











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











犧牲面積換取節能
至於為什麼要一口氣把 CUDA Core 的數量增加到三倍呢?其實也是基於同樣的設計理念發展出來的結果,我們知道打從 Tesla 架構開始 CUDA Core (或者你想叫他 Shader 也行) 的運作時脈就比 GPU 本身還要高出許多 (至少兩倍,甚至將近三倍),這樣的設計當然有提升渲染性能的效果,但是代價也很明顯 (其實就很像 Netburst 架構中的倍速執行引擎 Rapid Execution Engine)。

拉高 CUDA Core 時脈最明顯的缺點當然就是很大程度限制了 GPU 本身運作時脈的成長,除此之外對於功耗與發熱量而言也絕對不是好事,也會提高增加 CUDA Core 數量的困難度並且造成發熱量不均的問題,因此在 Kepler 架構當中 NVIDIA 選擇捨棄過去將 CUDA Core 時脈拉高的作法,從 Kepler 開始 CUDA Core 將與 GPU 同頻運作。
不過 NVIDIA 當然不可能那麼天才直接把 CUDA Core 的時脈減半而不做其他處理 (否則 Kepler 的性能豈不是只剩下 Fermi 的一半嗎?),考慮到 Kepler 產品在製程方面有大幅的提升,所以 NVIDIA 的如意算盤便是用數量來彌補時脈下降之後的性能衰減。
然而得益於製程的提升,Kepler 在 CUDA Core 方面數量的提升量得以高達三倍,這樣高幅度的數量增長所能達成的效益其實是超過時脈減半帶來的損失的,而且 Kepler 架構 GPU 的時脈又能拉得比 Fermi 還要高一些,所以一來一往之後造就了 Kepler 在性能上還是能夠遠遠勝出 Fermi 架構產品的基礎。
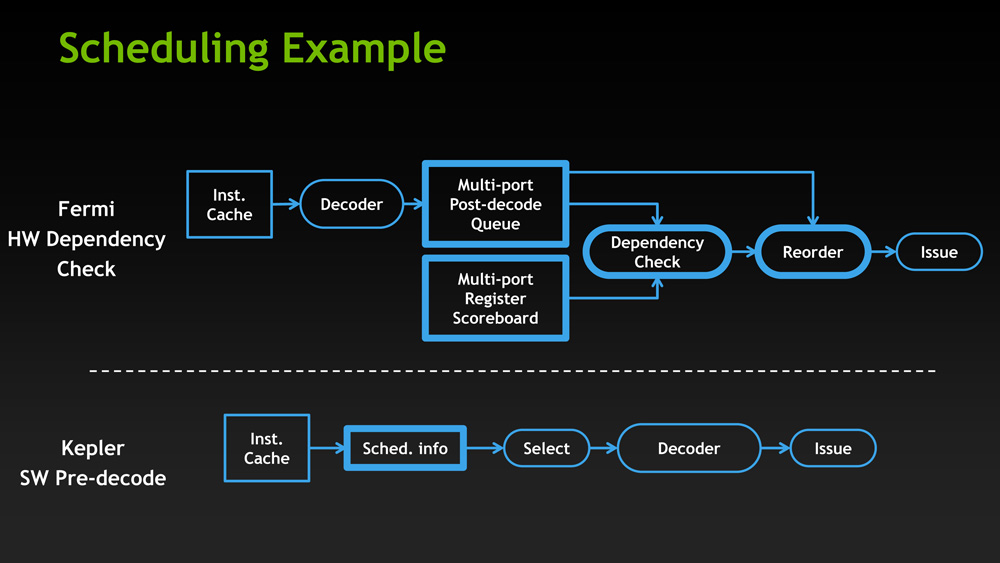
不過為了把 CUDA Core 的數量提升這麼多,其實 NVIDIA 還是做了妥協,那就是將原本相當複雜的硬體排程器電路改為大幅簡化之後的軟體排程器,從 Fermi 當中的動態排程改回傳統的靜態排程 (Static Scheduling)。
GPU Boost
接下來要談的是 Kepler 架構相較於 Fermi 與 Tesla 而言在運作機制上比較明顯的差異,也就是 GPU Boost 技術的支援。

在電腦的世界裡看到 Boost 這個字眼你會先想到甚麼?絕大多數人的回答大概都會是 Intel 的 Turbo Boost 吧,確實這兩個技術在結果上其實很類似,說穿了都是一種「動態超頻」的技術,但其實在運作方式上其實是有一些不同的。
讓我們從大家比較熟悉的 Turbo Boost 開始談起吧,基本上 CPU 的 Turbo Boost 是根據當下的負載來對 CPU 的各個核心進行動態的時脈調整,而根據工作負載是否落在特定幾個核心上而主要可分為兩種不同的情況,假設工作負載平均分配在每個核心上,那 Turbo Boost 的動作其實很單純,就只是把整個 CPU 的倍頻拉高到 Intel 預先定義的 Boost Multiplier 而已。
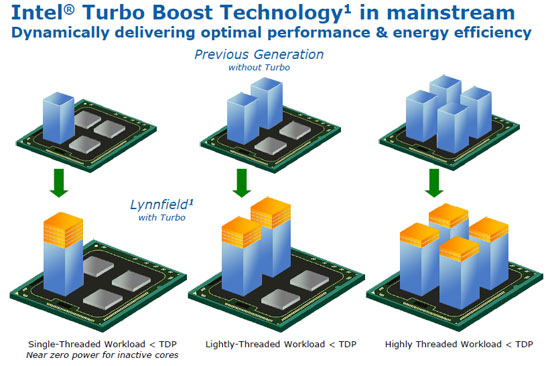
但如果負載分布不均呢?這種情況下就比較複雜一些了,我們舉最極端的例子來看,若負載只集中在單獨一個核心,那 Turbo Boost 就會將其他沒事幹的核心降頻甚至完全關閉,把供電與發熱上限集中給正忙於工作的那個核心,並把該核心的倍頻拉高到比 Boost Multiplier 還要來得更高的 Max Boost Multiplier。
然而 Turbo Boost 還是有前提的,自動超頻的作動都不能超越 Intel 給 CPU 預先設定的「熱設計功耗」(Thermal Design Power),也就是如果本身處理器的功耗已經超過 TDP 設定的數值的情況下,Turbo Boost 是無法進一步提升倍頻的 (之所以要考慮這件事情,而無法單純用最高時脈訂死的原因是在運算的內容相同的情況下,受到使用的電路單元與路徑不同、個別晶片的體質好壞差異等因素影響其實是有可能導致運算熱功耗出現一定差距的,此外,即便是在同個晶片負載百分比相同的情況下,若運算內容不同也很可能會產生一定的熱功耗差距)。
對 Turbo Boost 有一定的瞭解之後要理解 GPU Boost 就不是那麼困難了,首先我們要知道相對於 CPU 而言 GPU 有兩點很重要的不同:
- 在 CUDA Core 改為與 GPU 同時脈運作之後,CUDA Core 已經不存在 Multiplier (倍頻) 的概念。
- GPU 的 CUDA 核心數遠比 CPU 的運算核心數還要多,而且 GPU 的 CUDA Core 結構簡單,單一個體對整體性能與熱功耗的影響很有限,因此控制單個 CUDA Core 的運作時脈不論是動態超頻或動態降頻其實都是不切實際的事情。
因為這兩點不同所以我們可以知道 GPU Boost 控制的肯定不是倍頻也不是單一 CUDA Core 的運作時脈,而是「整個 GPU」的運作時脈,而且與 Turbo Boost 不同,GPU Boost 並沒有「預先定義 Turbo 時脈」這樣的概念存在。
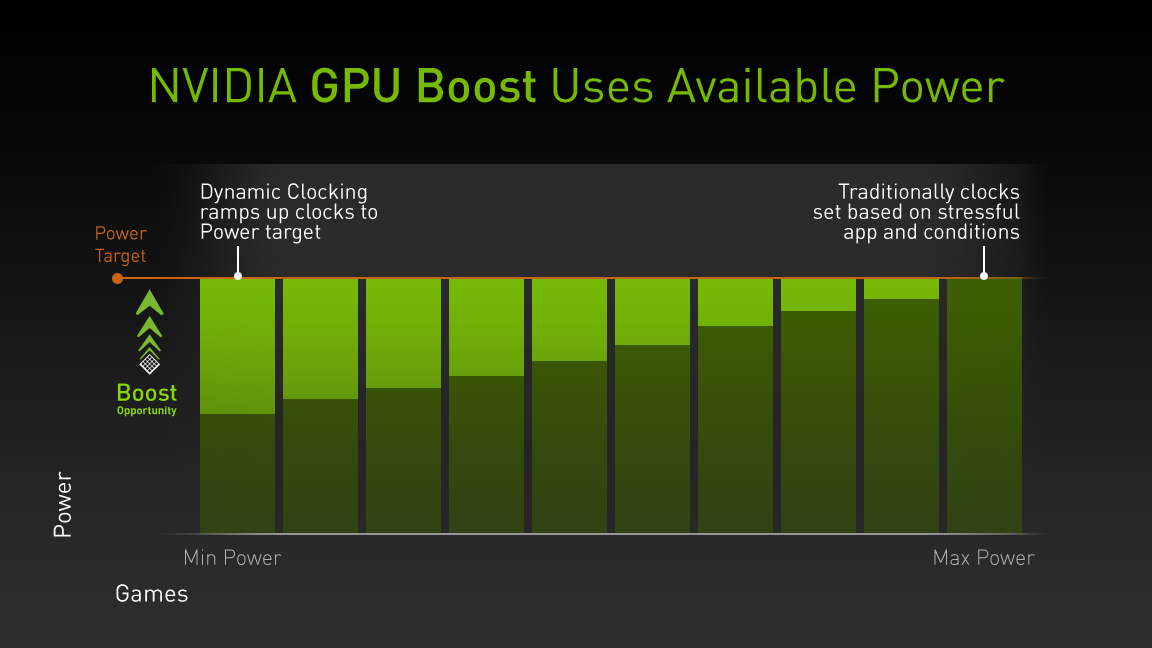
既然如此,那 GPU Boost 的超頻依據到底是甚麼呢?其實很類似剛剛討論 Turbo Boost 時提到的熱設計功耗,主要的差別是 GPU 看的是「耗電量」而不是「發熱量」,在這裡 NVIDIA 把它稱為 Power Target (白話就是 GPU 本身設計所能容許的最高耗電量限制),因此將整個 GPU Boost 技術歸納成一句話其實就是「在 GPU 本身還沒達到 Power Target 的情況下,系統可以自動動態提升 GPU 的運作時脈直到耗電量撞到 Power Target 這天花板為止」。
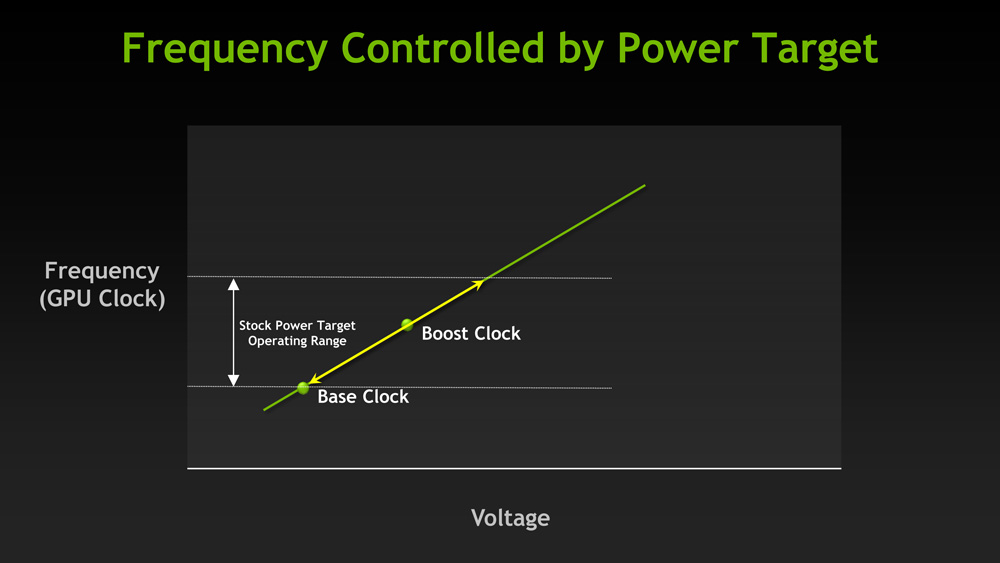
然而剛剛提到的「在運算的內容相同的情況下,受到使用的電路單元與路徑不同、個別晶片的體質好壞差異等因素影響,有可能導致運算功耗、耗電量出現一定差距」也適用於 GPU 上,所以實際上每張相同的顯示卡雖然在 NVIDIA 方面設定的預設 Power Target 都相同 (除非板卡廠有特別調整),但跑相同的負載時能夠動態調升的時脈多寡其實會受到晶片體質影響,因此是無法像以前那樣簡單從設定參數預測實際運作時脈的 (基本上你只能確定運作時脈會比 NVIDIA 設定的基礎時脈 Base Clock 來的高而已)。
然而由於決定運作時脈的方式改變,所以從 Kepler 開始 NVIDIA GPU 的超頻方式也比起以前有很大的不同,基本上已經不能像之前那樣直接指定目標時脈,而是得透過調整 Power Target 的位置來允許 GPU 本身動態超頻直到在更高的耗電量下運作為主、直接設定時脈位差 (Offset) 為輔兩種方式來進行超頻。





