











![[CES 2019 速報] AMD 預覽下一代 “Zen 2” 處理器,可望成為本屆 CES 最大看點](https://isite.tw/wp-content/uploads/2019/01/AED8012-360x180.jpg)









![[教學] 使用 XperiFirm 製作 Xperia 手機原廠軟體 FTF 安裝包](https://isite.tw/wp-content/uploads/2016/04/XFX0001-360x180.png)















![[ 突發 ] Mega 創辦人呼籲大眾盡速備份 Mega 上的資料?! (附官方澄清)](https://isite.tw/wp-content/uploads/2016/04/AMU8563-360x180.jpg)











一開始 NVIDIA 給的規格表是表示 GTX 970 並沒有刪減 ROP 與 L2 快取,而且當時 NVIDIA 並沒有針對 GTX 970 提出符合的配置圖 (你所能找到的 GM204 配置圖都是 GTX 980 的),又加上 GTX 970 也配了 4 GB 的記憶體,而且以往要砍 ROP、記憶體控制器與 L2 快取時這兩邊會有連動關係,所以大家預期 GTX 970 與 GTX 980 在記憶體階層的部分應該是一模一樣的。
不過後來陸續有用戶在使用 GTX 970 時發現,當執行大量消耗顯示卡記憶體的工作時,GTX 970 只能使用約 3.5 GB 的記憶體,後來陸續執行測試軟體也發現特意只存取最後 512 MB 記憶體時的記憶體頻寬大約只有 GTX 980 的 1/7 (其他部分也只有 GTX 980 的 7/8),並把結果貼上網路之後才引爆了整個討論。
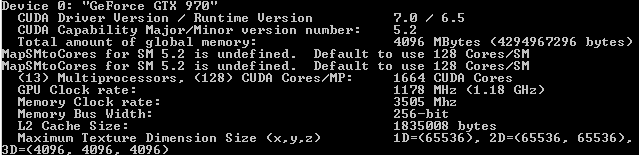
眼看事情越演越烈,最後 NVIDIA 不得不回應表示它們提供給媒體的規格表出了一點差錯,實際上 GTX 970 的 L2 快取只有 1.75 MB,ROP 也只有 56 組,這一切其實是肇因於 Maxwell 架構當中引入的一項新特性,使得 NVIDIA 得以「部分關閉」ROP 與記憶體控制器分區 (GM204 有四個 ROP 與記憶體控制器分區,對應到四個 GPC,而 GTX 970 上有「半組」被關閉了),而不再像以前只能成對關閉。
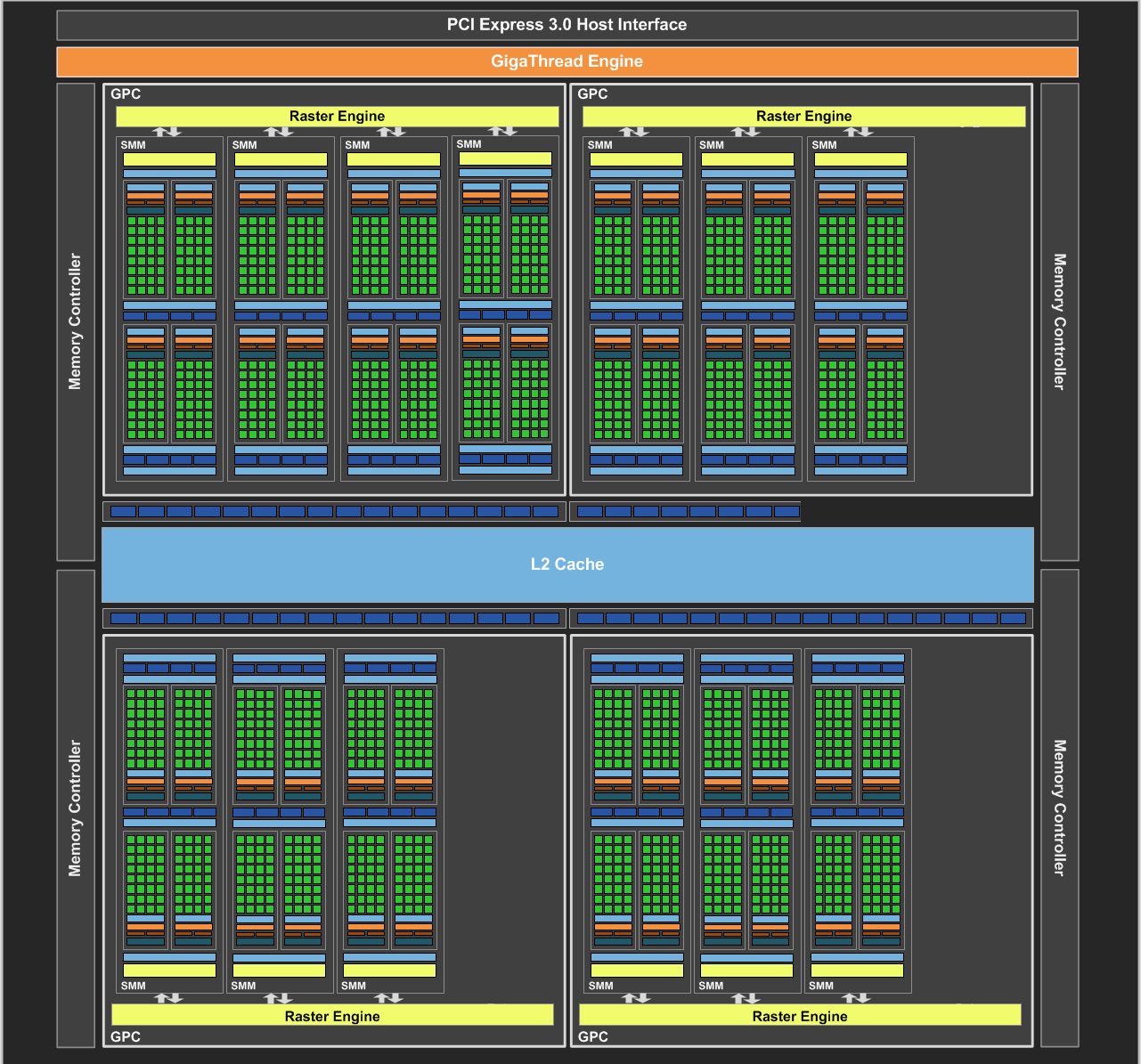
這解釋了為什麼 GTX 970 會出現這種奇怪的現象,其實和當年 GTX 660 與 GTX 660 Ti 的狀況很相似,這問題是肇因於 ROP 與記憶體控制器之間數量上沒有完全平衡對應的結果,導致記憶體被迫分割為兩塊 (以 GTX 970 的情況來說就是 3.5 GB + 0.5 GB),而且這兩塊不能同時存取,至於詳細的情況,使用下面這張圖說明會比較易懂。
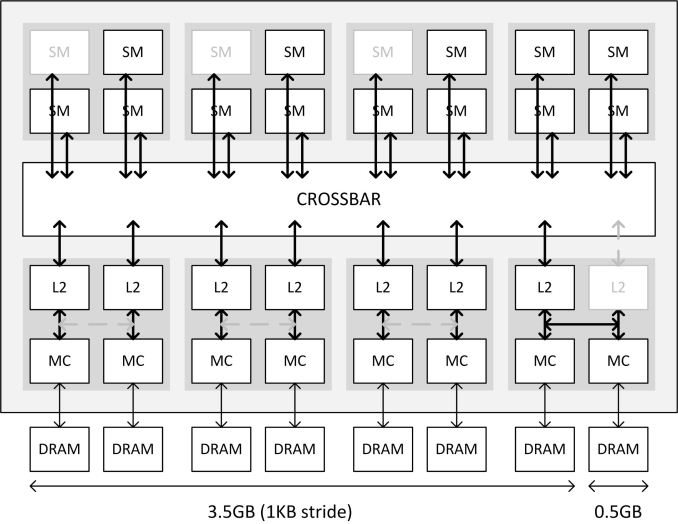
從上圖中我們可以看到四組 GPC (其中每個 GPC 當中有四個 SMM,但有部分被屏蔽)、四個 L2 快取 (ROP 包含在其中) 與記憶體控制器分區以及和 L2 快取與記憶體控制器分區相連的記憶體晶片們,在 Maxwell 架構以前,NVIDIA 若想縮減記憶體控制器的佈局,就得一次砍掉一個 (或是半個,但應該是沒發生過) L2 快取與記憶體控制器分區。
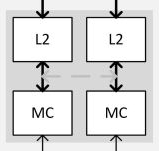
但在 Maxwell 架構當中 NVIDIA 在 L2 快取與記憶體控制器內的兩組記憶體控制器與兩塊 L2 快取分區中間新增了一條備用連線 (也就是上圖中間虛線的地方),這使得部分屏蔽 L2 快取與記憶體控制器分區成為可能 (這四小塊當中有一塊斷掉還可以透過中間的備用連線來維持其他三塊正常運作),但是問題就來了,這代表 L2 快取與記憶體控制器與中央匯流排 (Crossbar) 之間最多只有 7 個 32-bit 寬的通道可用 (其中一個隨著一塊 L2 與 ROP 區塊被滅而失效了),而且若要達成多通道記憶體使頻寬倍增的效果得要所有記憶體通道同步且連貫才行,這就是為什麼前面 3.5 GB 的部分最高速度只有 GTX 980 的 7/8 的原因。
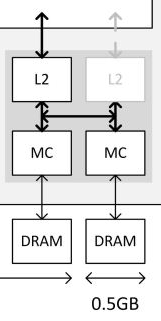
而使用備用連線的這組 L2 快取與記憶體控制器分區當中出現的情況是兩個記憶體控制器可能得共用一個 Crossbar 入口,然而這種情況當然是不被允許的,因此最多只能擇一使用,加上剛剛提到要達成多通道記憶體使頻寬倍增的效果得要所有記憶體通道同步且連貫才行,所以勢必只能分成七個連貫與單獨一個兩種情況,這就是為什麼前面 3.5 GB (7/8 容量,連接於前七個記憶體控制器) 可以有 GTX 980 的 7/8 頻寬、後面 512 MB (1/8 容量,連接於最後一個記憶體控制器) 只能有 GTX 980 的 1/8 的原因。
GM200 核心
接下來要介紹的就是 Maxwell 架構的完整版大核心-GM200 了,從命名上可以得知 GM200 的特色與剛剛介紹的 GM204 相去不遠,基本上就是規模擴大很多的 GM204。
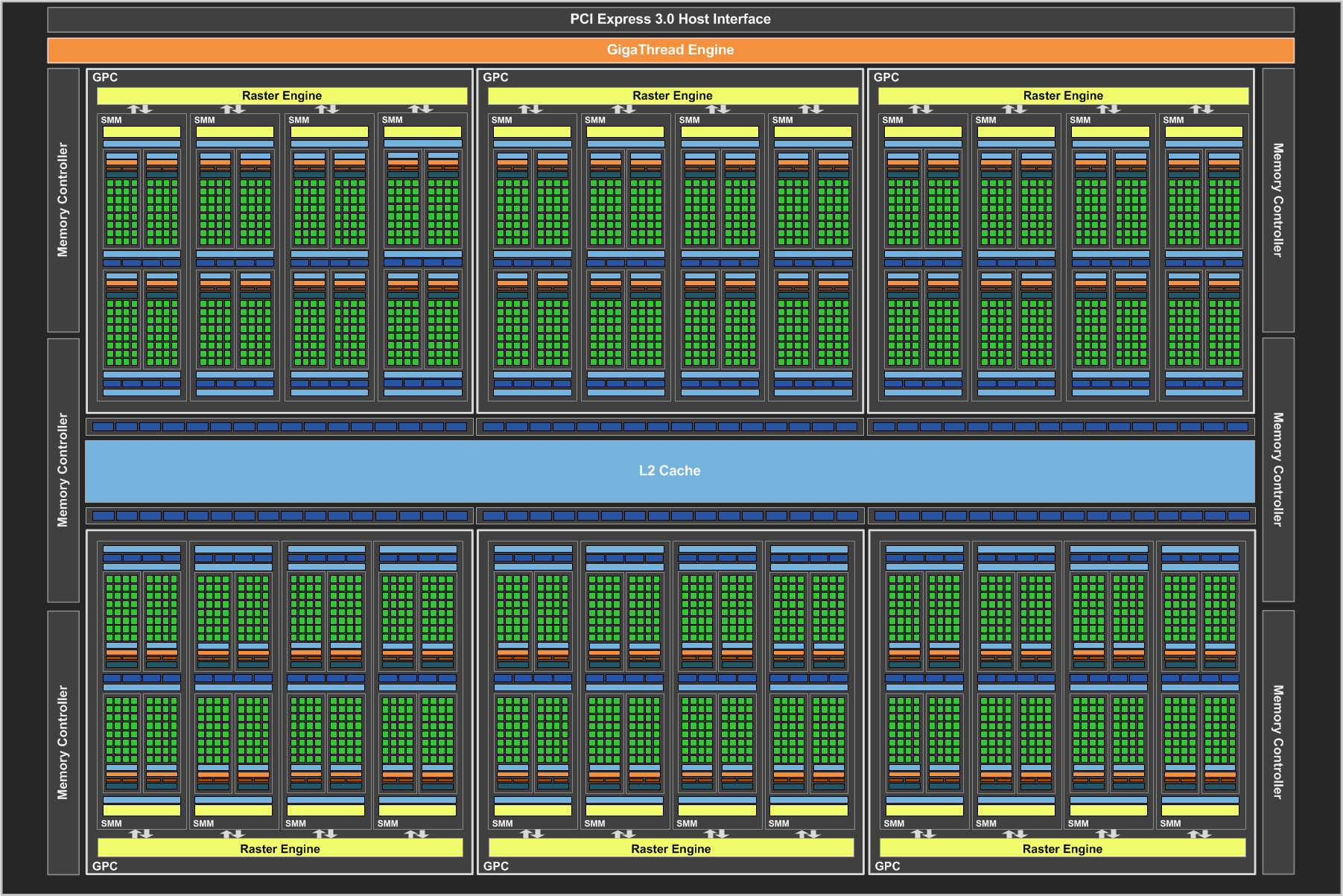
相較於 GM204 而言,GM200 進一步將 GPC 的數量從 4 組提高到 6 組,這意味著 SMM 也跟著多了 4 組 (所以 GM200 有高達 3,072 個 CUDA Core),至於電路規模的部分,GM200 所包含的電晶體數高達 80 億,面積更是高達 601 平方公分,是歷來 NVIDIA 晶片之最。





