











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











而負責掌管 SM 模組內部工作分派與排程的 Warp 排程器與指令發送單位 (Dispatch Unit) 也增加為二組,這使得 Fermi 架構的核心可以更加充分且高效率利用 SM 內所包含的大量 CUDA Core 來進行運算,這使得 Fermi 在每個時脈週期中可以派送兩次指令 (最高可以排程達 32 個執行緒)。

還記得我們曾說由高達 14 億個電晶體所組成的 GT200 核心很瘋狂嗎?在 Fermi 這一世代 NVIDIA 再次挑戰了更高的極限,由於加入大量提升雙精度浮點運算性能所需的電路與更多的 CUDA Core 數量,Fermi 架構當中最高階的 GF100 核心所包含的電晶體數量遠比 GT200 要來得多,足足超越了 GT200 的兩倍有餘,來到了高達 30 億個這樣恐怖的規模 (雖然製程從 55 奈米製造工藝升級到了 45 奈米製造工藝,但這還是非常讓人吃驚的提升,不過同時也造成晶片面積在用上新製程的狀況下還是比 GT200 的 55 奈米製程版還要大上不少 (從 470 平方公分增加到 529 平方公分,不過並沒有超越首批採 65 奈米製程的 GT200 的 576 平方公分,上圖左為 65nm 版 GT200,右為 GF100)。
Table of Contents
統一記憶體階層體系
還記得談 CPU 跟記憶體的時候我曾經介紹過電腦的記憶體階層體系嗎?以往在 Tesla 架構當中雖然我們可以見到每組 SM 模組都有共享記憶體、每個 SM 模組中的材質單元也都有自己的材質 L1 快取、ROP 旁邊還設計了材質的 L2 快取,但這樣的設計會給快取記憶體的調度帶來很多限制也造成設置快取帶來的效益並沒有如預期般的明顯、在處理運算方面的時候效果不彰等問題。
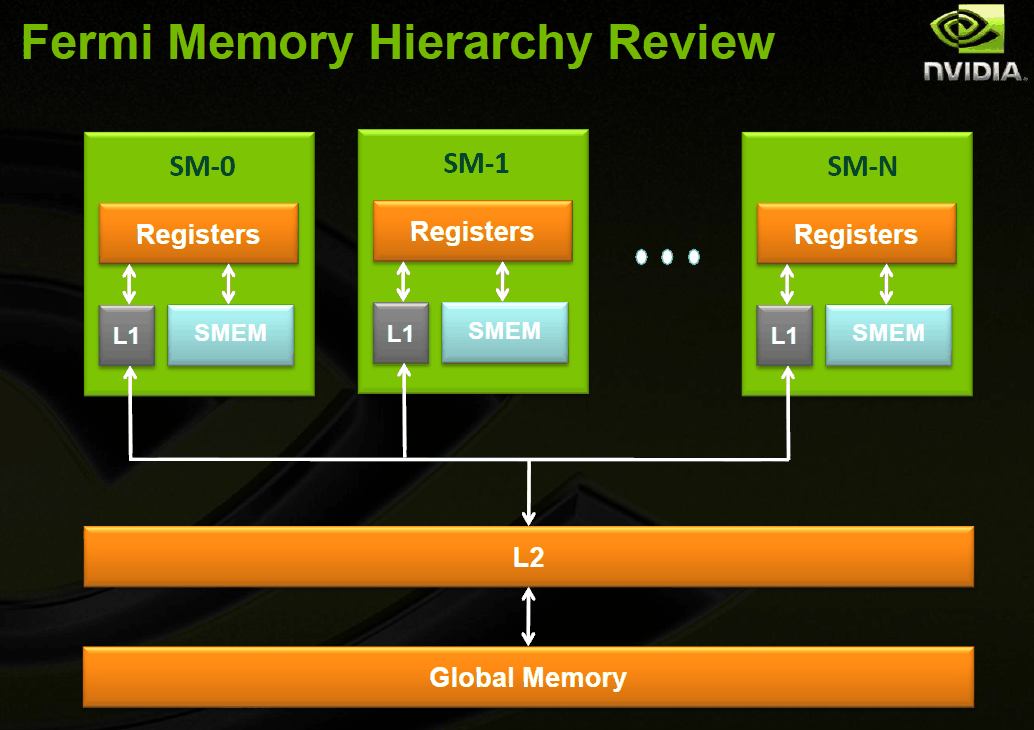
為了解決這些問題,NVIDIA 在 Fermi 架構當中引入了 Parallel DataCache 技術,透過可配置式 L1 快取與統一 L2 快取兩種做法來重新確立 Fermi 架構中的記憶體階層體系,在 Fermi 當中每組 SM 模組都具備了 64 KB 的片上記憶體,而根據當下的需要 GPU 可以被配置為 16 KB 共享記憶體 + 48 KB L1 快取或是 48 KB 共享記憶體 + 16 KB L1 快取兩種模式,這使得在處理特定不需要經常存取顯示記憶體的運算操作可以跑得更快,而再經常需要存取記憶體的應用中也可以帶來更高的快取命中率。
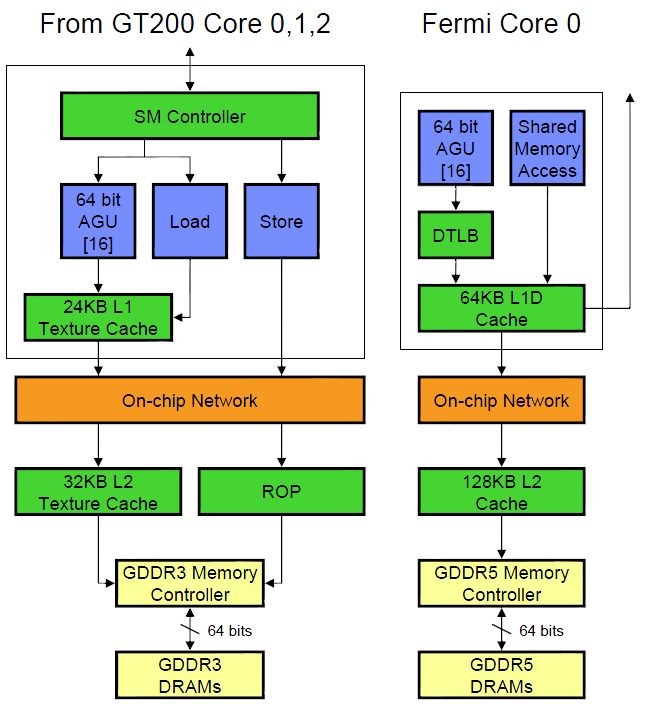
除此之外還新增了在 GPC 之間可以扮演溝通橋梁並允許 GPU 內各個元件之間共享資料的 L2 快取記憶體,這與先前 Tesla 當中僅能處理材質貼圖的專用 L2 材質快取有很大的不同。
進一步朝通用運算發展
除了前面介紹的一些在數量和細部架構上的改進之外,實際上 Fermi 的新特性有很多是體現在功能方面的。從 Tesla 架構開始 NVIDIA 就已經明白揭示未來會逐步將 GPU 從「遊戲用品」逐漸往「超級電腦、高性能運算 (HPC)」領域發展,隨著 GPGPU 技術的發展,GPU 可以處理的內容早已不僅僅是遊戲內的運算,GPU 先天上就具備的強大並行處理能力應該被利用在更廣泛的用途上以創造更大的價值,而在 Fermi 架構這代當中,我們可以見到很多改進其實就是為了這樣的願景而發展的。
首先第一項新功能就是 ECC (Error Correction Code) 錯誤更正技術的支援,這項功能被包含在大多數型號的 Fermi 架構核心當中 (基本上只要有 Tesla 運算卡對應系列型號的核心都有),涵蓋的範圍則遍及暫存器、L1 快取、L2 快取與顯示記憶體。
這主要是為了讓商用市場採用 Tesla 運算卡的意願提高而做的改變,不過對於一般遊戲市場用的高階顯示卡而言,這些多出來的電路其實只有浪費面積跟額外耗電的功能,而且在 GeForce 系列中實際上是不允許開啟 ECC 功能的,從這點可以看出 NVIDIA 的重心逐漸倒向運算領域,而不再以遊戲體驗發展為第一優先 (某種程度上也跟 GF100 當時的良率實在太低,成本實在太高,拿來當消費性顯示卡賣根本賺不了錢有關)。
不過在 Fermi 上 ECC 的實作與一般電腦記憶體系統不太一樣,並沒有獨立出額外的記憶體晶片用以儲存 ECC 資訊,而是在 ECC 啟用時直接吃掉 1/8 的記憶體空間與頻寬用來處理 ECC 資訊,因此性能與記憶體空間利用率是比不上一般的 ECC 實作方式的。
另一項功能則是記憶體定址能力的拓展,與 CPU 的發展相似,NVIDIA 在 Fermi 架構之前的所有 GPU 都只能支援 32 位元寬度的記憶體定址,因此最高能支援的顯示記憶體容量大約落在 4 GB 附近,而 Fermi 架構則開始使用類似 AMD64 / EM64T 的設計來支援 64 位元記憶體定址 (但實際上只啟用其中的前 40 位元部分),因此理論上最多可以定址高達 1 TB 的顯示記憶體。
| 核心名稱 | G80 | GT200 | GF100 |
| 架構分代 | Tesla Gen 1 | Tesla Gen 2 | Fermi |
| CUDA 核心數 | 128 | 240 | 512 |
| 雙精度浮點運算能力 (每時脈週期) | 不支援 | 30 個融合乘加運算 | 256 個融合乘加運算 |
| 單精度浮點運算能力 (每時脈週期) | 128 個乘加運算 | 240 個乘加運算 | 512 個融合乘加運算 |
| Warp 排程器 | 1 | 1 | 2 |
| 特殊功能單元 (SFU per SM) | 2 | 2 | 4 |
| 共享記憶體 (per SM) | 16 KB | 16 KB | 48 KB + 16 KB 可互換配置 |
| L1 快取 (per SM) | 無 | 無 | |
| L2 快取 | 無 | 無 | 768 KB |
| ECC 記憶體支援 | 不支援 | 不支援 | 支援 |
第三項特性則是 Fermi 架構的雙精度浮點運算能力有了非常明顯的成長,透過新的配置與調度方式使得 Fermi 在處理雙精度浮點樹運算的時候性能可以非常接近理論值 (也就是單精度浮點運算的一半性能),在過去 Tesla 時代基本上雙精度浮點運算的運算能力大約都只有單精度浮點運算的八分之一左右 (不過消費性 GeForce 系列 NVIDIA 有運用市場區隔手段限制雙精度浮點運算性能為單精度浮點運算的八分之一)。
GF100 核心-又吵又熱,性能提升卻不多
在稍微介紹過 Fermi 架構帶來的新特性之後,接下來照慣例我會逐個介紹這個世代的各款 GPU 核心,首先登場的是系列當中最為完整的大核心-GF100。

GF100 核心最早在 2010 年 03 月 26 日上市,被分為 GTX 480、GTX 470 與後來追加的 GTX 465 三個版本,在介紹這三款產品之前要特別提到的是其實 NVIDIA 直到 Fermi 最後要上市前都沒能徹底解決 Fermi 如此巨大 (高達三十億個電晶體) 晶片的良率與成本問題,即便 NVIDIA 已經跟隨 AMD 用上了新一代的 40 奈米製造工藝 (NVIDIA 在前幾代都沒有追製程,但 Fermi 的規模實在是太大了導致 NVIDIA 基本上不得不採用新的 40 奈米製程,若不是新製程的提升,GF110 很有可能再次突破 GT200 的紀錄成為 NVIDIA 有史以來面積最大的晶片) 仍然沒有辦法將真正的「完整版」GF100 核心發佈到市面上,因此即便是系列編成當中最高級的 GTX 480 (700/1401/3696 MHz + GDDR5) 也得屏蔽掉其中一組 SM 才行,這就是 GTX 480 的 CUDA Core 數量是 480 這樣奇怪數字的由來,同時材質單元也就跟著被下修為 60 組、渲染輸出單元亦只剩下 48 組了。

而 GF100 核心的耗電量與溫度依舊高低不下,其實在當時讓不少人想起當年曾經讓 NVIDIA 面臨創辦以來最大挫敗的 GeForce FX 系列產品,甚至有不少 YouTuber 還拍攝了使用 GTX 480 煎蛋或煮食的影片藉以嘲諷 GTX 480 的高耗電與高溫問題,然而更要命的是 Fermi 架構的提升過於聚焦於 GPGPU 通用運算,因此在遊戲用途上其實並沒有辦法佔到甚麼便宜,即便 NVIDIA 耗費了非常多心力在優化 DirectX 11 新功能上,使得 GF100 核心在吃重 DirectX 11 的測試項目中可以輕鬆輾過 AMD 的競爭產品,但實際上新版 DirectX 的採用率通常不會太快提升,導致在大多數人實際的遊戲體驗過程中並沒有辦法感受到 GTX 480 有比 AMD 的產品快上多少 (甚至在許多項目中其實還反而比 AMD 的 HD 5870 慢了不少),這使得 GF100 在市場上的反應其實並不成功。





