











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











看完 AMD 陣營的 Terascale 架構之後,接下來我們是時候回到 NVIDIA 這邊了,如同在前兩篇談過的理由,之所以先介紹 Terascale 系列架構的原因其實是因為 NVIDIA 在 DirectX 11.0 世代慢了好幾個月的關係。
Table of Contents
NVIDIA Fermi Microarchitecture
- 推出日期:2010 年 03 月 (GF100)
- 所屬系列編成:GeForce 400 系列、GeForce 500 系列、GeForce 600 系列、GeForce 700 系列
- API 支援:DirectX 11.0、OpenGL 4.5、OpenCL 1.1
- Shader Model 支援:SM 5.0
本篇要介紹的是 NVIDIA 第一款支援 DirectX 11 API 的 GPU 架構-Fermi,與上一代的 Tesla 相同是以歷史上的知名科學家命名的產品,是以 Tesla 架構為基礎改進而來的新架構。
Fermi 架構最早發佈於 2010 年,與 Tesla 架構一樣是一款相當長壽的架構,一路到五年後的 2014 年都還有基於 Fermi 架構的產品推出,但長達五年的生命週期當中並沒有推出世代中期改版與製程升級 (所有基於 Fermi 架構的桌上型電腦用 GPU 都是基於 40 奈米製程,只有筆記型電腦用的 Fermi 核心有推出 28 奈米製程版本)。
實際上雖然 Fermi 的生存年代很長,但作為當家旗艦的時間其實很短 (因為作為接任者的 Kepler 架構在 Fermi 架構上市兩年後的 2012 年就推出了),後面幾年基本上只出現於低階入門產品中。
遲來的 DirectX 11 產品
在 DirectX 11 這一世代,NVIDIA 的動作可以說是比競爭對手還要慢了很多,要一直等到 2010 年 03 月,也就是 AMD 推出首款相容 DirectX 11 的架構-Terascale 2 後又過了半年之後。
之所以會拖這麼久其實最主要的原因有二,首先 AMD 方面由於過去在發展路線上壓對寶,加上 AMD 很早就開始研究曲面細分 (Tessellation) 而這又正好是 DirectX 11 當中最鮮明的特色之一,以及後期與微軟的交好使其得以在小幅修改 Terascale 架構的狀況下迅速推出支援 DirectX 11 的新款產品,但 NVIDIA 方面卻不是如此,為了能夠充分體現 DirectX 11 的新功能,當初發展方向選擇不同的 NVIDIA 勢必得對 Tesla 架構進行一定程度的修改才行 (但這有利有弊,最後 NVIDIA 反而有更多時間對 DirectX 11 的新功能與新特性進行優化與除錯)。
而另一個原因 (實際上主要的原因是這個,因為 Fermi 的整體規劃甚至設計圖紙其實在 2009 年 09 月 Terascale 2 上市的時候就差不多已經完成了,甚至也對外放出許多消息了) 則是由於在 Fermi 這個世代 NVIDIA 正受到 AMD 奇襲戰術的困擾,而 NVIDIA 所選擇的應對方式也很直白,就是「造一個比 GT200 更大的核心」 (就是 AMD 希望的那樣),因此 NVIDIA 終於開始遭遇 (或者應該說終於肯面對並公開承認) 發展大核心時所會遇到的各種問題與困難了。
在處理 Fermi 旗艦版 GF100 核心的時候 NVIDIA 其實遇到了很多良率與功耗方面的問題,這也花了 NVIDIA 不少時間,甚至讓時任 NVIDIA 產品行銷副總裁的 Ujesh Desai 爆粗口說出「because designing GPUs this big is “fucking hard”」作為對 Fermi 延期理由的解釋。
更大、更多、更複雜的 Tesla
總體來說 NVIDIA 從 Tesla 架構以降的歷代 GPU 架構設計基本上都是從 Tesla 架構下去衍生、修改而來的,不論是 Fermi、Maxwell 甚至是目前最新的 Pascal 大抵上都是如此作法下的產物,因此在開始探究 Fermi 架構的規劃之前,讓我們稍微來複習一下 Tesla 的架構規劃吧。
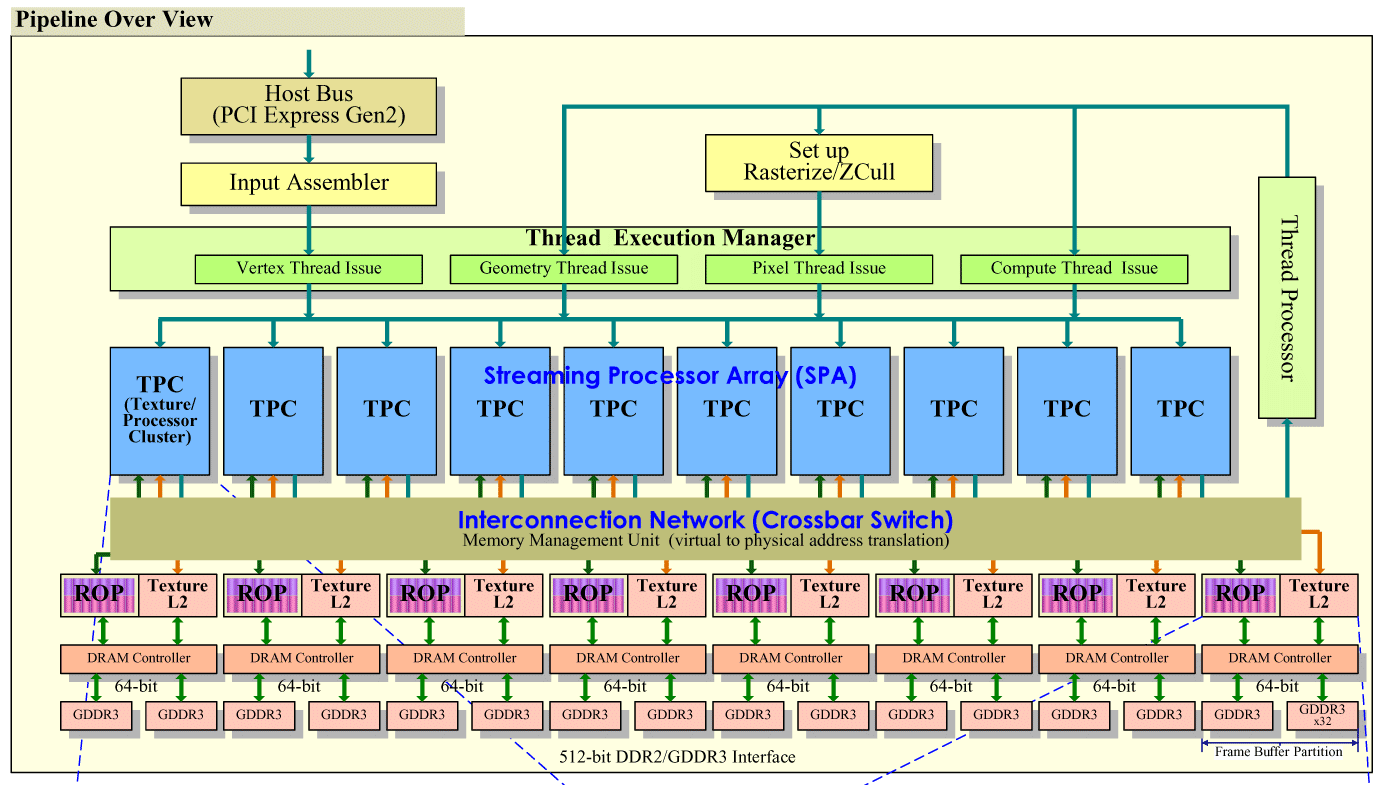
上面這張圖就是 Tesla 架構最完整、規模最大的旗艦核心-GT200 的架構簡圖,當中最為顯眼的就是大量的記憶體控制器 (Memory Controller) 與中間藍色區塊的那一大排 TPC (Texture Processor Cluster),同時這兩大塊也是 Tesla 架構當中決定性能與位階的主要影響因素,而其中又以 TPC 的規劃最為重要。
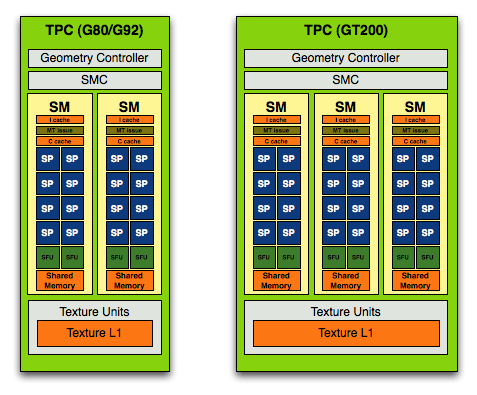
Tesla 時代的 TPC 內部構造如上圖所示,由兩組 (第一代 Tesla 核心) 或三組 (第二代 Tesla 核心) 串流多重處理器 (Streaming Multiprocessor, SM) 群組與控制單元、材質單元與材質快取這幾大部分所組成,當時一組 SM 當中還包含了 8 個串流處理器 (SP),也就是後來我們熟知的 CUDA Core (實際上就是 ALU),回顧完 Tesla 架構之後,讓我們回來看 Fermi 架構到底是怎麼回事吧,下面這張龐然大物就是 Fermi 的架構圖了 (以 GF100 大核心為例)。
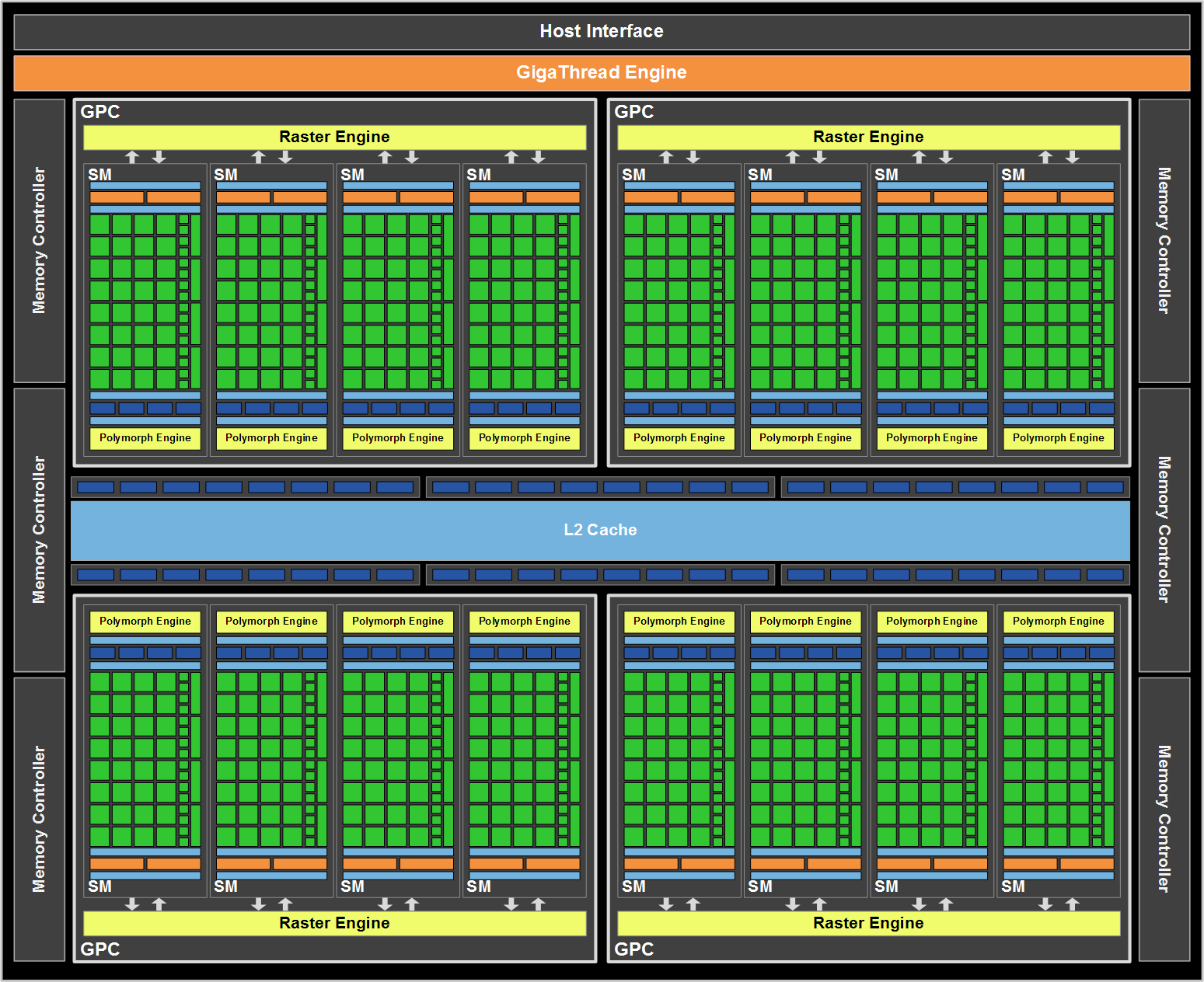
乍看之下好像跟 Tesla 架構不太一樣?但仔細看你就會發現其實 NVIDIA 只是把架構圖用另一種方式呈現而已 (剛好把他拼成一個大長方形,大多數的組成跟名詞其實都是同一套東西下去改進的結果),GF100 本身包含了四組 GPC (Graphics Processor Cluster, 圖形處理器叢集,其實就是從 Tesla 裡面的 TPC 演化來的,只是 GPC 更接近一個完整的 GPU,基本上只差 PCI Express 匯流排跟記憶體控制器了),而每組 GPC 當中包含的 SM 模組數量則從三組再次增加為四組之多。
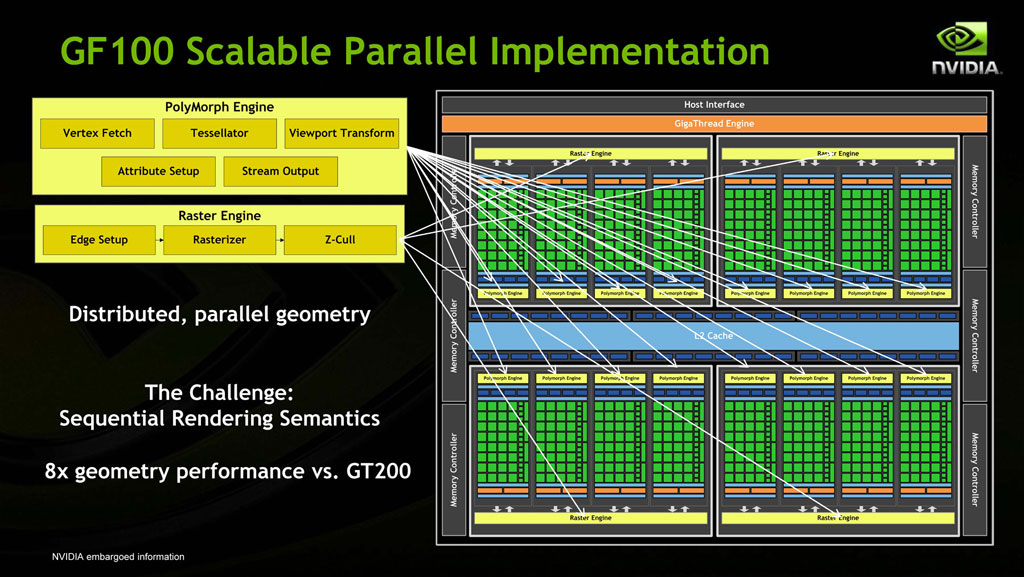
至於圖中的 Polymorph Engine 與 Raster Engine 則分別是由 Tesla 架構中配置於 TPC 內的串流處理器控制器 (SMC) 與光柵輸出單元 (ROP) 發展而來 (主要是多了 DirectX 11.0 需要的曲面細分硬體電路等設計),每個 GPC 都有自己獨立的一組 Raster Engine,每個 SM 也都有各自獨立的一組 PolyMorph Engine。這同時也是 Fermi 當中重點強化性能的部分,據 NVIDIA 官方說法,GF100 的幾何運算性能 (例如曲面細分) 是 GT200 的八倍之多。
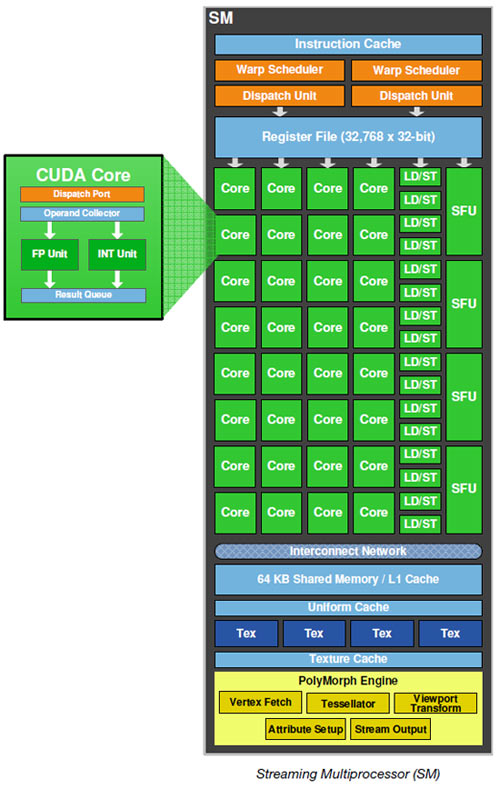
而 Fermi 架構實際上除了增加了 SM 模組的數量之外,同時也提升了每組 SM 模組當中所包含的 CUDA Core (ALU) 數量,從原來的 8 組一口氣增加到 32 組 (因此 GF100 可以有多達 512 個 CUDA Core,在數量上遠遠超越上一代產品 GT200 的 240 個),特殊功能單元 (SFU) 的數量也一併加倍為四組,並且首次引入了獨立的 Load/Store 單元設計 (因此 Fermi 核心每個時脈週期內可以計算 16 組讀/存操作之目標記憶體或快取位置),並且將原先獨立在外的材質貼圖單元整合到了 SM 模組裡面 (以前是放在 TPC 中,獨立於 SM 之外) 以降低延遲 (但同時脈週期下能處理的 texels 數量則從 GT200 的 80 個降為 64 個,但由於可以動態調用且延遲降低,因此最後在總效能表現上其實還是成長的)。





