精確的說其實是通常都穩坐第一)。
隨著 Havok 在 2015 年又被微軟收購,或許我們很有機會在未來見到 Havok 成為 DirectX 的一部分,作為標準規範的物理引擎提供,若真如此的話 PhysX 的重要性應該會越來越低 (實際上近幾年 NVIDIA 也很少提起 PhysX 了),照常理來看最後應該會由微軟、NVIDIA、AMD、Intel 四方全數應該都能接受的 Havok 拿下最後的勝利 (實際上支援 Havok 的軟體本來就一直都比 PhysX 多,雖然 AMD 在 Havok 被 Intel 吃下來之後跑去擁抱 Bullet API 了),不過目前物理引擎其實討論熱度並不算高,未來會如何發展很難說。





